

- 前言
在當今的物聯網時代,語音辨識技術的應用日益廣泛。本文將介紹如何部署TinyML語音辨識系統,並詳細記錄從資料收集到模型部署的過程。
- TinyML快速入門:使用Zilltek 麥克風實現TinyML語音辨識

TinyML語音辨識在開發板上的部署 TinyML的實作始於資料的收集。在這一階段,我們選擇了speech_commands資料集進行模型訓練。該資料集包含多個語音指令類別,如"down", "go", "left", "no", "right", "stop", "up", "yes"等,可在Tensorflow官方GitHub中找到。
開發環境方面,我們使用Tensorflow2.10和python3.10進行開發,硬體方面則選用了esp32s3-c1。麥克風使用Zilltek ZTS6672 mems mic,IDF使用ESP-IDF,建置project輸入指令:
idf.py create-project-from-example "esp-tflite-micro:micro_speech"
會得到esp-tflite-micro的檔案
我們使用example中的micro_speech,內容我們需要做一些修改,首先在audio_provider.cc中對i2s輸入做一些設定。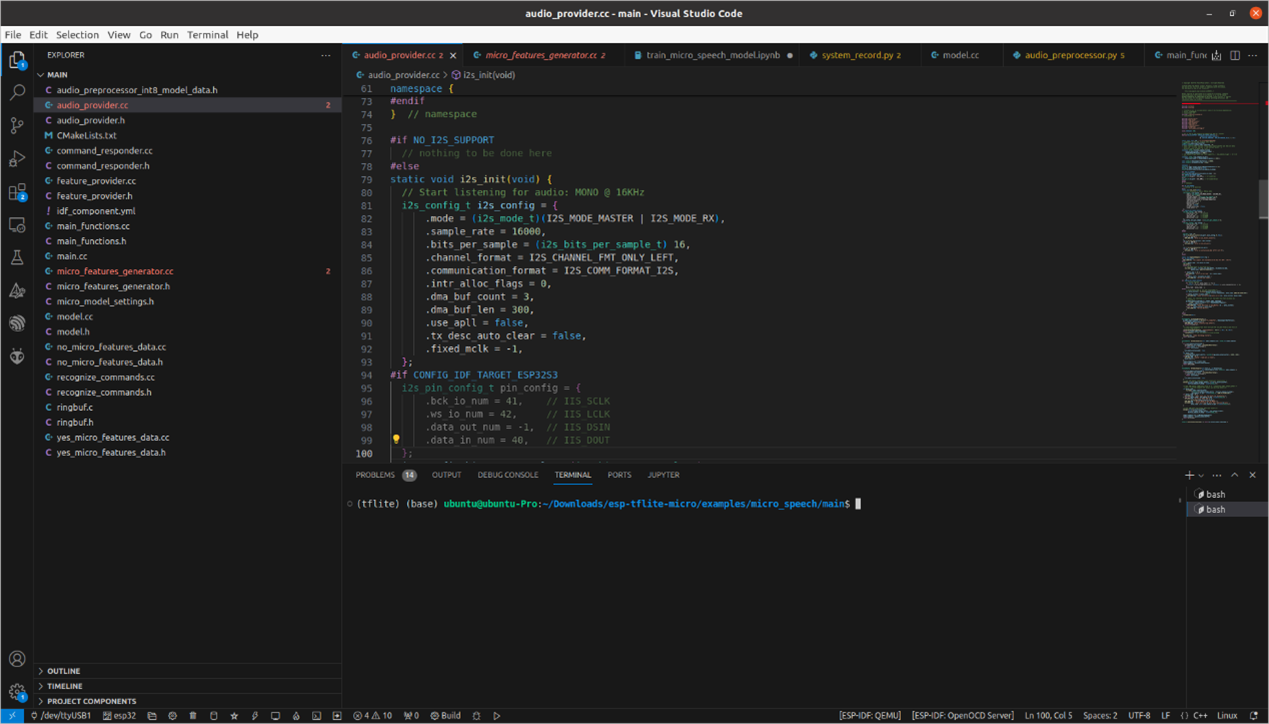
另外模型經過訓練量化並轉成.tflite之後,我們需要將模型轉換成二進制,在model.cc中將自己的模型放進去,同時修改g_model_len以匹配模型大小。
在micro_model_settings.h中,根據模型訓練時的關鍵詞設定label。例如,若有6個分類,則`constexpr int kCategoryCount`應設為6,並將要辨識的label放入`constexpr const char* kCategoryLabels[kCategoryCount]`中。
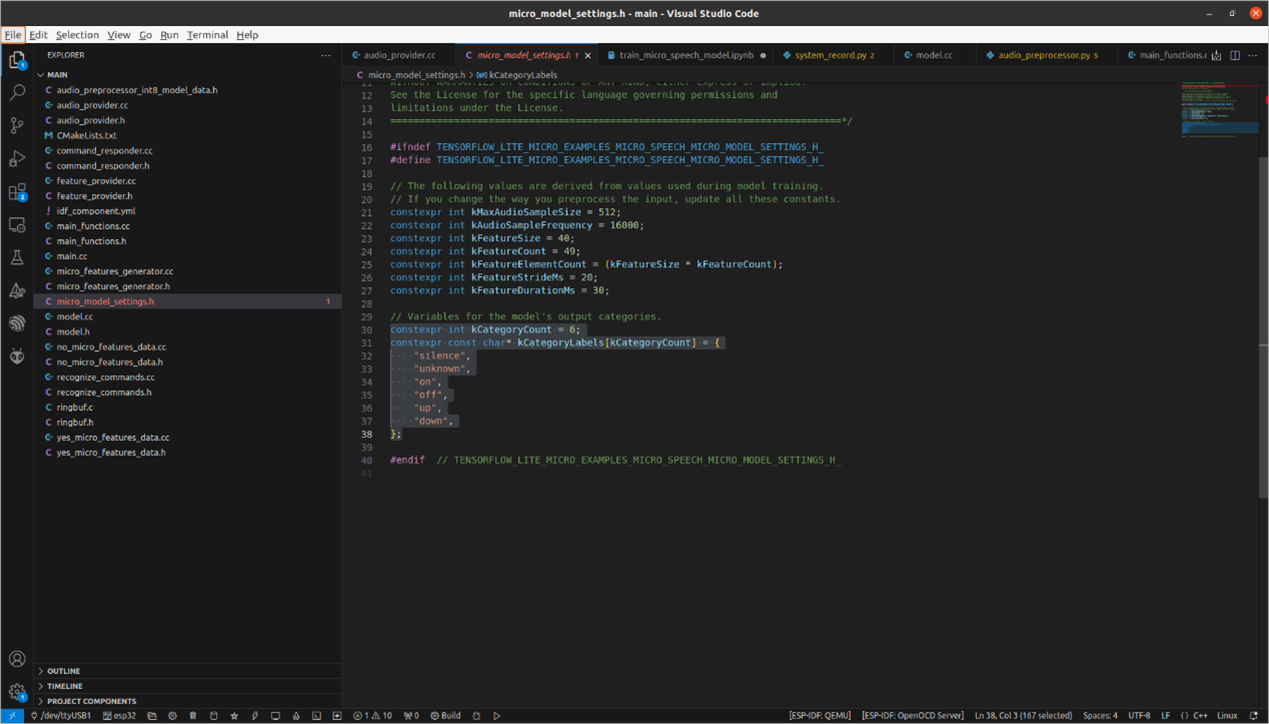
此外,若想添加語音辨識連動功能,如聽到關鍵詞便開燈等操作,在main_function.cc中進行添加即可。只要confidence值高於0.8,就會執行相應指令。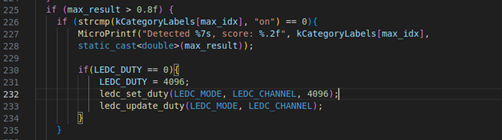
當一切都完成之後就可以進行build的工作,使用ESP-IDF進行,依序輸入以下指令:
