

高通CPE的方案推薦使用的是 IPQ8074 或者 IPQ5018 + Thundercom的SDX55模組,基於成本考量,客戶會改用其他的5G模組。例如,同樣使用SDX55的Quectel 5G 模組。但是卻時常會碰到throughput比較低的問題。 日前客戶的IPQ6018的案子也碰到了類似的問題。
問題描述:
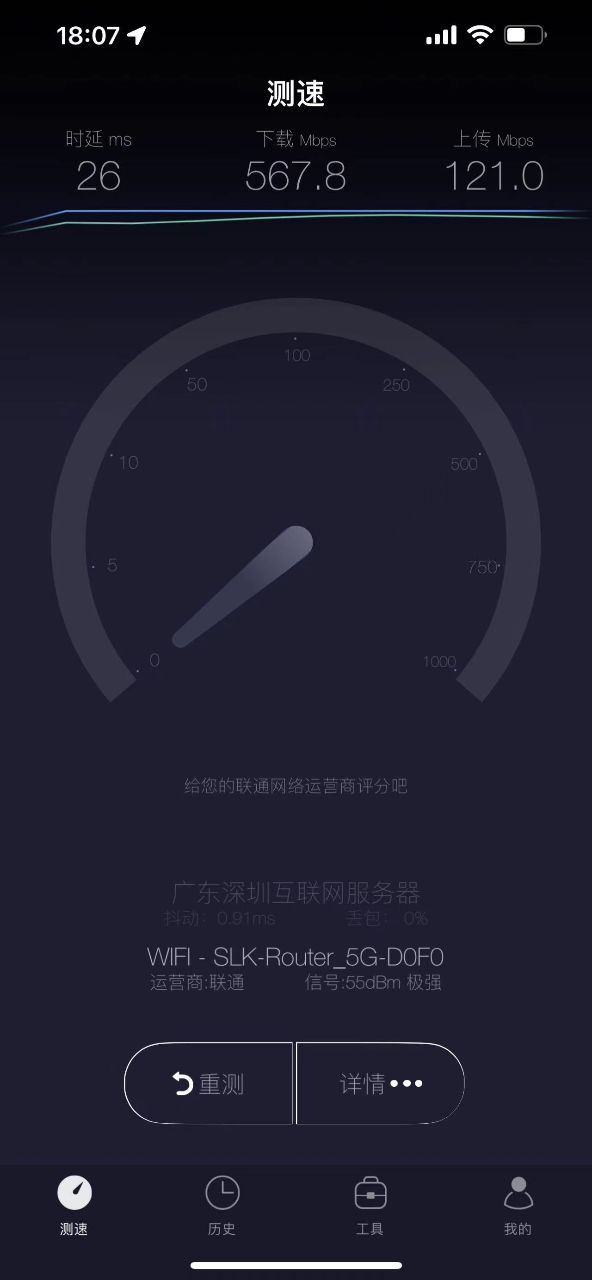
CPE 測試的結果只有560Mbps 左右。 直接使用手機測試,可以達到700~900Mbps。明顯少了200Mbps的速度。
修改方法: 更改smp_affinity的配置。
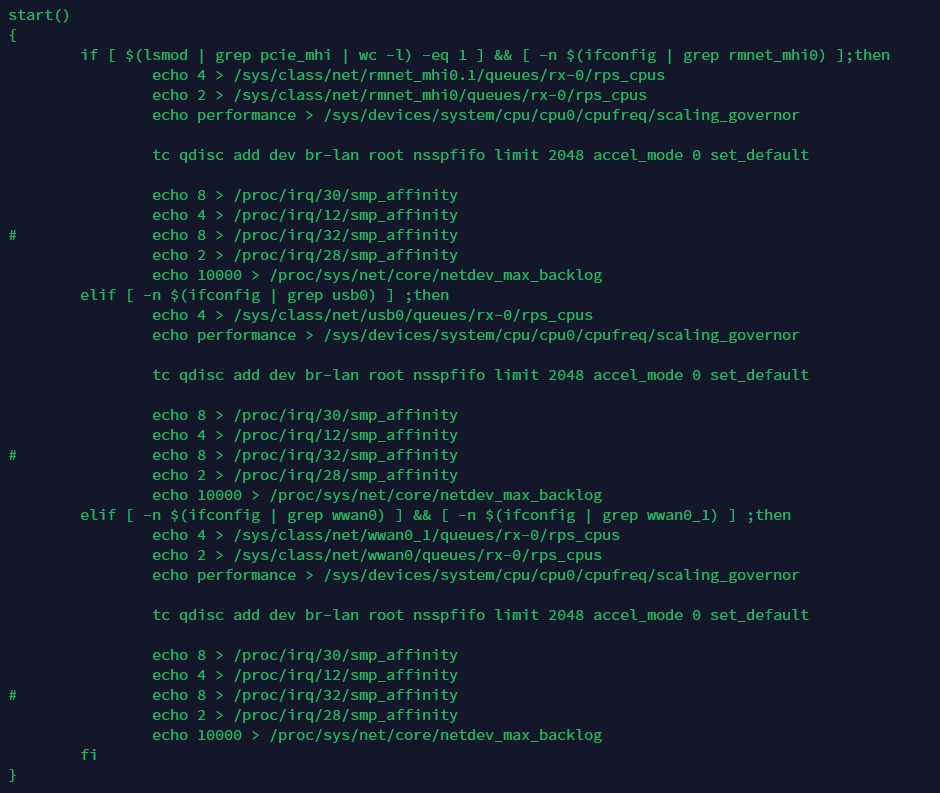
目的是把pcie的irq smp_affinity,分配到其他的cpu$index, 不要集中在cpu0﹑
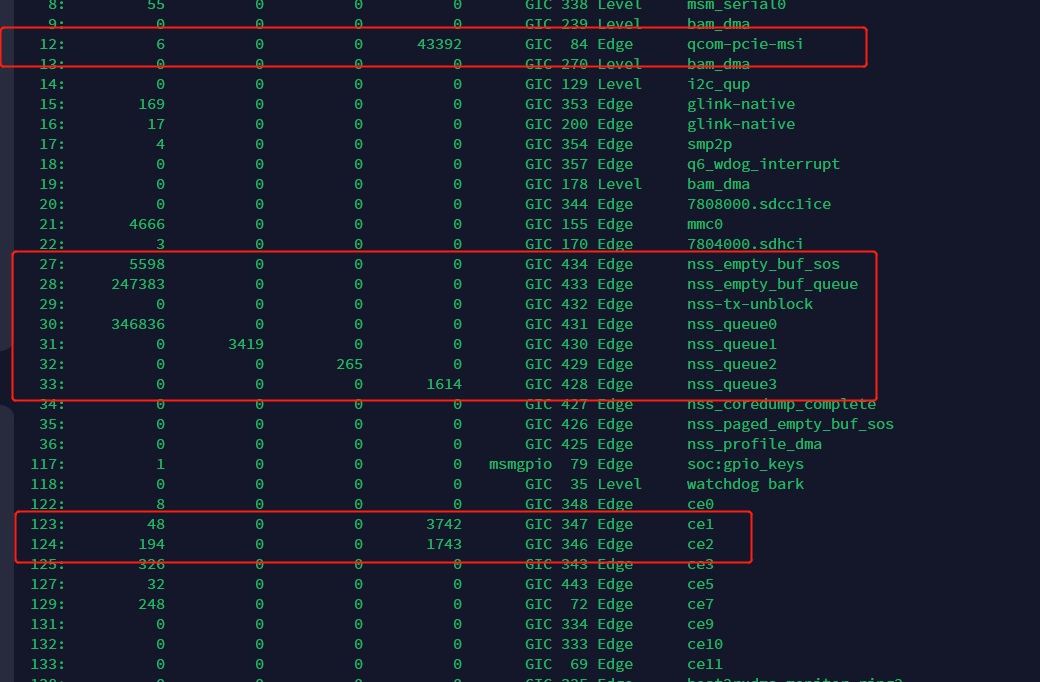
測試驗證:
我測試大約只有346Mbps. 這與測試環境有關,所以只能請客人自行測試。
客戶經過調整之後,可以平穩的跑在668 Mbps左右了,改善了100Mbps左右。而且已經趨近使用手機跑的數據 700+ Mbps。
