

雖然我們可以享受到這些AI應用帶來的益處,但這種方法導致隱私、功耗、延時和成本等諸多因素麵臨挑戰。如果有一個能夠在數據來源處執行部分或全部計算(推斷)的本地處理引擎,那麼這些問題即可迎刃而解。傳統數字神經網絡的存儲器功耗存在瓶頸,難以實現這一目標。為了解決這一問題,可以將多級存儲器與模擬內存內計算方法結合使用,使處理引擎滿足更低的毫瓦級(mW)到微瓦級(μW)功率要求,從而在網絡邊緣執行AI推斷。
如果通過雲引擎為AI應用提供服務,用戶必須將一些數據以主動或被動方式上傳到雲,計算引擎在雲中處理數據並提供預測,然後將預測結果發送給下游用戶使用。下面概述了這一過程面臨的挑戰:

圖1:從邊緣到雲的數據傳輸
-
隱私問題:對於始終在線始終感知的設備,個人數據和/或機密信息在上傳期間或在數據中心的保存期限內存在遭受濫用的風險。
-
不必要的功耗:如果每個數據位都傳輸到雲,則硬體、無線電、傳輸裝置以及雲中不必要的計算都會消耗電能。
-
小批量推斷的延時:如果數據來源於邊緣,有時至少需要一秒才能收到雲系統的響應。當延時超過100毫秒時,人們便有明顯感知,造成反響不佳的用戶體驗。
-
數據經濟需要創造價值:傳感器隨處可見,價格低廉;但它們會產生大量數據。將每個數據位都上傳到雲進行處理並不划算。
要使用本地處理引擎解決這些挑戰,必須首先針對目標用例利用指定數據集對執行推斷運算的神經網絡進行訓練。這通常需要高性能計算(和存儲器)資源以及浮點算數運算。因此,機器學習解決方案的訓練部分仍需在公共或私有雲(或本地GPU、CPU和FPGA Farm)上實現,同時結合數據集來生成最佳神經網絡模型。神經網絡模型的推斷運算不需要反向傳播,因此在該模型準備就緒之後,可利用小型計算引擎針對本地硬體進行深度優化。推斷引擎通常需要大量乘-累加(MAC)引擎,隨後是激活層(例如修正線性單元(ReLU)、Sigmoid函數或雙曲正切函數,具體取決於神經網絡模型複雜度)以及各層之間的池化層。
大多數神經網絡模型需要大量MAC運算。例如,即使是相對較小的“1.0 MobileNet-224”模型,也有420萬個參數(權重),執行一次推斷需要多達5.69億次的MAC運算。此類模型中的大多數都由MAC運算主導,因此這裡的重點是機器學習計算的運算部分,同時還要尋找機會來創建更好的解決方案。下面的圖2展示了一個簡單的完全連接型兩層網絡。輸入神經元(數據)通過第一層權重處理。第一層的輸出神經元通過第二層權重處理,並提供預測(例如,模型能否在指定圖像中找到貓臉)。這些神經網絡模型使用“點積”運算計算每層中的每個神經元,如下面的公式所示:
