

在MediaTek IoT Genio1200平台上,MediaTek 提供許多不同的軟件解決方案,夥伴們可通過CPU、GPU和APU來提供 AI 計算能力。在開發和部署廣泛的機器學習時,決大部份會為了推演自行開發出的模型,來提供硬件加速功能,夥伴們也可通過圖形處理器來啟用 TensorFlot Lite模型的硬件加速。
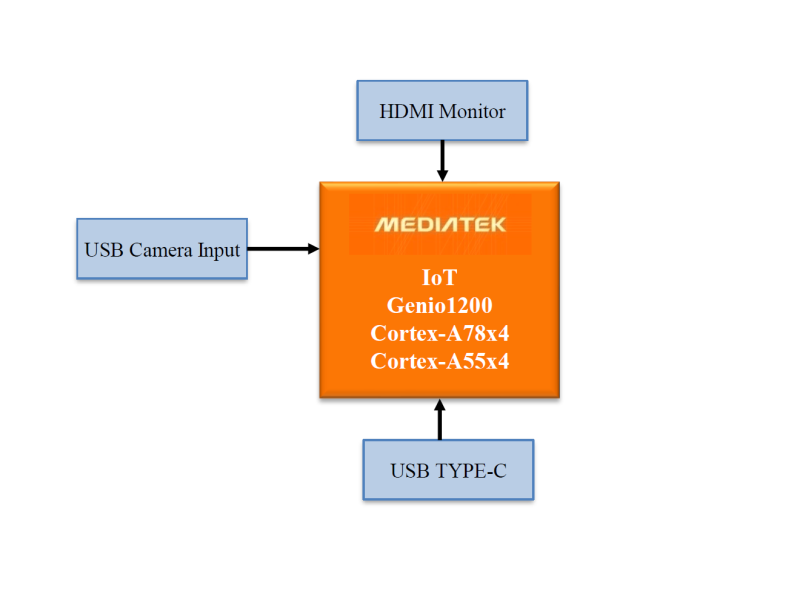
MediaTek IoT Genio1200 board:
以MTK IoT Yocto而言,目前已知下列三種方式(CPU、GPU和APU)
第一種是 ARM NN,是一組開源軟件,可在 ARM 的硬件設備上實現機器學習工作,它在目前常見的神經網路框架 Cortex-A CPU、ARM Mali GPU 之間橋接,透過 CPU 來運算和推演模型。
第二種是GPU Neural Network Acceleration,它使用的是設備上的 OpenGL ES(OpenGL for Embedded Systems)計算著色器來推演模型。
第三種是 APU Neural Network Acceleration (MediaTek Deep Learning Accelerator and Vision Processing Unit)。
讓小弟來為各位夥伴們介紹 MediaTek 專有的深度學習加速器,它是一款功能強大且高效的捲積神經網路(Convolutional Neural Network)加速器,MDLA能夠以高乘法累加(Multiply-Accumulate utilization, MAC)利用率實現高 AI 基準測試結果,此設計將 MAC單元與存用功能模塊集成在一起。
在開始演練之前,各位夥伴們是否還記得什麼是 MediaTek NeuroPilot 呢?忘記的夥伴們,可以回過頭去瞭解 淺談MediaTek NeuroPilot
NeuroPilot是聯發科AI 生態系統的核心。夥伴們可介由NeuroPilot在邊緣設備上,以極高的效率開發和部署 AI 應用程序。這使得各種各樣的人工智能應用程序運行得更快。夥伴們日後可以在 NeuroPilot SDK內,使用 Neuron編譯器( ncc-tflite),用於將 TFLite 模型轉換為MediaTek 專有的二進制文件 (DLA, 深度學習存檔),以便在 Genio1200 平台上部署。生成的模型非常高效,延遲減少,內存佔用更少。 Neuron SDK 還提供了 Neuron Run-time API,它提供了一組 API,可以讓夥伴們從 C/C++ 程序中調用這些 API,以創建運行時的環境,解析編譯的模型文件,並執行設備上的神經網路推理。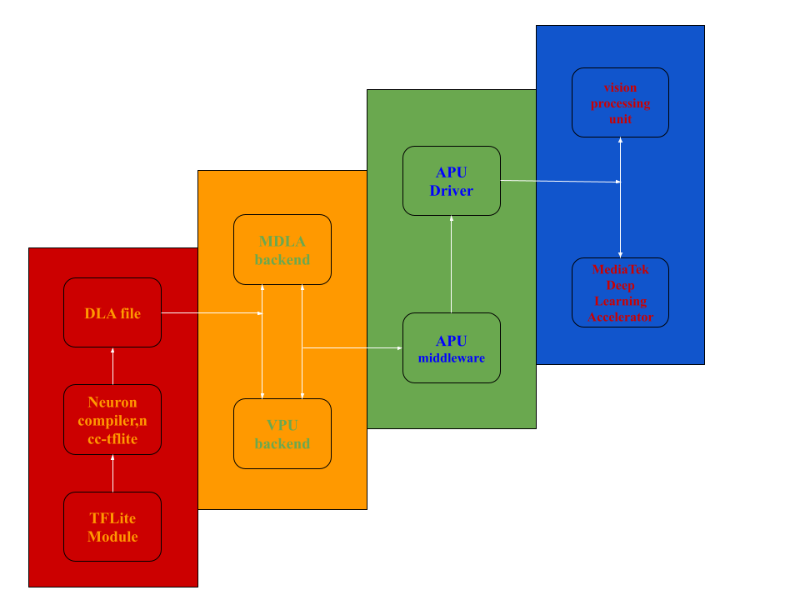
由圖示可以知道,DLA檔是 MediaTek專有模型,它是 MDLA(MediaTek Deep Learning Accelerator) 和 VPU(Vision processing unit )計算設備的 low-level binary 檔案。使用 ncc-tflite 將 TensorFlow lite 模型轉換成可在 APU 上推演的 DLA文件,再供給圖像/物件識別的應用程序使用。
使用預先寫好的腳本來將 TensorFlow Lite模型轉換成 DLA 文檔,信息如下:
root@i1200-demo:~# ls
convert_tensorflowLite_to_DLA.sh demos test.tflite
root@i1200-demo:~# ./convert_tensorflowLite_to_DLA.sh
