

本篇將講解目前最新推出的YOLOv9搭配Roboflow進行自定義資料標註訓練流程,透過Colab上進行實作說明,使大家能夠容易的了解YOLOv9的使用。
►YOLO框架下載與導入


►Roboflow的資料收集與標註
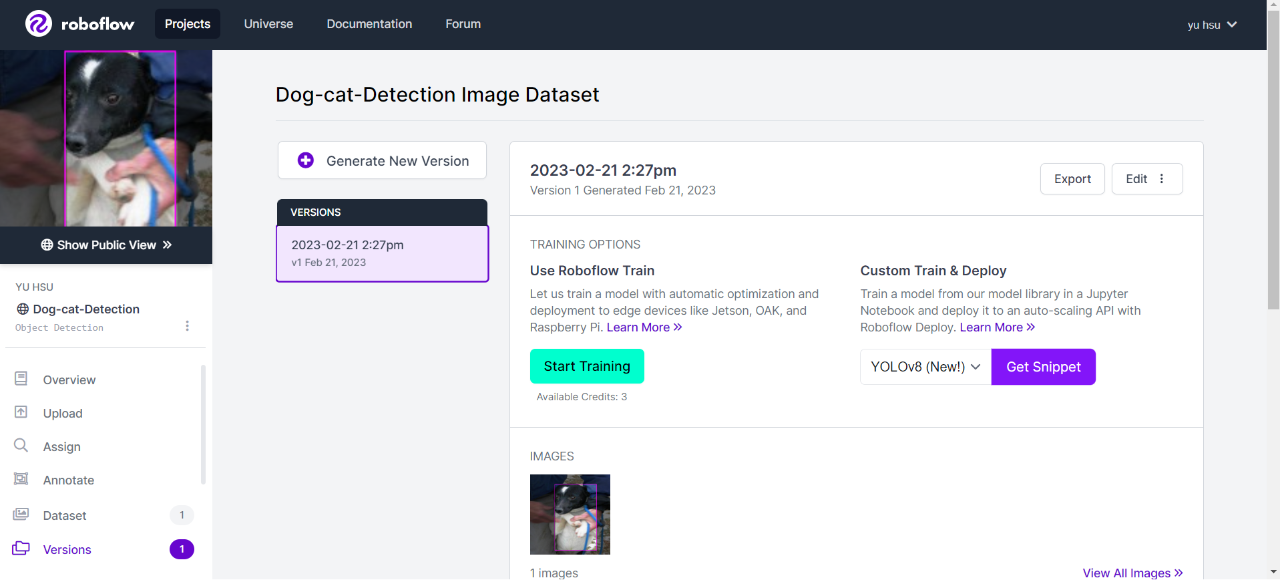
進入Roboflow官網,點選右上Sign up註冊自己的帳號,並進行登入。