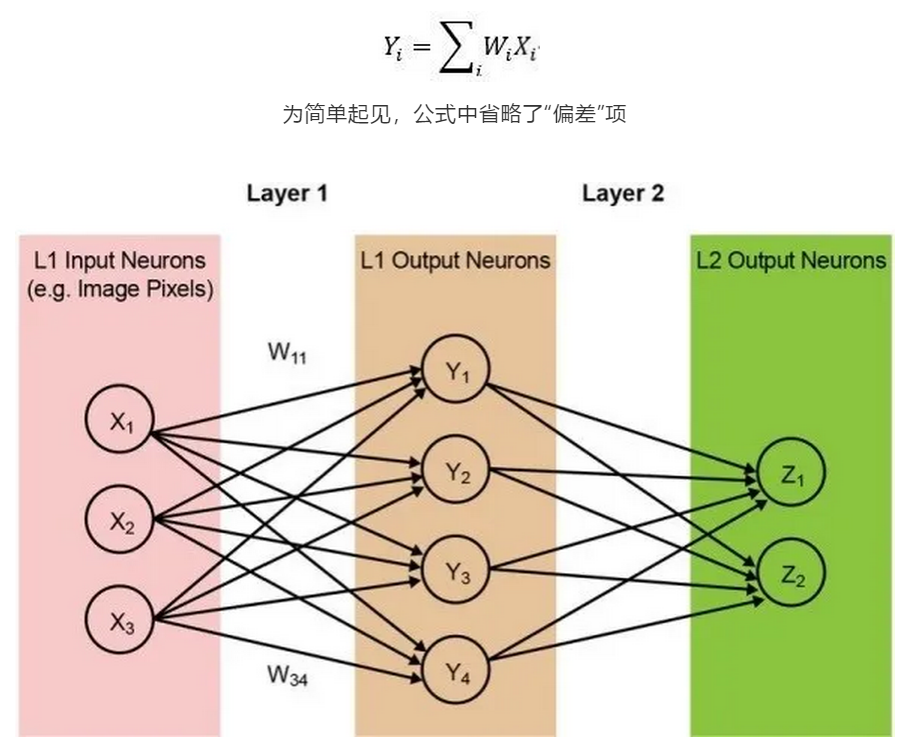
圖2:完全連接的兩層神經網絡
在數字神經網絡中,權重和輸入數據存儲在DRAM/SRAM中。權重和輸入數據需要移至某個MAC引擎旁以進行推斷。根據下圖,採用這種方法後,大部分功耗都來源於獲取模型參數以及將數據輸入到實際發生MAC運算的ALU。從能量角度來看,使用數字邏輯門的典型MAC運算消耗約250 fJ的能量,但在數據傳輸期間消耗的能量超過計算本身兩個數量級,達到50皮焦(pJ)到100 pJ的範圍。公平地說,很多設計技巧可以最大程度減少存儲器到ALU的數據傳輸,但整個數字方案仍受馮·諾依曼架構的限制。這就意味著,有大量的機會可以減少功率浪費。如果執行MAC運算的能耗可以從約100 pJ減少到若干分之幾pJ,將會怎樣呢?
如果存儲器本身可用來消除之前的存儲器瓶頸,則在邊緣執行推斷相關的運算就成為可行方案。使用內存內計算方法可以最大程度地減少必須移動的數據量。這反過來也會消除數據傳輸期間浪費的能源。閃存單元運行時產生的有功功率消耗較低,在待機模式下幾乎不消耗能量,因此可以進一步降低能耗。
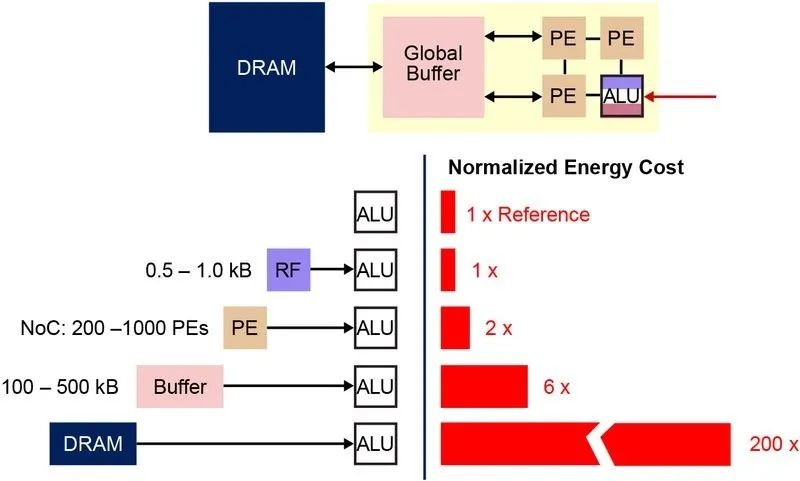
圖3:機器學習計算中的存儲器瓶頸
來源:Y.-H. Chen、J. Emer和V. Sze於2016國際計算機體系結構研討會發表的“Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks”
該方法的一個示例是Microchip子公司Silicon Storage Technology(SST)的memBrain™技術。該解決方案依託於SST的SuperFlash®存儲器技術,這項技術已成為適用於單片機和智慧卡應用的多級存儲器的公認標準。這種解決方案內置一個內存內計算架構,允許在存儲權重的位置完成計算。權重沒有數據移動,只有輸入數據需要從輸入傳感器(例如攝像頭和麥克風)移動到存儲器陣列中,因此消除了MAC計算中的存儲器瓶頸。
