

2010年:改进的TeraScale 3架构的HD 6970


让我们把时光调整到2010年,在这一年年底的时候,AMD为了对抗NVIDIA 的GTX570显卡正式发布了HD 6970显卡,核心代号“Cayman”它采用改进的TeraScale 3架构,40nm的制程工艺,我们当年的评测链接还在,想具体回顾的同学可以点进去看一下。简单来说,HD 6970显卡有三大改进点,首先是更高效的图形与计算架构,它包括新的VLIW4架构提高了工作效率、双图形引擎提升图元和曲面细分处理能力、加强了RBE单元以及异步派遣机制增强GPU计算能力。第二个改进就是更优秀的图像质量,EQAA模式能提供更好的质量和性能。第三个改进为通过AMD PowerTune技术实时监控GPU功耗,来获取更杰出的功耗与电源管理。
虽然HD 6970的表现还可以,但是在绝对性能上面对NVIDIA GTX 580还是没什么办法的,这在一定程度上暴露出AMD当时对旗舰级显卡市场的掌控能力以及设计能力均不足的问题。
2011-2012年:GCN来临,HD 7970图形计算双冠王
2011年12月22日,AMD正式面向全球发布新一代HD7000系列显卡,率先面市的是单芯旗舰产品:AMD Radeon HD7970,这张显卡堪称传奇,拿下了很多“第一”的奖项。它是业界第一款采用28纳米工艺制程的GPU图形芯片、业界第一款支持DX11.1显卡、业界第一款支持PCI-E3.0接口显卡。相对于上一代产品HD 6970,HD7970在架构上有很大的改进、在性能上有巨大的提升,是一款面向未来游戏/高性能运算的前卫新一代显卡。我们超能网当时给这张显卡“图形计算双冠王”的评价,可见这张卡发布时给玩家们带来的震撼。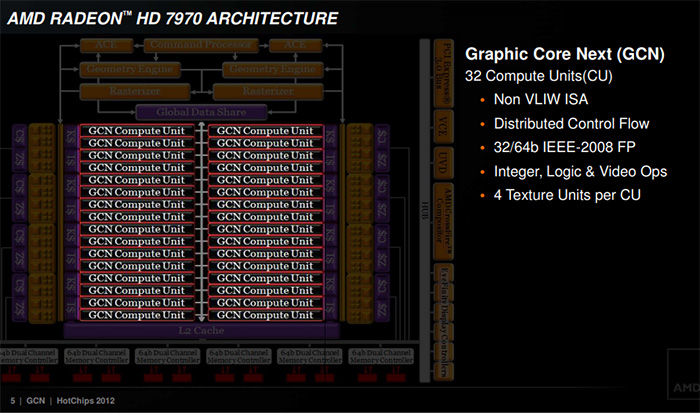
这么大的进步原因就是AMD使用了全新的架构-GCN(Graphic Core Next)。GCN虽然大家现在对他是嗤之以鼻,在当年可是名副其实的先进架构,AMD对它寄予厚望,不仅要游戏性能强大,还要灵活应对GPU计算时代,要提高GPU的多线程处理能力,优化高性能计算,提高扩展能力和弹性。GCN架构中基本的组成单元为“Compute Unit”(简称CU),这个称呼至今仍在沿用,每个CU中有1个标量单元和4个矢量单元,每个矢量单元又是由一组SIMD-16阵列组成,这4组SIMD-16阵列各有64KB寄存器(Registers),并且是独立运算,这样一个CU单元同时就可以执行多条指令。
第一代完整的GCN核心拥有32个CU单元,每个CU单元又下辖64个ALU单元和4个TF纹理单元,总计有2048个ALU计算单元,128个纹理单元,相比之下HD 6970的流处理器单元只有1536个,纹理单元也只有96个。通过这些改进以及晶体管数量的上升,AMD的HD 7970显卡性能直接碾压了对手GTX 580,并且功耗也比对方低很多,名副其实的“图形计算双冠王”。
但是NVIDIA也不甘示弱,他们在两个月后发布了GTX 680,夺回了卡皇的位置。AMD这边直接发布了一款“官超版”HD 7970GHz显卡,略微提升了频率,再次夺回了显卡卡皇的位置,只不过功耗却涨了不少。2011-2012年这个时间段应该来说AN两家都在互相角力,不分胜负。
2013年:GCN2.0登场,R9 290X搭配512bit位宽

在2013年这个时间段对于AMD来说,非常的难受,CPU那边的“推土机”也好“打桩机”也罢,都是雷声大雨点小,不但没能完成AMD逆转Intel“酷睿”的任务,CPU市场的失败反而让AMD陷入到沉重的经济危机,也是从这个时候开始,AMD的GPU部门就不得不勒紧裤腰带研发了,考虑到GCN架构表现还不错,在经济有限的情况下基于GCN进行改进是一个很棒的“缓兵之计”,只不过让所有人都没想到的是,这个暂时的“缓兵之计”,一缓就是7年....
