

什麼是不均衡數據:


圖 1 數據不平衡
不均衡數據的形式很簡單,這裡有蘋果和梨,當你發現你手中的數據對你說,幾乎全世界的人都只吃梨,如果隨便抓一個路人甲,讓你猜他吃蘋果還是梨,正常人都會猜測梨。
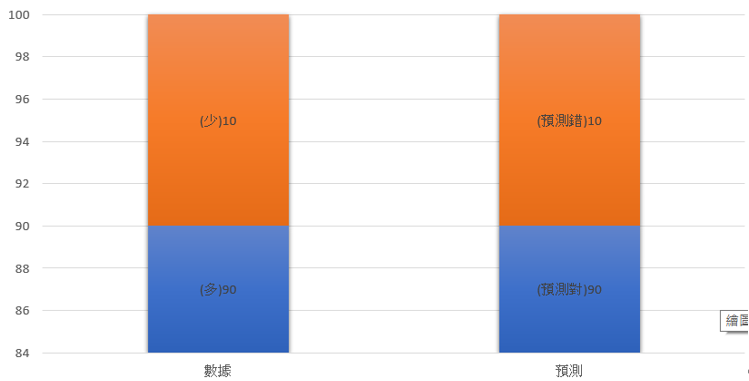
圖2 數據表
不均衡的數據預測起來很簡單,永遠都猜多的那一方面準沒錯,特別是藍色多的那一方佔了90%。只需要每一次預測的時候都猜藍色,預測準確率就已經達到了相當高的90%了。沒錯,機器也懂這個小伎倆,所以機器學到最後,每次都預測多數派,解決的方法有幾種。
方法1:獲取更多數據:
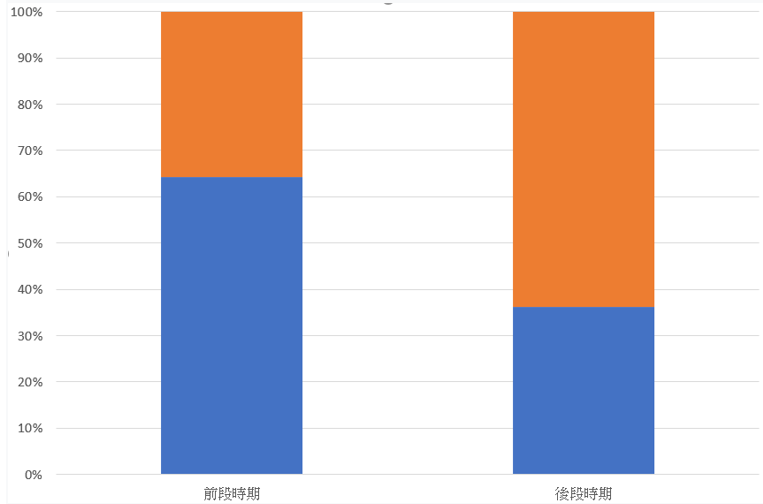
圖3 獲取更多數據
首先,還能不能獲取到更多的數據,有時候只是因為前段時期的數據多半呈現的是一種趨勢,等到後半時期趨勢又不一樣了。如果沒有獲取後半時期的數據,整體的預測可能就沒有那麼準確了。
方法2:更換判斷方式

圖4 更換判斷方式
通常,我們會用到準確率accuracy,或者誤差cost來判斷機器學習的成果。 可是這些判斷方法在不均衡數據面前,高的準確率和低的誤差變得沒那麼重要。所以我們得換一種方式判斷,通過confusion matrix 來計算precision 和recall,然後通過precision 和recall 再計算f1 分數。這種方式能成功地區分不均衡數據,給出更好的評判分數,因為時間關係,具體的計算不過程就不會在這裡提及。
方法3: 重組數據: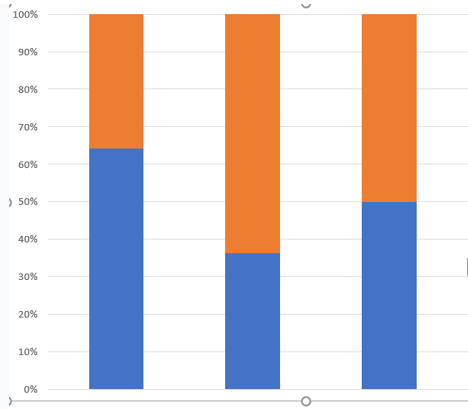
圖5 重組數據
第三種方法是最簡單粗暴的方法之一,重新組合不均衡數據,使之均衡。方式一: 複製或者合成少數部分的樣本,使之和多數部分差不多數量。方式二: 砍掉一些多數部分,使兩者數量差不多。
方法4: 使用其他機器學習方式
如果使用的機器學習方法像神經網絡等,在面對不均衡數據時,通常是束手無策。不過有些機器學習方法,像決策樹、decision trees 就不會受到不均很數據的影響。
方法5: 修改算法:
如果用的是Sigmoid 的激勵函數、activation function,他會有一個預測門檻,一般如果輸出結果落在門檻的這一段,預測結果為梨,如果落在那一段預測結果為蘋果,不過因為現在的梨是多數派。我們得調整一下門檻的位置,使得門檻偏向蘋果這邊,只有很自信的時候,模型才會預測這是蘋果。讓機器學習,學習到更好的效果。
解決數據不平衡問題的方法有很多,上面只是一些最常用的方法,而最常用的方法也有這麼多種,嘗試不同的技術和模型來評估哪些方法最有效。
評論