[apusys][info]apusysSession: Seesion(0xaaaae26f9910): thd(ncc-tflite) version(2) log(0)
root@i1200-demo:~# ls
convert_tensorflowLite_to_DLA.sh demos test.dla test.tflite
root@i1200-demo:~#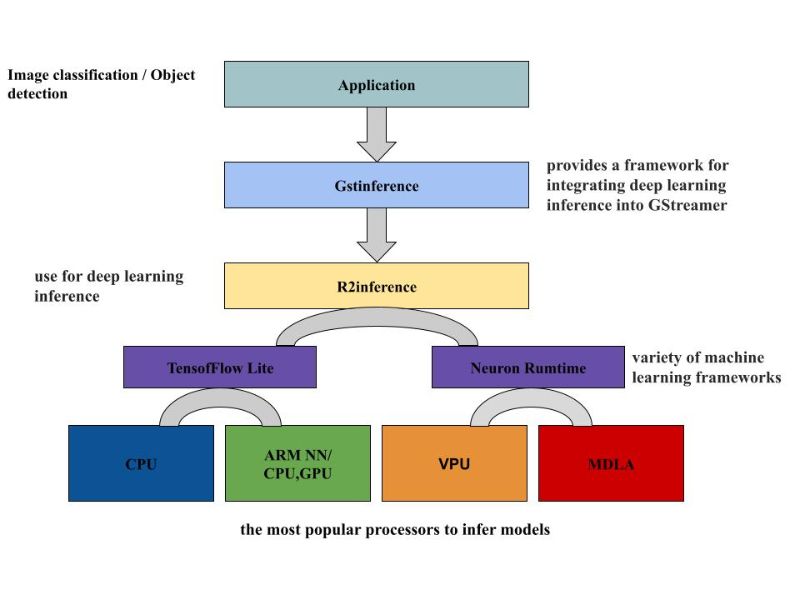
如圖所示,GstInference 是個開源項目,它提供了一個將深度學習推理整合到 GStreamer 中的框架。可用於眾多的深度學習架構進行推理,也可搭配實用的程序來支持自定義的架構。此框架使用 R2Inference,這是 C/C++ 中的一個抽象層,用於各種機器學習框架。單一個 C/C++ 應用程序就可以借助 R2Inference來使用不同框架上的模型。這對於利用不同的硬件執行推理時非常有用 (CPU、GPU、APU的加速器)。本次的演練是基於圖中的框架來實現即時影像識別的應用,將剛才轉換好的 DLA文檔來執行於圖像識別的推演。
接下來執行預先配置好的腳位來實現圖像和物件識別的演練。
root@i1200-demo:~# ls
convert_tensorflowLite_to_DLA.sh labels_objectD.txt test2.dla
demos objectD.dla test2.tflite
image_classification.sh object_detection.sh
labels.txt test.tflite
root@i1200-demo:~# ./image_classification.sh
執行結果將會顯示於 HDMI 屏上,可以看到所推演出的物件為 ballpoint pen
繼續執行物件識別的演示。
root@i1200-demo:~# ls
convert_tensorflowLite_to_DLA.sh labels_objectD.txt test2.dla
demos objectD.dla test2.tflite
image_classification.sh object_detection.sh
labels.txt test.tflite
root@i1200-demo:~# ./object_detection.sh
推演的結果,可以看到識別為 bottle

推演的結果可以看到識別為 monitor

推演的結果可以,可以看到識別為 chair

本次的演示就到此,有興趣的夥伴們可以一起來討論和研究,謝謝大家!
►場景應用圖
►展示板照片

►方案方塊圖
►核心技術優勢
雙核AI處理器單元(APU) 可處理基於 AI 的任務,支持深度學習(Deep Learning)、神經網絡(Neural Network)加速和計算機視覺(computer vision)應用。
►方案規格
CPU: Arm Cortex-A78 x4 Arm Cortex-A55 x4 GPU: Arm Mali-G57 MP5 APU: MediaTek AI Processor (dual core) Video processing: Video encoding 4K60fps HEVC/H.264 Video decoding 4K90fps AV1/VP9/HEVC/H.264 Software: Android/Yocto Linux/Ubuntu/NeuroPilot SDK Interface: HDMI 2.0 receiver (HDMI RX) PCIE3.0 USB3.1 GbE MAC ISP, 48MP@30fps/16MP+16MP@30fps