咳咳,说回GCN2.0,基于GCN1.0也是有不少改进的。首先是大幅扩增了CU单元数量,从HD 7970的32组CU单元提升到了44组CU单元,它由4组Shader Engine渲染引擎组成,每组渲染引擎又包含11组CU单元,每组CU单元的组成基本不变,这样一来CU单元总数就从原来的32组提高到了44组,流处理器单元数量从2048提高到了2816个,纹理单元则达到了176个。
此外,几何单元和光栅单元也被放到了渲染单元中,Hawaii核心的几何单元数量就从原来的2组变成了4组,而ROP单元从原来的32个暴增到64个。这可以帮助R9 290X在开启抗锯齿特效时提供更高的性能。当然了,最大的突破就是这张卡的位宽达到了512-bit,AMD的设计师曾解释说512-bit位宽比384-bit位宽确实要复杂一些,但是AMD也仔细评估了高频率+低位宽与低频率+高位宽两种显存设计的利弊,认为高位宽+低频率的组合还是要优于前者,通过优化,521bit显存控制器占用的面积反倒比之前384bit位宽更低20%,因此R9 290X选择了512-bit位宽,这样一来显存频率不需要太高就能达到极高的带宽。
R9 290X最终的性能应该说是小幅度领先NVIDIA的GTX 780的,只不过在功耗和发热上却逊于对手,AMD也是在这个时候给玩家们留下了大火炉、功耗高的印象。但是老谋深算的Jensen Huang留下的一手后招GTX 780Ti在一个月后就重新夺回了显卡卡皇的宝座,NVIDIA在这个时候逐渐掌握了GPU市场的主动权。
2014-2015年:GCN3.0来袭,R9 Fury X铩羽而归

这两年AMD曾经“马甲式”更新了R9 300系列显卡,但是在性能上真的是乏善可陈,我们跳过它直接看真真意义上的新产品“R9 Fury”系列显卡,看到NVIDIA这几年在GPU领域“风生水起”,AMD的GPU研发部门顿时心生一计,当年它们多次利用显存换代、工艺制程等领先技术击败NVIDIA,现在是时候继续使用这个策略了。

就这样,AMD与SK海力士研发了不同于GDDR显存的HBM显存,这种显存频率虽然远低于GDDR显存,但它却拥有极高的显存位宽,从而获得更高的显卡带宽。并且HBM显存可以与核心一起封装,极大的节省了PCB空间,显卡长度变短成为现实。为了降低R9 Fury X的温度与噪音,AMD这次直接给R9 Fury X上了一体式水冷,效果立竿见影,恼人的高温与噪音都消失了,得到了死忠A粉的认可。
AMD在R9 Fury X上再次扩增了GCN架构的CU单元数量,达到了64组,总计4096个流处理器单元,256个纹理单元,64个ROP单元,核心面积达到了596mm2,晶体管数量则达到了89亿个,比NVIDIA的GM200核心的80亿个还要多。这么舍得堆料,这次的“R9 Fury”系列能扭转GPU市场的格局吗?