idf.py set-target esp32s3
idf.py build
idf.py -p /dev/ttyACM0 flash
idf.py -p /dev/ttyACM0 monitor
就可以看到辨識的部分
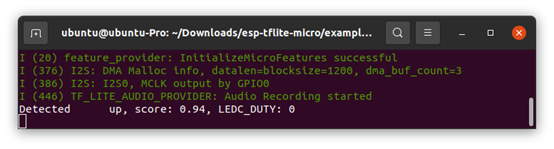
- 結語
本文記錄了筆者在esp32s3-c1上實作TinyML語音辨識的過程。從資料收集到部署實作,每一步都是寶貴的學習經驗。希望本文能對同樣對TinyML有興趣的讀者有所幫助。
- Q&A
- Q:如果辨識不準確,該從哪裡下手檢查問題?
A:造成辨識不準確有很多可能,可以從麥克風、模型去看。
- Q:麥克風要怎麼檢查?
A:要確認收音沒問題,可以使用UDP傳送PCM給電腦,在使用Pyaudio 將音訊播出來聆聽是否有問題。
- Q:如何確認模型是否準確?
A:從Tensorflow提供的tflite-micro中在tensorflow/lite/micro/examples/micro_speech中有提供evaluate.py,可以餵入wav查看是否準確。
- Q: 如果在build時遇到Didn't find op for builtin opcode 'CONV_2D' version '3'. An older version of this builtin might be supported. Are you using an old TFLite binary with a newer model?
Failed to get registration from op code CONV_2D該怎麼解決?
A: main_function.cc檢查op是否與模型符合,可以去netron看模型結構。
- Q:在執行py時遇到FLATBUFFERS_ASSERT(size < FLATBUFFERS_MAX_BUFFER_SIZE);相關問題如何解決?
A: /Documents/tflite-micro/tensorflow/lite/micro/build_def.bzl的def micro_copts():中加入 "-Wno-error=sign-compare",,執行時使用bazel build --copt="-Wno-error" evaluate來忽略比較錯誤便可正常執行。
- 引用
評論