

前言
上一篇”Caffe SSD-Mobilenet 模型訓練流程(ubuntu18.04)-上”已經教各位如何安裝Caffe
SSD-Mobilenet版本與訓練前處理,接下來要為各位介紹如何將已標註好的資料集放進Caffe SSD-Mobilenet進行訓練並展示最終結果。
訓練模型
- 建立自己對應label個數的train/test/deploy網絡文件,執行下面的命令:
- gen_model.sh 2 #2對應label 的個數,加上backgroud 就2個label,這裡一定要注意自己數據集中的類別數。(圖1)
圖 1
-
- 文件中生成一個example文件,裡面就是所生成的網絡定義文件。(圖2)
圖 2
- 利用下面的命令建立數據集的超鏈接:
- ln -s “PATH_TO_YOUR_TRAIN_LMDB” trainval_lmdb。(圖3)

圖 3
-
- ln -s “PATH_TO_YOUR_TEST_LMDB” test_lmdb。(圖4)

圖 4
- 在MobileNetSSD會出現兩個超鏈結文件。(圖5)
圖 5
- 修改solver_train.prototxt可以調整訓練參數。(圖6)
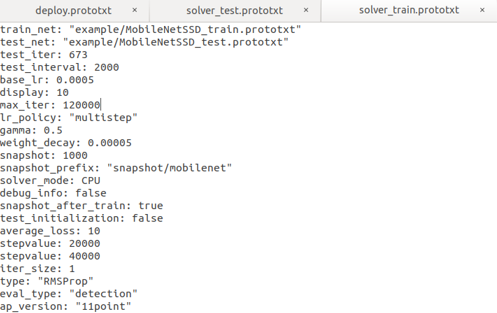
圖 6
- 執行train.sh進行訓練,最終會在snapshot產生結果。(圖7)
圖 7
- 使用merge_bn.py來進行bn層的合併以獲得最終模型。
- python merge_bn.py --model ./example/MobileNetSSD_deploy.prototxt --weights ./snapshot/mobilenet_iter_50000.caffemodel
- 此時會發現MobileNet-SSD檔案夾中多出一個no_bn.prototxt文件和一個no_bn.caffemodel文件,這就兩個檔案即是最終訓練結果。(圖8)
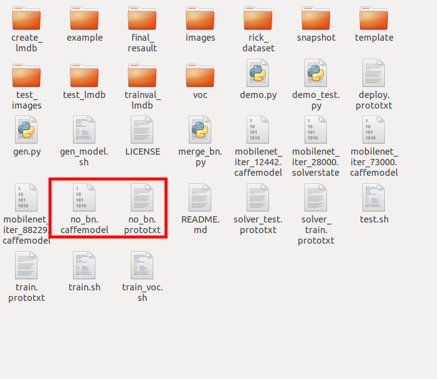
圖 8
展示結果
- 修改demo.py中:
net_file = no_bn.prototxt
caffe_model=no_bn.caffemodel(圖9)

圖 9
- 展示結果。(圖10、11、12、13)(圖片來源:https://github.com/AvLab-CV/AOLP)

圖 10

圖 11

圖 12

圖 13
結語
看完”Caffe SSD-Mobilenet 模型訓練流程(ubuntu18.04)-上”與”Caffe SSD-Mobilenet 模型訓練流程(ubuntu18.04)-下”這兩篇博文解說相信各位都已經了解如何訓練Caffe MobileNet SSD模型,透過兩篇博文讓各位了解最基本AI Detection功能的模型如何訓練出來。但現今AI模型發展快速已有更多模型出現,例如:Yolo、TensorFlow SSD-Mobilenet等等,因此各位需要不斷學新AI模型知識才能在技術方面跟上世界潮流。
評論