答案是:并没有。事情远没有AMD想象中那么美好,由于R9 Fury X搭载的Fiji核心架构是GCN3.0,本质上还是GCN,在能耗表现上已经远不如对手的麦克斯韦架构了。此外,HBM显存的良品率低的离谱,这间接导致了整张显卡的成本压不下来,产量也低,没有办法跟竞争对手打价格战抢占市场。最后即便R9 Fury X的性能比GTX 980强,但销量真的很低,确切地说是产量很低,因此这张显卡没能像AMD期待的那样,帮助他们在GPU市场上扳回一城。
在当时AMD一共推出了三款Fiji核心的显卡——R9 Fury X、R9 Fury及R9 Nano,令AMD没想到的是从后来的消费者喜爱程度来看,这三张显卡最受欢迎的其实是R9 Nano,HBM显存带来的高性能、小面积优势在这个显卡上完全体现出来了,真正的ITX小钢炮,而且与Fury显卡相比,R9 Nano显卡的功耗表现就好太多了,并且当时NVIDIA在ITX短卡上没有重视起来,R9 Nano基本上就是当时ITX主机显卡的首选,性能强功耗低。
直到现在,仍然有不少人心心念念着这款显卡的后继型号,目前来看除非AMD再次使用HBM显存搭配到一个足够节能且强劲的显卡核心,否则Nano显卡的继任者很难出现。综上所述,2014年-2015年AMD精心准备的R9 Fury系列显卡最终还是让A粉们失望了,并且也暴露出了GCN架构的很多问题,比如计算单元很难突破64组,频率一旦超过1GHz之后功耗就呈几何式上升等弊端。
2016-2018年:基于GCN 5.0的VEGA 64/56显卡

我们之前提到了GCN的一些弊端,AMD不是没有看到,只不过当时的CPU部门正在大力研发ZEN以及后续的架构,留给GPU的预算真的很少,显卡部门明知“山有虎”也不得不向“虎山”行,他们只能摸着Fury系列显卡的路子,继续采用这种依靠HBM显存为核心的显卡设计思路,基于GCN4.0进行改良,推出了“VEGA”架构显卡:VEGA 64以及VEGA 56。

从官方资料来看,Vega使用的GCN 5.0架构变化还真不少,主要涉及Vega显卡新一代显存架构、Vega显卡新一代几何渲染管线、Vega显卡新一代NCU单元、Vega显卡新一代像素引擎等,事实上之前我们提到过,GCN架构4096个流处理器已经是极限了,Vega核心依旧是64组CU单元总计4096个流处理器单元,但内部单元做了改进,AMD宣称是优化了IPC性能,并提高了运算单元的灵活性。
在计算性能上,Vega首度引入了紧缩的半精度计算支持,Vega的微架构被称为“NCU(下一代计算单元)”,每个NCU中拥有64个ALU,它可以灵活地执行紧缩数学操作指令,如每个周期可以进行512个8位数学计算,或者256个16位计算,或者128个32位计算。这不仅充分利用了硬件资源,也大幅度提升Vega在深度学习计算的性能。效果也非常显著,在之前公布的Radeon Instinct MI25计算卡就是基于Vega架构的,其FP32单精度浮点性能12.5TFLOPS,而半精度FP16性能直接翻倍到25TFLOPS。
除了 NCU内核的改进,Vega的重点还是围绕HBM2显存来的,但是这一代的HBM2显存为了减少成本,只用了2颗堆栈,等效位宽从上代Fury X的4096bit降至2048bit,通过频率提升到1890MHz实现了484GB/s的带宽,但比Fury X的512GB/s实际上降低了。

