

前言
使用AI模型進行物件偵測前,都需要大量的資料集進行訓練才能達到一定的準確度,而資料集都必須經過前處理才能提供AI模型使用,也就是照片加上物件的位置及物件的名稱。前處理過的資料集除了從Open Source可以找到之外,其他特殊或Open Source未提供的資料集則必須自己手動蒐集及標註,而 LabelImg 就是用來標註照片中物體位置與名稱的工具,本篇博文將教大家如何在Ubuntu18.04上使用LabelImg工具完成圖片標註。
目的
透過本篇博文教大家如何使用LabelImg工具標註圖片上特定目標區域,用來建立訓練模型的資料集。
安裝LabelImg
- LabelImg 支援 Windows、Linux 與 Mac OS X 平台,而Linux Ubuntu上可以直接使用pip install labelImg下載。(圖1)
(Github:https://github.com/tzutalin/labelImg)
圖 1
- 安裝完畢後即可執行labelImg。(圖2、3)
圖 2

圖 3
標註照片
- 開啟 LabelImg 之後,有兩種方式可以開啟圖檔,第一:選擇「Open」開啟單張圖檔,第二:選擇「Open Dir」開啟目錄中所有的圖檔。如果選擇「Open Dir」則可以使用「Next Image」與「Prev Image」來選擇下一張或前一張圖片。(圖4)
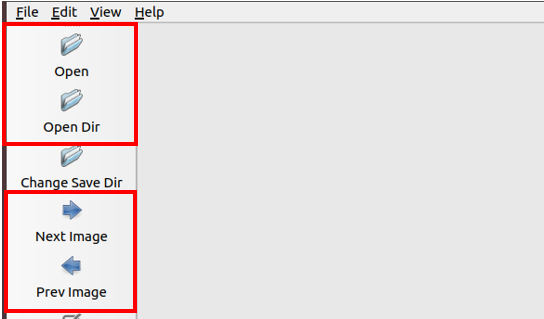
圖 4
- 選擇PascalVOC格式,這邊選擇PascalVOC原因是Caffe模型可以直接使用,不須經過其他程式轉換。LabelImg提供Yolo、CreateML與PascalVOC格式給使用者做選擇應用在不同訓練模型上。(圖5) (以下車輛圖片來源:https://github.com/AvLab-CV/AOLP)
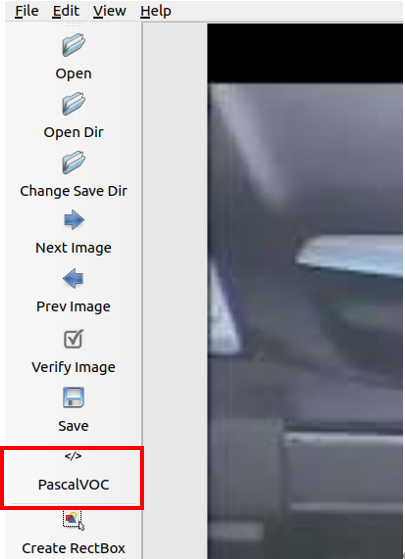
圖 5
- 將圖檔匯入LabelImg後點選右鍵選擇「Create RectBox」。(圖6)
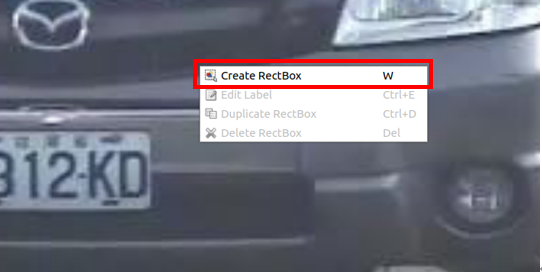
圖 6
- 框選所要標註之區域後給定區域名稱按下”ok”。(圖7)
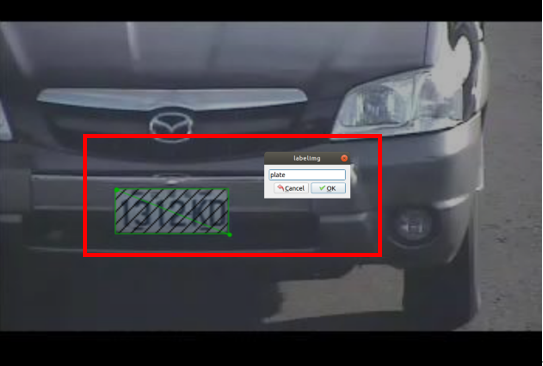
圖 7
- 按完ok後即會顯示所標註之區域。(圖8)

圖 8
- 按下Save進行存檔即完成標註動作。(圖9)
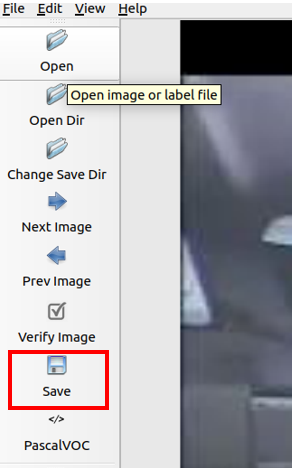
圖 9
- LabelImg 儲存的 XML 內容大概會長這樣。(圖10)
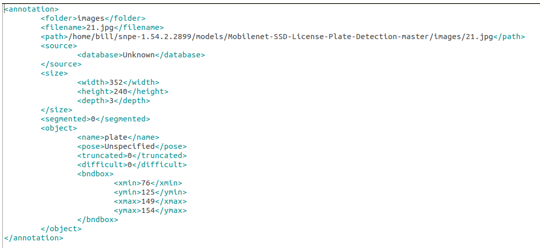
圖 10
- 將儲存XML檔案命名為Annotations,並將原本儲存照片的檔案夾命名為JPEGImages即可用來進行Caffe模型的訓練,這邊須注意 Annotations 與 JPEGImages 檔案夾內之檔案是否有對應上。
(圖11、12、13)
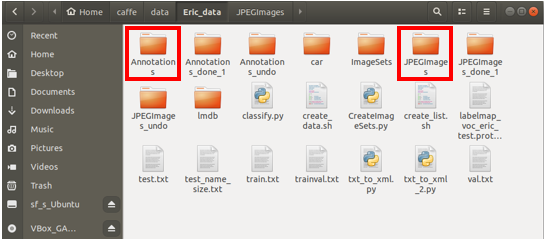
圖 11
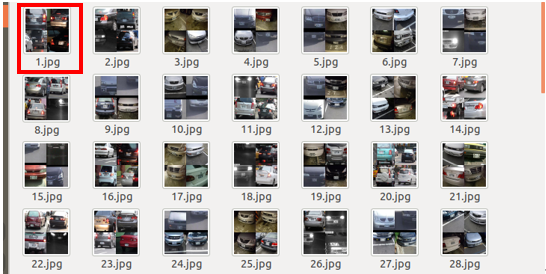
圖 12

圖 13
結語
AI模型訓練中最重要的就是資料集的前處理,雖然網路上已有許多Open Source能夠使用,但在許多形況下模型資料集需要自己建立,因此學習完整的AI訓練流程才能因應不同的使用狀況。
評論