

前言
嬰兒哭聲檢測(Baby Cry Detection)是智慧家庭與嬰兒監護設備中非常實用的一種聲音AI應用。傳統方法需要自行收集音訊檔案、設計前處理流程和深度學習模型,不僅耗時,還需要相當多的機器學習背景知識。
Infineon 推出的DEEPCRAFT™工作室以及其內建的工作室加速器提供了從資料、前處理到模型架構的一站式模板。開發者只需選擇合適的加速器,就能快速建立專案、訓練與調整模型,最後再匯出到 PSoC™ Edge 等 MCU 平台上運行。
本文以嬰兒哭聲檢測(Studio Accelerator)以此為例,簡單介紹 DEEPCRAFT Studio 中 BabyCry 模型專案的各個方面,並配合實際畫面說明專案建立流程、資料集結構、前處理設定與模型架構,讓讀者能夠快速了解這個模板所能帶來的幫助與可調整的空間。
建立 Baby Cry Detection 專案
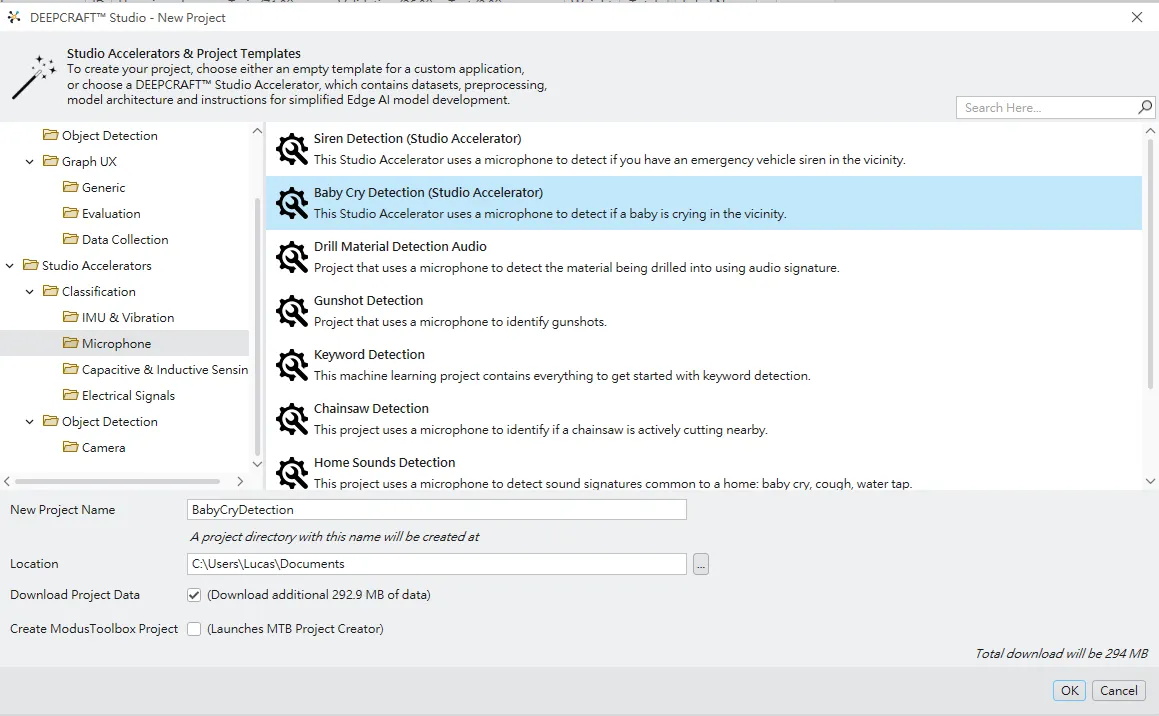
這顯示的是 New Project 視窗。左側是各種 Studio Accelerators 與 Project Templates 的分類樹狀圖,已經展開到:
工作室加速器 → 分類 → 麥克風。
在右側列表中可以看到多種以麥克風為輸入的範例,例如 Siren Detection、Gunshot Detection、Chainsaw Detection 等,其中選取的是「Baby Cry Detection (Studio Accelerator)」,其說明文字指出這個範例會使用麥克風來檢測環境中是否有嬰兒哭聲。