不过AMD始终没能意识到计算性能在游戏玩家眼里其实没什么用,还是要看游戏帧数,老黄这边很早就发现了这个问题,一直在给自己的游戏显卡做减法,任何跟游戏无关的运算单元统统砍掉,而GCN则是为了提升计算能力越来越臃肿,最终导致浮点运算能力虚高,实际游戏表现不如预期的问题频频出现。
虽然VEGA架构做出了很多改进,但本质上还是GCN架构的它仍然不能摆脱“GCN魔咒”,功耗高、发热大、高分低能等帽子统统都被VEGA显卡戴上了,这代显卡从结果上看其实是非常失败的,不但在发布时间上比GTX 10系列的帕斯卡晚了一年多,而且在极限性能上被GTX 1080Ti拉开了很大的差距,只能跟GTX 1080一较高下。以前的A家旗舰卡至少在性能上会卡在80与80Ti之间,这次GTX 1080Ti成为了A卡难以逾越的鸿沟,并在相当长的一段时间之内,1080Ti始终成为A粉心中难以抹去的痛。
不过好在A卡的祖传手艺刷BIOS还在,许多玩家发现如果你的VEGA 56显存是三星的就可以尝试刷一个VEGA64的BIOS,在性能上可以获得接近VEGA64的效果,还算是比较有趣。此外,AMD显卡的默认电压给的都偏高,玩家们也大都降压使用,经过这么一番“折腾”之后,VEGA显卡的能耗比才比较正常,我本人也是当年的VEGA56老用户,只不过我当时显存是SK海力士的,一番“折腾”之后我只是降压使用了。现在回想起来还是挺有趣的,自己刷BIOS、试验电压、调整频率等,把显卡的性能发挥到极致,只不过这种感觉随着厂商的出厂灰烬调教是越来越体会不到了。不过这也客观上说明当时AMD的显卡驱动在默认电压的调教上其实是有大问题的,给偏高的电压会导致功耗、温度暴增、最终显卡降频的恶性循环,影响了自己在用户中的口碑。
2019年:革命性的RDNA 1代显卡,大幅提升能耗比
AMD在2019年的CES上发布了Radeon VII显卡,这款显卡除了是世界上第一款7nm制程工艺的显卡之外,其实没什么特别的。它依旧采用Vega核心,不过制程工艺升级到了台积电7nm,14nm Vega显卡核心面积为495mm2,7nm Vega核显面积下降到331mm2,面积缩小了33%,同时晶体管数目也略微增长了5.6%。此外,Radeon VII最高频率达到了1800MHz,相比上一代RX Vega 64风冷版也只有可怜的1546MHz,频率提升幅度在16.5%。在性能上这款显卡与RTX 2080差不多,但是由于成本原因,这张显卡更是象征意义的发布,并没有大量的铺货。而真正开始铺货的是年中发布的RX 5000系列显卡,Radeon RX 5000系列显卡采用的Navi 10核心采用了与Radeon Ⅶ相同的7nm制程工艺。新工艺使得Radeon RX 5700系列显卡的核心面积仅为251平方毫米,同时对比此前的Radeon RX Vega 64/56的486平方毫米,尺寸大幅下降了48%,是一个面积较小的小核心。
RDNA1代我认为最大的进步就是相比GCN架构在能耗比上提升了50%,这点与CPU当时的“ZEN”架构发布时有些相似,这是AMD7年来首次换用新架构制作显卡,AMD称其为“专为游戏而生”的DNA,即为"RDNA"架构,AMD吸取了之前的教训,在之后的产品路线中,游戏显卡使用RDNA架构,而专业计算卡则是使用CDNA架构,两者各司其职,共同完成AMD赋予它们的使命。