登入後,網站會引導進行workspace建置,名稱與選項部分依照自身情況進行填寫。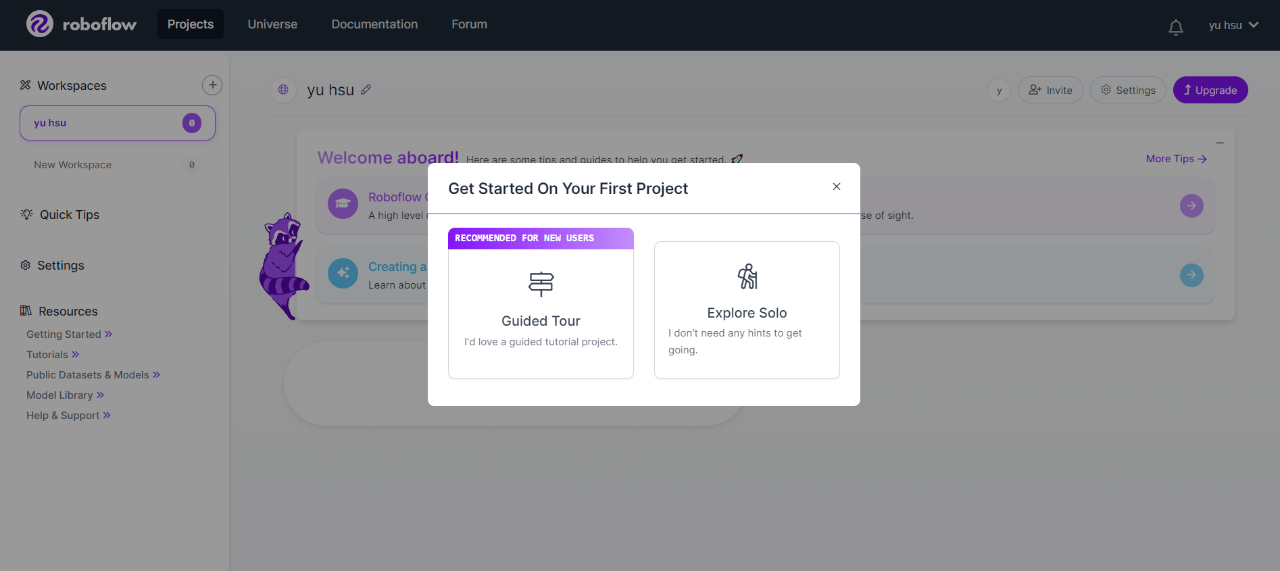
進行自定義資料集建置與上傳
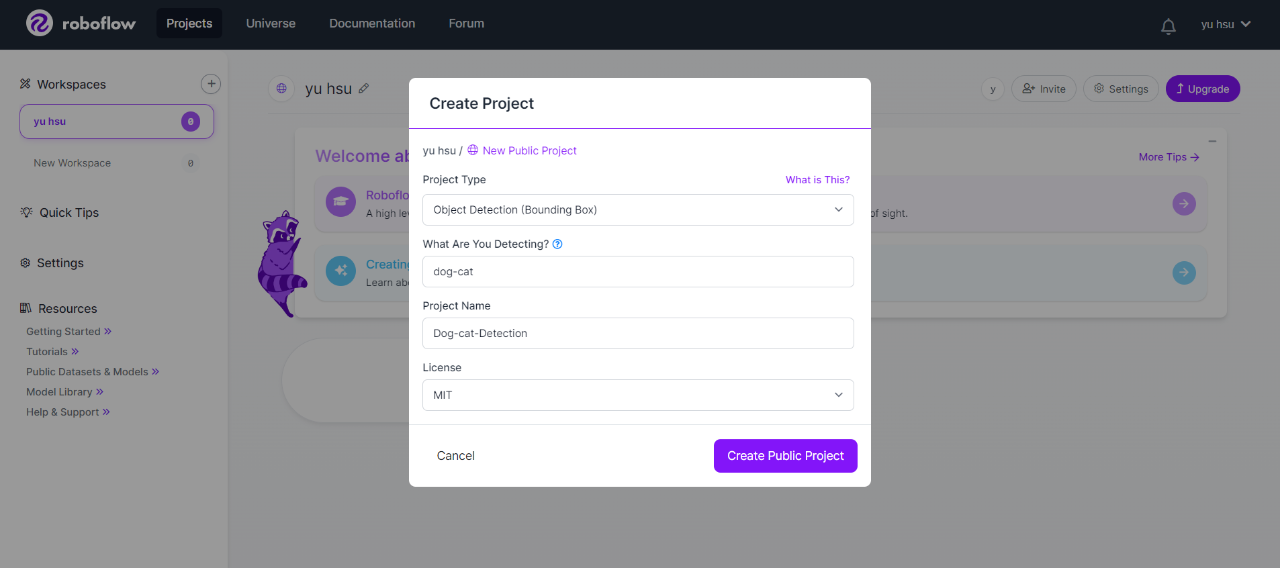
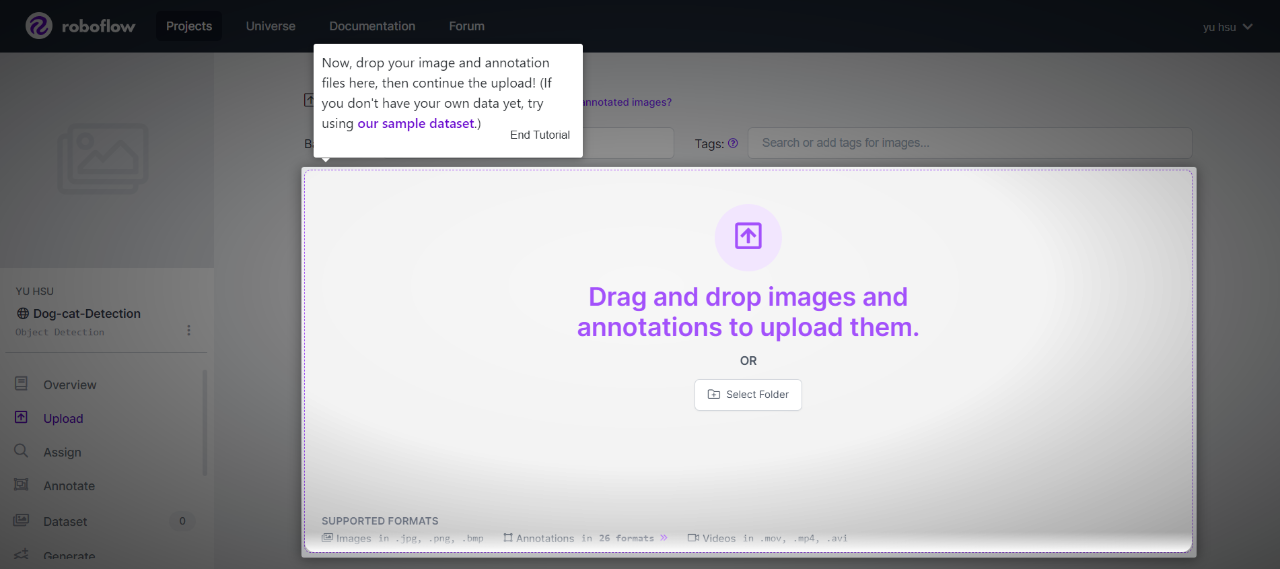
透過Roboflow工具進行資料標註,最後再將訓練資料採用YOLOv9格式輸出。