這種存儲器概念基於兩大基本原理:(a)電晶體的模擬電流響應基於其閾值電壓(Vt)和輸入數據,(b)基爾霍夫電流定律,即在某個點交匯的多個導體網絡中,電流的代數和為零。了解這種多級存儲器架構中的基本非易失性存儲器(NVM)位單元也十分重要。下圖(圖4)是兩個ESF3(第3代嵌入式SuperFlash)位單元,帶有共用的擦除門(EG)和源線(SL)。每個位單元有五個終端:控制門(CG)、工作線(WL)、擦除門(EG)、源線(SL)和位線(BL)。通過向EG施加高電壓執行位單元的擦除操作。通過向WL、CG、BL和SL施加高/低電壓偏置信號執行編程操作。通過向WL、CG、BL和SL施加低電壓偏置信號執行讀操作。
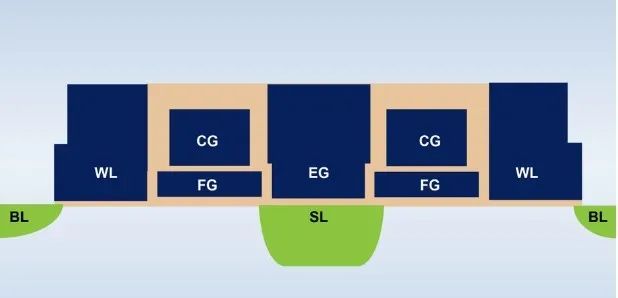
圖4:SuperFlash ESF3單元
利用這種存儲器架構,用戶可以通過微調編程操作,以不同Vt電壓對存儲器位單元進行編程。存儲器技術利用智能算法調整存儲器單元的浮柵(FG)電壓,以從輸入電壓獲得特定的電流響應。根據最終應用的要求,可以在線性區域或閾下區域對單元進行編程。
圖5說明了在存儲器單元中存儲多個電壓的功能。例如,我們要在一個存儲器單元中存儲一個2位整數值。對於這種情況,我們需要使用4個2位整數值(00、01、10、11)中的一個對存儲器陣列中的每個單元進行編程,此時,我們需要使用四個具有足夠間隔的可能Vt值之一對每個單元進行編程。下面的四條IV曲線分別對應於四種可能的狀態,單元的電流響應取決於向CG施加的電壓。
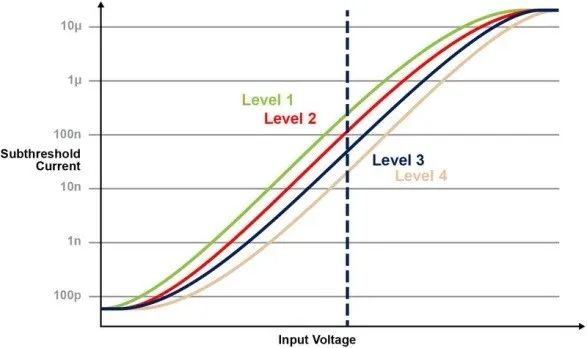
圖5:ESF3單元中的編程Vt電壓
受訓模型的權重通過編程設定為存儲器單元的浮柵Vt。因此,受訓模型每一層(例如完全連接的層)的所有權重都可以在類似矩陣的存儲器陣列上編程,如圖6所示。對於推斷運算,數字輸入(例如來自數字麥克風)首先利用數模轉換器(DAC)轉換為模擬信號,然後應用到存儲器陣列。隨後該陣列對指定輸入向量並行執行數千次MAC運算,產生的輸出隨即進入相應神經元的激活階段,隨後利用模數轉換器(ADC)將輸出轉換回數字信號。然後,這些數字信號在進入下一層之前進行池化處理。
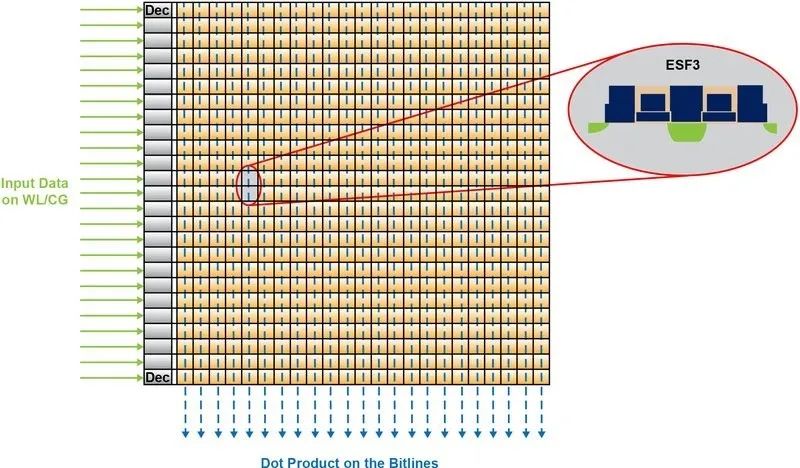
圖6:用於推斷的權重矩陣存儲器陣列
這類多級存儲器架構模塊化程度非常高,而且十分靈活。許多存儲器片可以結合到一起,形成一個混合了權重矩陣和神經元的大型模型,如圖7所示。在本例中,MxN片配置通過各片間的模擬和數字接口連接到一起。
