

Reccurent Neural Network 簡稱 RNN,當我們想使得Neurel Network具有時序性,我們的Neurel Network就必須有記憶的功能,然後在我不斷的輸入新資訊時,也能同時保有歷史資訊的影響,最簡單的作法就是將Output的結果保留,等到新資訊進來時,將新的資訊和舊的Output一起考量來訓練Neurel Network。跟之前提到的 CNN (找出特徵),Autoencoder (降維 重建) 不同.它關注的是 時間序列 有關的問題,舉個例子,一篇文章中的文字會是跟前後文有前因後果的,而如果想要製作一個文章產生器,就會需要用到 RNN。觀察下面這個 RNN 基本的結構圖(圖1).其中 Xt 以及 Ht 分別是 t 時刻的輸入以及輸出,可以看到 Ht 會跟 Ht-1 以及 Xt 有關,可以簡單地把它想像成多一個輸入的神經網路。
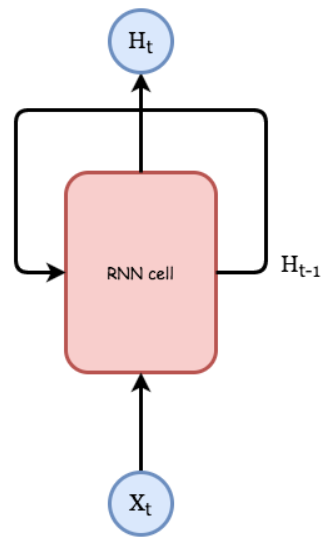
圖1 RNN 結構圖
那如果我們依照時間序列展開 RNN 就會變成圖2的樣子:
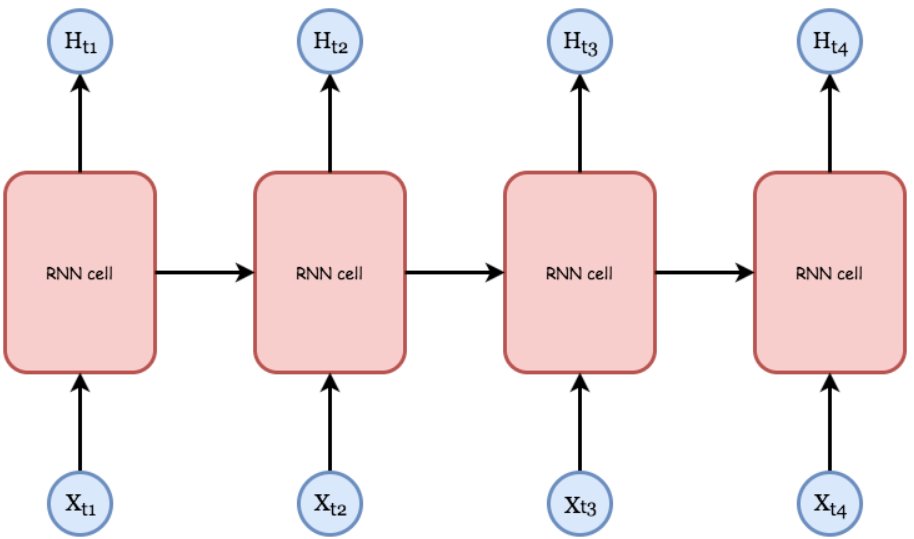
圖2 時間序列RNN
每一個時間點的輸出,除了跟當前的輸入有關,也會跟前一刻,前前一刻...等時間點的輸出有關係.如此就相當於把各個時間序列點的輸出連結了起來。這種不斷回饋的網路可以攤開來處理,如上圖,如果我有4筆數據,拿訓練一個RNN 4個回合並做了4次更新,其實就等效於攤開來一次處理4筆數據並做1次更新,這樣的手法叫做Unrolling,我們實作上會使用Unrolling的手法來增加計算效率。接下來來看RNN內部怎麼實現的,圖3是最簡單的RNN形式,我們將上一回產生的Output和這一回的Input一起評估出這一回的Output,詳細式子如下:
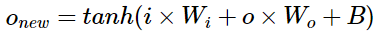
圖3 最簡單的RNN式子
如此一來RNN就具有時序性了,舊的歷史資料將可以被「記憶」起來,你可以把RNN的「記憶」看成是「短期記憶」,因為它只會記得上一回的Output而已,如圖4。
圖4 RNN內部構造
理論上來說這是一個很完美結構,可以處理許多跟時間序列有關的問題,但是實際上會遇到許多的問題,什麼問題呢?想像一下在訓練模型的時候會利用Backpropagation 來更新權重,而 RNN 的輸出會跟前一刻有關,所以也會傳遞到前一刻的模型更新權重,依此類推.當這些更新同時發生的時候就可能會產生兩個結果,一個是梯度爆炸 (Gradient Exploding)另一個是梯度消失 (Gradient Vanishing)
在RNN的結構裡頭,一個權重會隨著時間不斷的加強影響一個單一特徵,因為不同時間之下的RNN Cell共用同一個權重,這麼一來若是權重大於1,影響將會隨時間放大到梯度爆炸,若是權重小於1,影響將會隨時間縮小到梯度消失。解決梯度爆炸有一個廣為人們使用的方法,叫做Gradient Clipping,也就是只要在更新過程梯度超過一個值,我就切掉讓梯度維持在這個上限,這樣就不會爆炸,待會會講到的LSTM只能夠解決梯度消失問題,但不能解決梯度爆炸問題,因此我們還是需要Gradient Clipping方法的幫忙。在Tensorflow怎麼做到Gradient Clipping呢?我們可以把這一步驟拆成兩部分,第一部分計算所有參數的梯度,第二部分使用這些梯度進行更新。因此我們可以從中作梗,一開始使用optimizer.compute_gradients(loss)來計算出個別的梯度,然後使用tf.clip_by_global_norm(gradients, clip_norm)來切梯度,最後再使用optimizer.apply_gradients把新的梯度餵入進行更新,而在下一章會說明LSTM RNN的基礎,來解決梯度消失的問題
評論