

8B/10B編碼的目的
資訊量愈來愈大的時代,資料的高速傳輸成為重要的趨勢,在追求高速傳輸的同時,資料的傳輸正確性也非常重要,於是演生出8B/10B的編碼. 很多高速傳輸的差分介面都使用了此種編碼以加強資料正確性, 如V by one, HDMI…., 為什麼要編碼? 有什麼好處? 我們用下面的圖來解釋: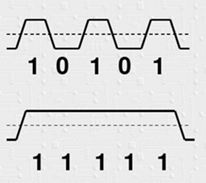 ——》
——》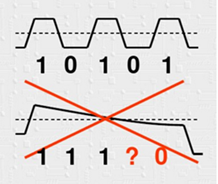
大家看明白了吧,由於我們的串列鏈路中會有交流耦合電容,我們知道理想電容的阻抗公式是Zc=1/2πf*C,因此信號頻率越高,阻抗越低,反之頻率越低,阻抗越高。因此上面的情況,當碼型是高頻的時候,基本上可以不損耗的傳輸過去,但是當碼型為連續“0”或者“1”的情況時,電容的損耗就很大,導致幅度不斷降低,帶來的嚴重後果是無法識別到底是“1”還是“0”。因此編碼就是為了儘量把低頻的碼型優化成較高頻的碼型,從而保證低損耗的傳輸過去,所以有愈來愈多的高速信號傳輸,採用此種編碼方式.
編碼的缺點
但8B/10B編碼有什麼缺點? 要把8bit的實際資料擴展為10B,那開銷就是20%,效率就只有80%了,更通俗來說就是增加了20%的非實際資料的傳輸 。所以一個好的編碼方式,除了看它本身的演算法優化情況外,還要注重效率高不高。
編碼的方法
上面解釋了原因,下面就介紹下這種8B/10B的編碼方式的演算法。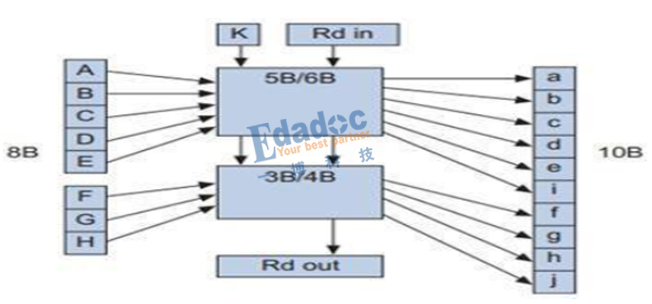
如上圖,關於8B/10B編碼演算法有下面幾點需要理解:
1, 低5位(ABCDE)中間加一位,進行5B/6B編碼,高三位元(FGH)中間加一位,進行3B/4B編碼;
2, 編碼後的bit僅會出現這三種情況:5個“0”與5個“1”、4個“0”與6個“1”、6個“0”與4個“1”;
3, 有兩個術語要知道:不均等性(disparity)和極性偏差(running disparity,RD)。
不均等性是指編碼後的碼型資料是“1”多還是“0”多,如果是“1”多,則極性偏差RD為-RD,如果是“0”多則為+RD。那定義+-RD有什麼意義呢?+-RD代表著同一個碼型的兩種編碼方式。我們本身就是編碼的目標就是為了緩解長“0”或長“1”的影響,因此在編碼後如果“1”多的話,我們下一次的編碼就要把這種碼型做一個修正,因此從-RD碼型變成+RD碼型。如果是“0”和“1”一樣多,極性則不用變,如下圖:

4, 我們怎麼知道編碼後映射成什麼碼型呢?因此會有一個專門的編碼表,我們只需要在上面找到我們的原始碼型,然後就一目了然了。編碼表如下所示(部分截圖):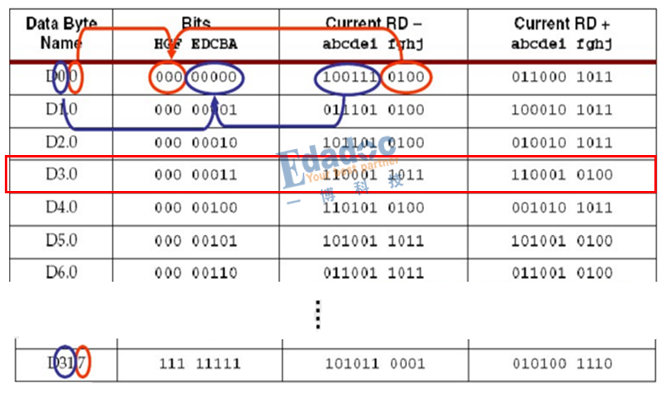
舉例說明
原始的碼型如下: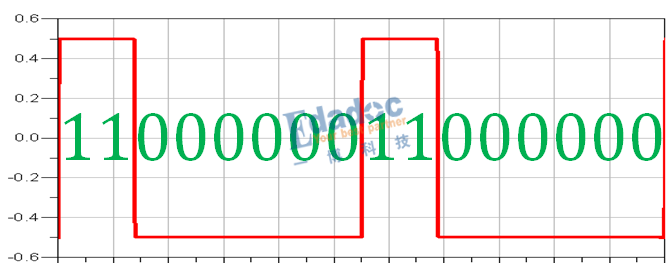
模擬得到8B/10B編碼後的碼型如下:
對照上面的編碼表,結果完全相同,從RD-的模型出發,編碼後RD-的碼型“1”比較多,因此極性變成RD+的編碼碼型,接著RD+的編碼碼型“0”比較多,極性又變回RD-,因此碼型就是RD-和RD+之間迴圈下去。
這種編碼可以保證不會有4個以上連續的0或1,以及所有的0和1的個數會幾乎相同, 以避免電路效應造成的不正確。
評論
池勇
2020年6月4日