Radeon RX 5700 XT作为RDNA1代架构中性能最强的型号,其采用的Navi 10核心拥有完整的40组CU计算单元。从架构图中可以看出AMD将40组CU单元分为4组,每组中有10个CU计算单元,同时每两组CU单元组成一个Dual Compute Unit。RX 5700 XT也拥有160个纹理单元,还有60个光栅单元。
在显存方面,此次AMD为RDNA架构的两款显卡都搭载了全新的GDDR6显存,这也是AMD首次采用GDDR6显存。相比于AMD此前在RX Vega 64/56中使用的8GB HBM2显存,GDDR6显存由于采用了如16bit预取宽度、改进版QDR 4倍数据倍率等技术,使得相比其上代的GDDR5性能有了大幅提升,所以此次RX 5700系列采用了GDDR6显存,相比RX 590等采用的GDDR5显存性能提升非常大,与Vega 64/56采用的8GB HBM2显存对比也不落下风,带宽达到了448GB/s。同时相比于HBM2显存的高价格,GDDR6显存也可以让AMD有效控制显卡整体成本。
功耗方面,7nm工艺的加持外加更高能效比的RDNA架构,使得其能够在功耗表现上要比之前的Vega系列显卡出色很多,RX 5700 XT TDP功耗为225W,而RX 5700 TDP功耗甚至在200W以下,为185W。虽然在性能上RX 5700XT只略微领先RTX 2070,但是需要注意的是,这只不过是一个251平方毫米的小核心而已,RDNA架构的潜力远不止于此,我曾写过RDNA2代显卡的性能预测,RDNA2显卡性能会有什么表现,文中说的已经很清楚了,事实也不出我所料,在RDNA2的显卡发布会上我们看到了AMD的RDNA1代架构确实只能称得上是小试牛刀,真正的革新就在眼前。
2020年:RDNA 2大进步,RX 6900XT绝地反击
北京时间2020年10月29日零点,AMD正式发布了自己新一代的RX 6000系列显卡。RX 6000系列显卡基于RDNA2架构,在性能以及能耗比上相比RDNA1代进步明显。其中旗舰型号RX 6900 XT不负众望,时隔多年又一次与NVIDIA的旗舰显卡展开竞争并在价格上拥有优势。我们一起再来回顾一下发布会上RDNA2的亮点。
RDNA 2架构

AMD首先表示RDNA2架构实现了高性能的CU计算单元、革命性的无限缓存技术,突破性的高核心频率设计等
作为能耗比提升的重要一环,AMD这次并没有盲目的上大位宽战略,而是凭借着自己在CPU领域的经验,通过大缓存来缓解带宽不足的问题。相比起普通的384bit GDDR6,使用无限缓存之后的显卡核心可以做到等效2.17X的带宽,同时耗能仅为384bit时的90%。

并且之前A卡一直被大家诟病的发热量大、耗能高、性能低的帽子在RDNA2上全部撇掉,在能耗比的进步上RDNA2突破了预期的相比RDNA1代50%的提升,直接来到了54%的提升。连续两代架构都是如此大的提升,并且没有吃制程红利,可想而知RDNA2架构的出现对于AMD来说是多么的重要,堪称革命级的发布!
我们直接看AMD旗舰卡RX 6900XT,拥有80组CU计算单元,游戏频率为2015MHz,Boost频率为2250MHz,搭载128MB的无限缓存,16GB的GDDR6显存,整卡功耗300W。RDNA2显卡一举打破了GCN时期CU单元没法突破64组的尴尬处境,顺利的拥有了80组CU单元,这对性能的提升是毋庸置疑的。
