

Actor-Critic可以分為兩個部份來說明,Actor的前身是Policy Gradients,非常適合在連續動作中選取合適的動作,而Q-learning在做這件事情,會使Q-learning癱瘓的。
那為什麼不直接使用Policy Gradients?
因為Critic的前身是Q-learning之類的以值為基礎的學習算法,能進行單步更新。在Policy Gradients則是回合更新。這會降低學習效率。將兩者結合,Actor來選擇動作,Critic來告訴Actor它選擇的動作是否合適。
在Actor-Critic Network中的loss function,還是使用Policy Gradients中的loss=-log(prob)*vt,只是在Actor-Critic中將vt換成了TD error。訓練的方式很簡單,當收集到一組資訊集的時候,分別把s_t與s_{t+1}送進網路後可以得到相對應的q_t與q_{t+1},將網路輸出的數值與r_t代入下列公式中算出loss即可一步一步慢慢的更新網路參數使得TD error越來越小。
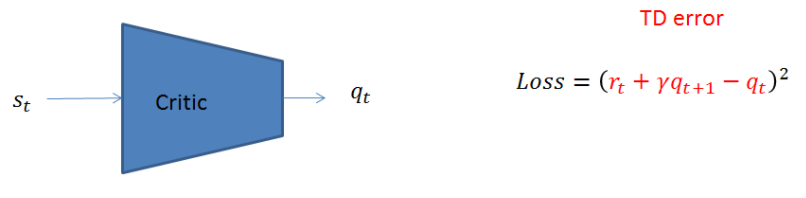
圖1 TD error of Critic Network
Actor 網路更新演算法和之前所敘述的policy gradient更新方式一樣,只是Advantage function換成了Critic網路所提供的TD error。
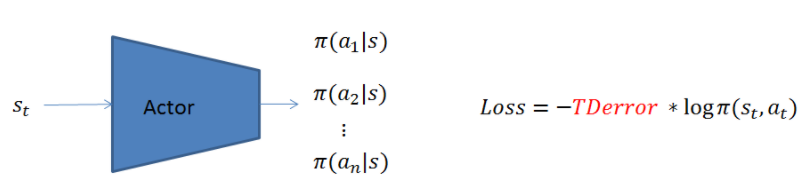
圖2 Actor Network
因此,完整的Actor Critic網路表示如下,第一步先用Critic網路算出TD error,第二步再使用TD error對Actor網路進行參數更新。
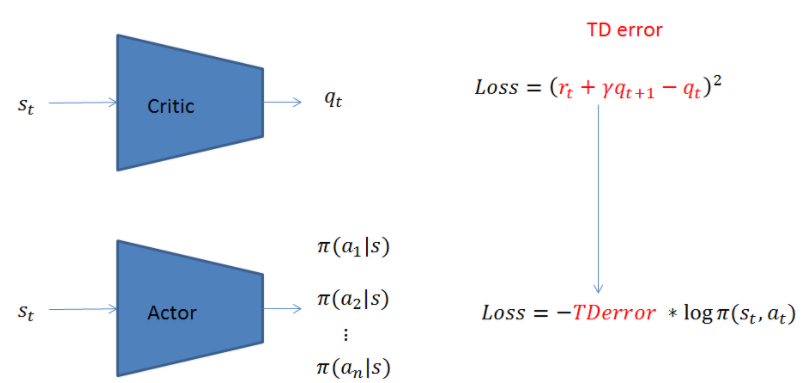
圖3 Actor Critic Network
在下面Actor-Critic架構圖可以很清楚看到,Actor是一個策略網絡(Policy Network),那麼他就需要獎懲信息來進行調節不同狀態下採取各種動作的機率,在傳統的Policy Gradient算法中,這種獎懲信息是通過走完一個完整的episode來計算得到的,這導致了學習速率很慢。而既然Critic是一個以值為基礎的學習法,那麼他可以進行單步更新,計算每一步的獎懲值。那麼二者相結合,Actor來選擇動作,Critic來告訴Actor它選擇的動作是否合適。在這一過程中,Actor不斷疊代,得到每一個狀態下選擇每一動作的合理機率,加了Critic網路之後就可以使用TD error當作advantage function做每步更新的步驟,Critic也不斷疊代,每個狀態下選擇每一個動作的獎懲值。
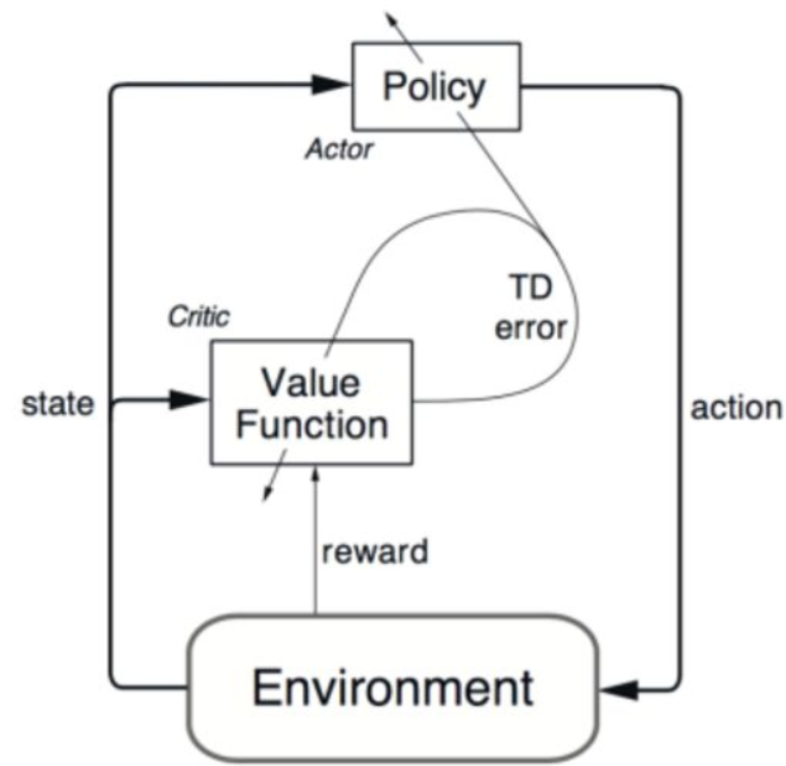
圖4 Actor–Critic 架構圖
因此Actor-Critic演算法的核心理論就是使用TD error當成policy gradient演算法的Advantage function。
評論