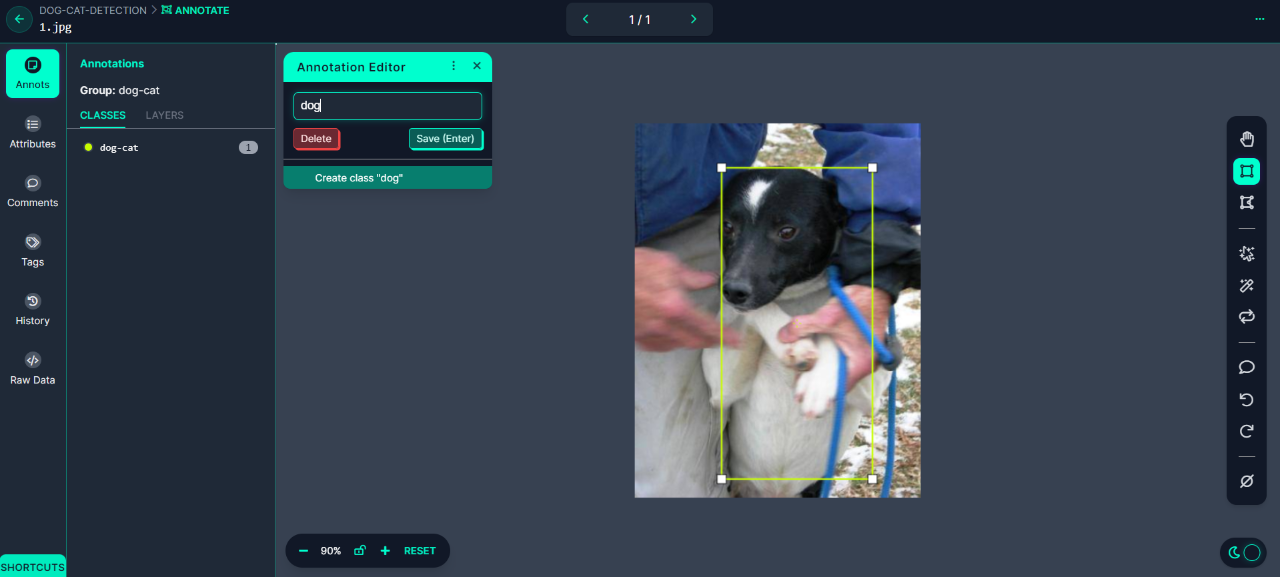
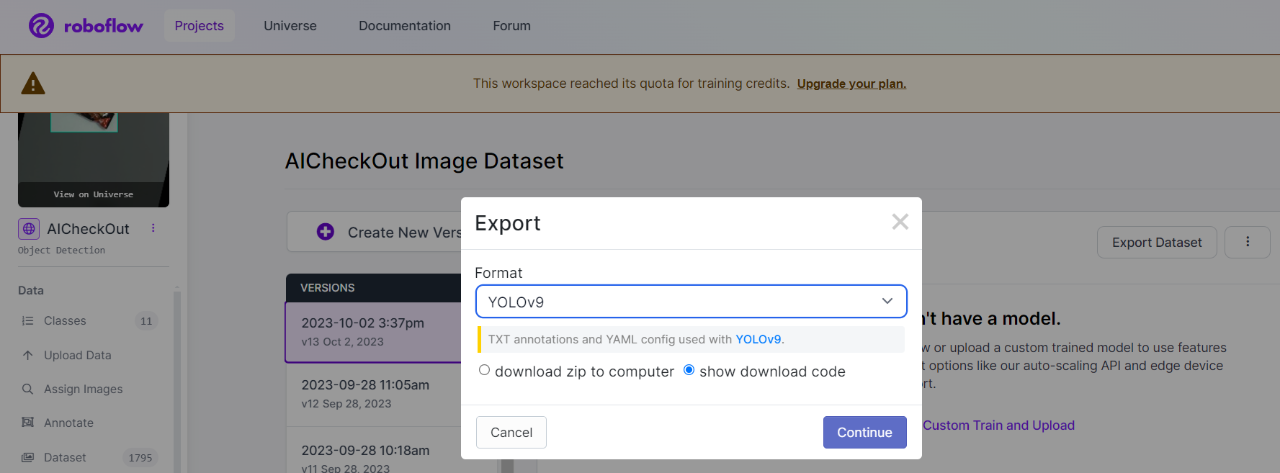
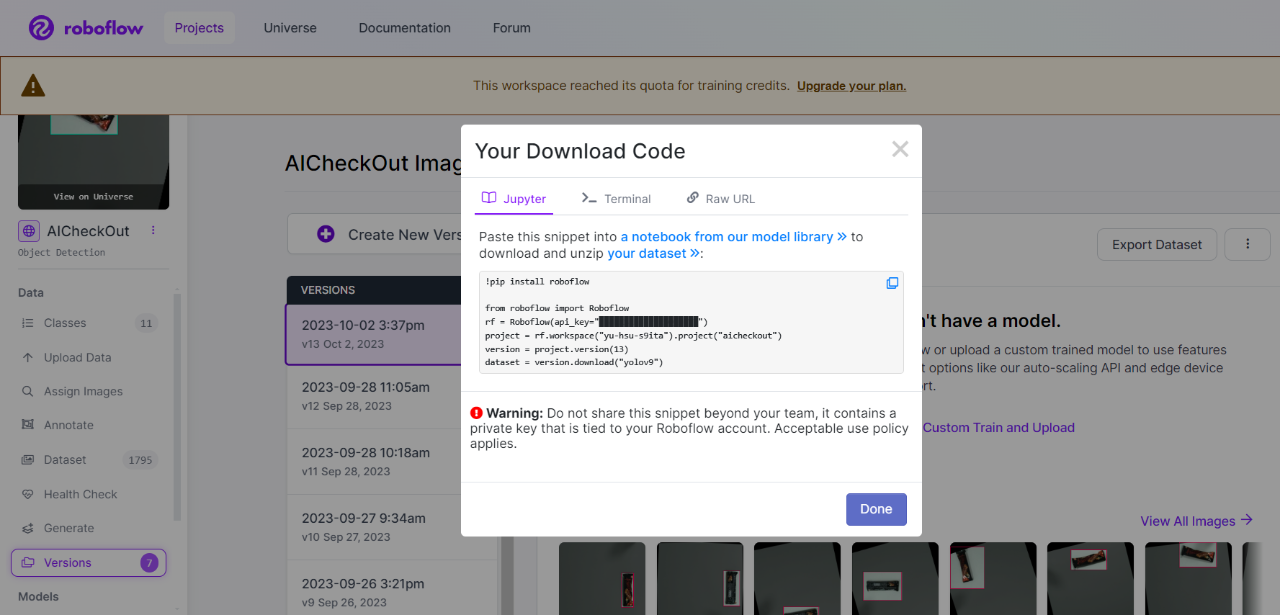
►自定義資料導入
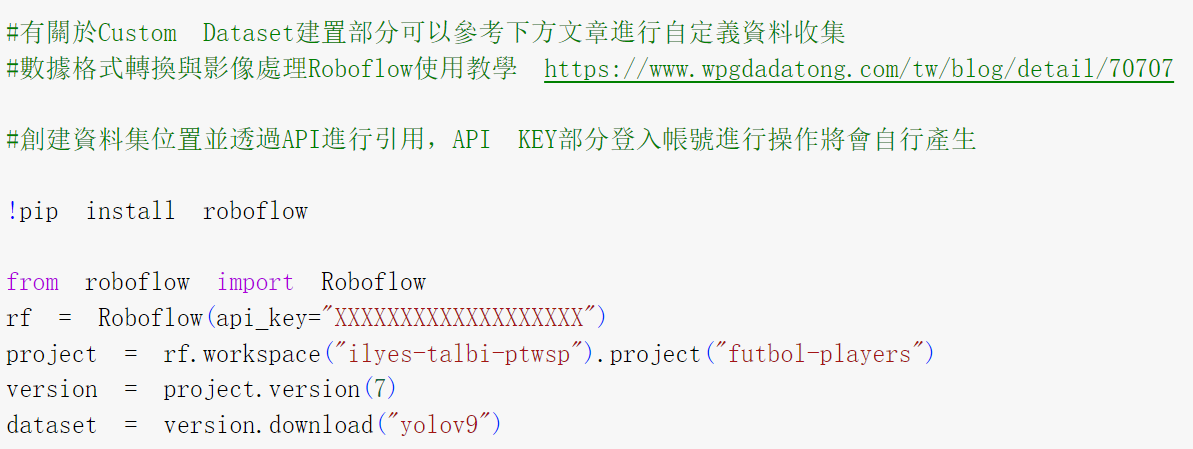
►模型訓練

►模型訓練confusion matrix可視化