AMD CEO Lisa Su非常激动的表示在RX 6900XT上他们甚至实现了多达65%的能耗比提升,这个数字是疯狂的,这足以让AMD的新显卡在能耗比上超越对手,在提供相同性能的同时降低功耗。
在游戏性能方面,RX 6900XT直接对标RTX 3090,在4K分辨率中的测试中,两者难分伯仲,从游戏帧数获胜的数量上来看RX 6900XT领先的游戏比RTX 3090多出一款,有一点略微的小优势。那么关于全新的RX 6000系列显卡大家稍安勿躁,我们正在紧密测试中,欢迎大家届时查看首发测评。
总结:RDNA架构充满潜力,AMD未来带来更多惊喜
与CPU的发展历史一样,AMD的GPU前进路程同样充满坎坷。但是我认为AMD的GPU部门的困难会更大一些,Intel在取得CPU霸主地位之后有点不思进取,小看了竞争对手,在相当长的时间里性能提升堪称“挤牙膏”,最终“龟兔赛跑”领先的“兔子”没想到自己竟然被那个看起来速度很慢的“乌龟”追赶上,最终让AMD在CPU领域成功“翻身”。再来看GPU这边,Jensen Huang就拥有忧患意识,虽然自己已经是GPU领域毫无疑问的霸主,但是他仍然在大力研发新架构,每代旗舰卡的性能提升都不算小,在GTX 1080Ti时期甚至让AMD显卡部门感到绝望。
不过功夫不负有心人,即便在GPU市场无论是占有率还是用户口碑都不如NVIDIA的情况下,AMD仍然没有放弃,通过自己与两家主机的良好合作关系,AMD显卡部门耐心等待着机会,先“生存”再“复仇”。终于“ZEN”架构CPU的成功为他们带来了充足研发经费,为显卡新架构的成功打下了一个坚实的基础。老虎也有打盹的时候,Jensen Huang在取得市场优势之后为了大力研发全新的光线追踪技术消耗了很多精力,在传统性能的提升上相对略显迟缓一些,这也给了AMD弯道超车的机会,先在传统性能上进行追赶,再对光线追踪性能步步紧逼,所以AMD在显卡上追平NVIDIA的难度其实比在CPU领域还要难。
此外,我想再次提到David Wang王启尚先生,这位当年一手缔造GCN架构的“大佬”在AMD显卡部门遇到困难时选择回归,并立即研发出了RDNA2架构,扭转了AMD多年以来在能耗比上的劣势,堪称这次RX 6000系列显卡成功的第一大功臣,这是毋庸置疑的。之前王启尚研发GCN功成身退离开AMD之后,接替他的Raja虽然在架构层面也进行过多番尝试但始终没能跳出GCN这个圈,致使AMD显卡的表现总是不如预期,Raja本人也是直接被Intel邀请过去“鼓捣”他们的核显与独显了。受命于危难之际,奉命于危难之间,王启尚在AMD最需要他的时候站了出来,他接受了Lisa Su的邀请重回AMD并立即开展新架构的研发工作。“大佬”就是“大佬”,完全由他主导的RDNA2架构,在工艺制程保持不变的情况下仅凭架构革新就一举把之前多年的差距几乎追平,这样的人你怎能不尊敬?
在RDNA2架构显卡发布会上,AMD表示RDNA3架构显卡已经在设计之中,我们现在已经看到了RDNA架构充满潜力,所以未来AMD在GPU领域还会带给玩家们什么样的惊喜呢?让我们拭目以待。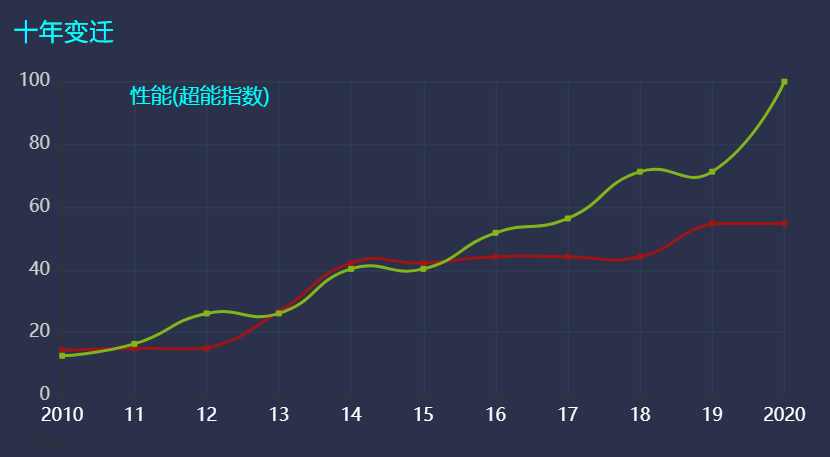
评论