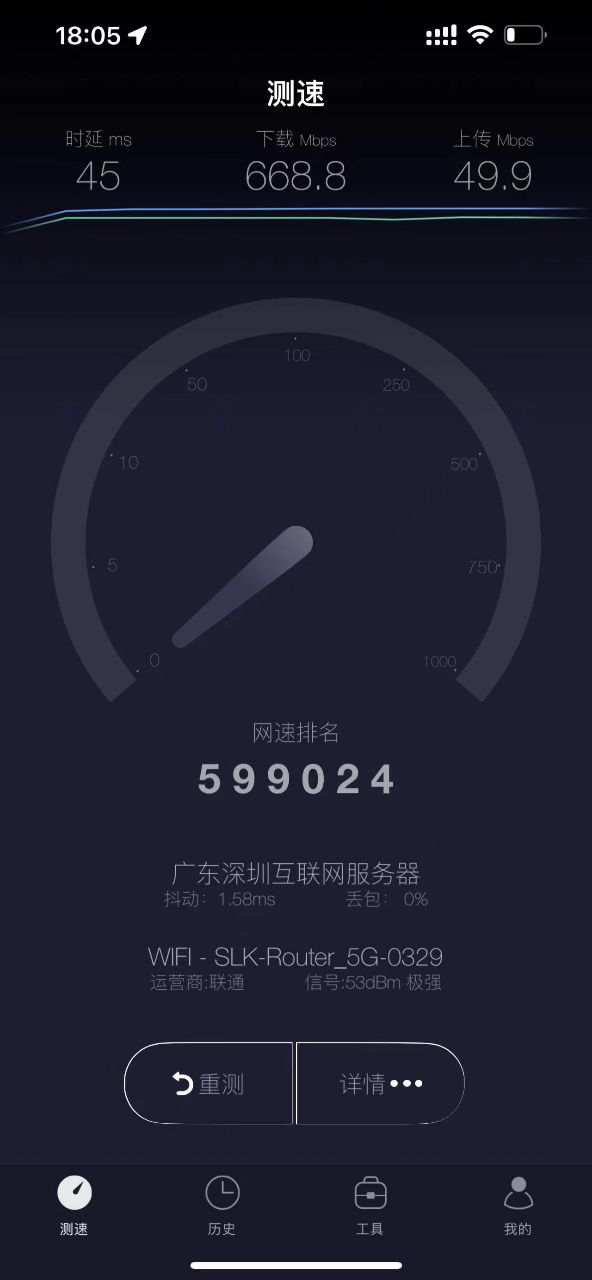
因為是相當平穩地落在670Mbps左右,而且略低於手機直接測試的700~900Mbps的下限,所以這個瓶頸點仍是落在Router上的,但是,Pcie 的flow已經錯開了,能再改善的空間不大。
本質上還是要從 Quectel提供的 驅動著手。所以我們進一步來看看驅動的內容差異。
驅動分析:
Quectel提供的驅動,已經把rmnet_data.c 給移除了。所以沒有機會使用NSS redirect來做offload。

rmnet_data 的interface 並沒有被建立起來。 所以也就看不到對應的irq

rmnet_data, 與 rmnet_nss 要搭配使用,處裡rmnet_mark_skb。如此才可以形成如下的path flow。否則skb會被當成一般的封包forward 到 bridge上去。多繞一圈而影響throughput。
data path 要如所下圖所顯示,完全的offload才可以有更好的throughput 表現。
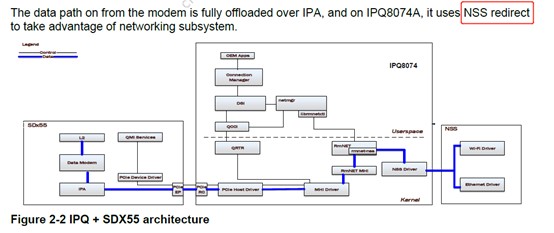
建議:
撇開一些控制方式的不同。當data call建立成功之後。模組廠需要確認data path是可以滿足offload 的。一個是模組內的IPA, 一個是驅動中的NSS redirect,兩個都要能正確的運行。 否則會耗用大量CPU時間來處理封包。即使有cpu irq的優化,也無法達到1.xGbps以上的throughput。rmnet_data.c 還是需要built-in到驅動中,用以實現nss redirect的功能。
Q&A:
Q:改了哪个CPU性能之后,PING路由器LAN口IP延迟变大到2MS了。
A: nss 也會 搶用irq的。 cpu core 只有四個。 network port 有 wan. lan. wifi. usb.... 多種可能。 packet ingress 到 egress的過程 產生的irq 就只能盡量錯開始用cpu core。
Q:如何查詢中斷?
A: cat /proc/interrupts
Q:WiFi 也有smp_affinity 的設定嗎?
A:有的,可以在/lib/update_smp_affinity.sh 找到類似的設定。
評論