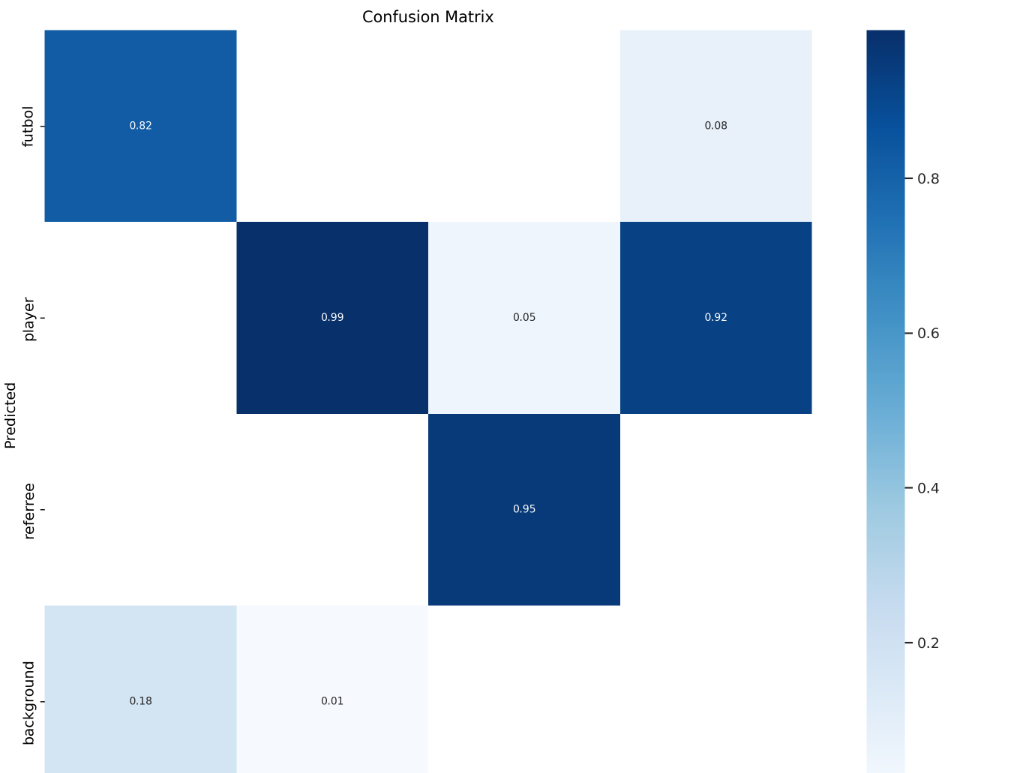
►模型訓練結果可視化
►小結
透過以上講解,在Colab上搭配Roboflow進行自定義資料收集與訓練,能夠更快的進行YOLOv9的模型訓練,可以期待下一篇博文吧!
►Q&A
問題一: YOLOv9 如何解決訊息瓶頸問題:
YOLOv9引入了即時梯度資訊(PGI),透過輔助監督框架,用於生成可靠的梯度信息,便於在訓練過程中通過權重更新。PGI輔助可逆分支來解決深度網絡漸變導致的問題。
問題二:YOLOv9 batchsize設置:
批量大小是另一個重要的參數,它會影響模型的收斂速度和泛化性能。一般來說,較大的批量大小可以加速訓練過程,但可能會導致模型的泛化性能下降。您可以通過試驗不同的批量大小,觀察訓練和驗證損失函數的變化情況,來找到最適合的批量大小。
問題三:YOLOv9 的正則化參數設置?
正則化參數用於控制模型的複雜度,防止過擬合。通常情況下,您可以開始使用較小的正則化參數,然後逐步增加它們的值,直到訓練損失和驗證損失之間的平衡。
問題四: YOLOv9 是否能夠於嵌入端使用?
問題五:NCNN與tensorRT差異?
NCNN針對CPU效能進行部署與最佳化,記憶體佔用率低,提供INT8量化支援。TensorRT針對GPU和CPU優化加速模型推理,支援INT8量化和FP16量化。對於嵌入端提供Nvidia GPU可以透過TensorRT進行加速。
►參考資料
評論