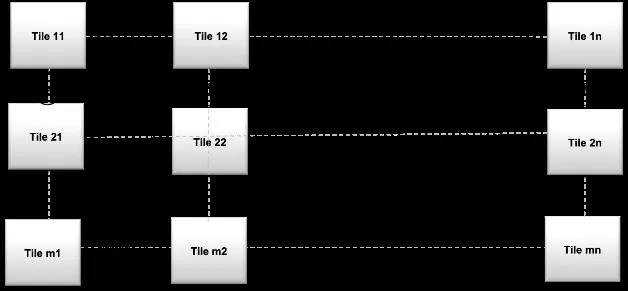
圖7:memBrain™的模塊化結構
截至目前,我們主要討論了該架構的晶片實施方案。提供軟體開發套件(SDK)可幫助開發解決方案。除了晶片外,SDK還有助於推斷引擎的開發。SDK流程與訓練框架無關。用戶可以在提供的所有框架(例如TensorFlow、PyTorch或其他框架)中根據需要使用浮點計算創建神經網絡模型。創建模型後,SDK可幫助量化受訓神經網絡模型,並將其映射到存儲器陣列。在該陣列中,可以利用來自傳感器或計算機的輸入向量執行向量矩陣乘法。
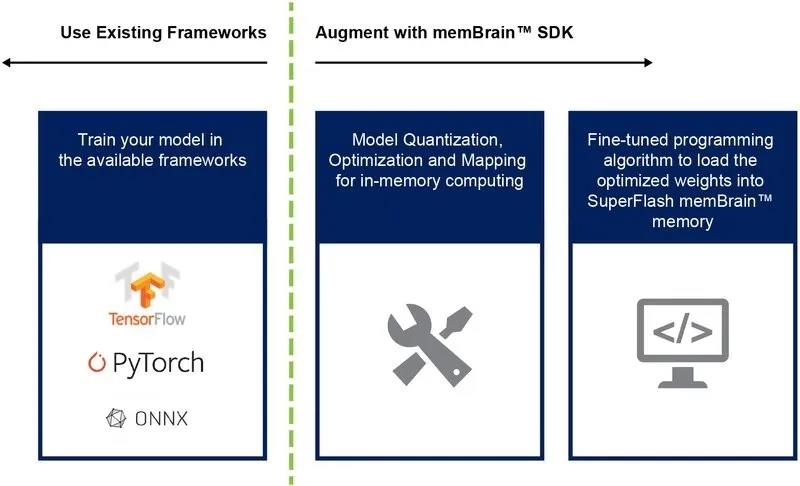
圖8:memBrain™ SDK流程
多級存儲器方法結合內存內計算功能的優點包括:
-
超低功耗:專為低功耗應用設計的技術。功耗方面的第一個優點是,這種解決方案採用內存內計算,因此在計算期間,從SRAM/DRAM傳輸數據和權重不會浪費能量。功耗方面的第二個優點是,閃存單元在閾下模式下以極低的電流運行,因此有功功率消耗非常低。第三個優點是待機模式下幾乎沒有能耗,原因是非易失性存儲器單元不需要任何電力即可保存始終開啟設備的數據。這種方法也非常適合對權重和輸入數據的稀疏性加以利用。如果輸入數據或權重為零,則存儲器位單元不會激活。
-
減小封裝尺寸:該技術採用分離柵(1.5T)單元架構,而數字實施方案中的SRAM單元基於6T架構。此外,與6T SRAM單元相比,這種單元是小得多。另外,一個單元即可存儲完整的4位整數值,而不是像SRAM單元那樣需要4*6 = 24個電晶體才能實現此目的,從本質上減少了片上占用空間。
-
降低開發成本:由於存儲器性能瓶頸和馮·諾依曼架構的限制,很多專用設備(例如Nvidia的Jetsen或Google的TPU)趨向於通過縮小几何結構提高每瓦性能,但這種方法解決邊緣計算難題的成本卻很高。採用將模擬內存內計算與多級存儲器相結合的方法,可以在閃存單元中完成片上計算,這樣便可使用更大的幾何尺寸,同時降低掩膜成本和縮短開發周期。
邊緣計算應用的前景十分廣闊。然而,需要首先解決功耗和成本方面的挑戰,邊緣計算才能得到發展。使用能夠在閃存單元中執行片上計算的存儲器方法可以消除主要障礙。這種方法利用經過生產驗證的公認標準類型多級存儲器技術解決方案,而這種方案已針對機器學習應用進行過優化。