下方可以設定 New Project Name(此處為 BabyCryDetection)、專案儲存路徑,以及是否下載模板所需的資料集(Download Project Data 選項)。螢幕右下角顯示此次建立專案預計會下載約 294 MB 的資料。透過這個模板,開發者無需從零開始收集和整理音訊檔案,就能直接進入模型開發流程。
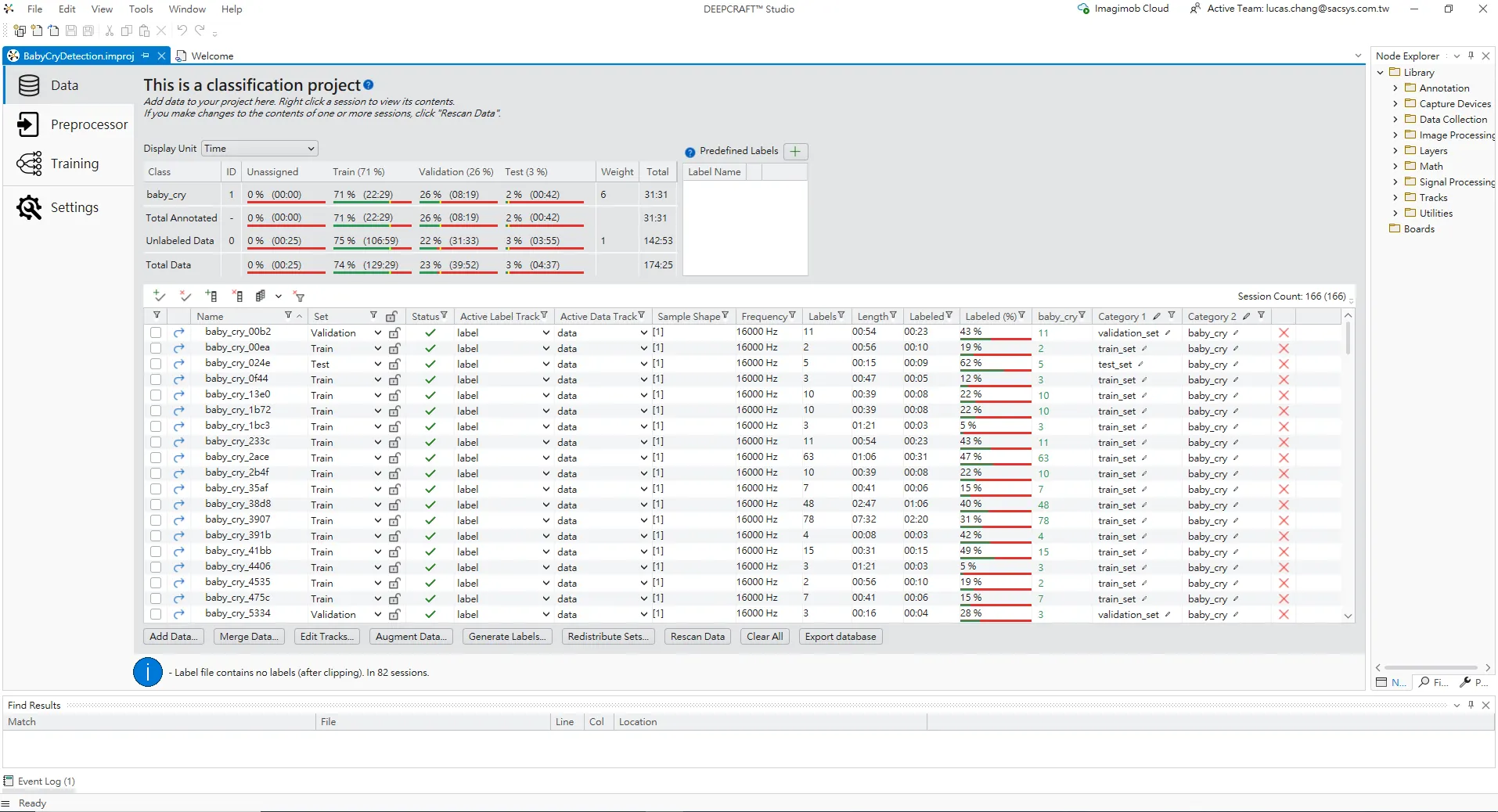
資料集與標註概況
專案建立後,在 Data 分頁下看到的介面。上方區域顯示這是一個「分類專案」,目前只有一個類別 baby_cry。表格中統計了:
訓練集 / 驗證集 / 測試集三種資料集的時間長度比例
每個集合中已標註與未標註的秒數
數據總長度(Total)與權重(Weight)
紅色框線處可以看到,Total Data 中約有七成時間用於訓練集,其餘分配在驗證與測試,方便訓練與評估模型效能。
下方的大表格列出了每一段音訊檔案(Session)的詳細資訊:
名稱:例如 baby_cry_00b2、baby_cry_24ac 等
集合:資料屬於訓練集 / 驗證集 / 測試集
採樣形狀/頻率:均為單聲道、16 kHz 採樣率
長度:每段錄音的總時間
標註 (%):這段音訊中實際被標註為事件(嬰兒哭聲)的比例
類別 1 / 類別 2:對應的類別與數據集標記(train_set, test_set, validation_set / baby_cry)
透過這個介面,使用者可以快速掌握整個資料庫的規模、每個 session 的長度以及標註完整度,如有需要也可以在這裡進行資料重新切分或補充標註。
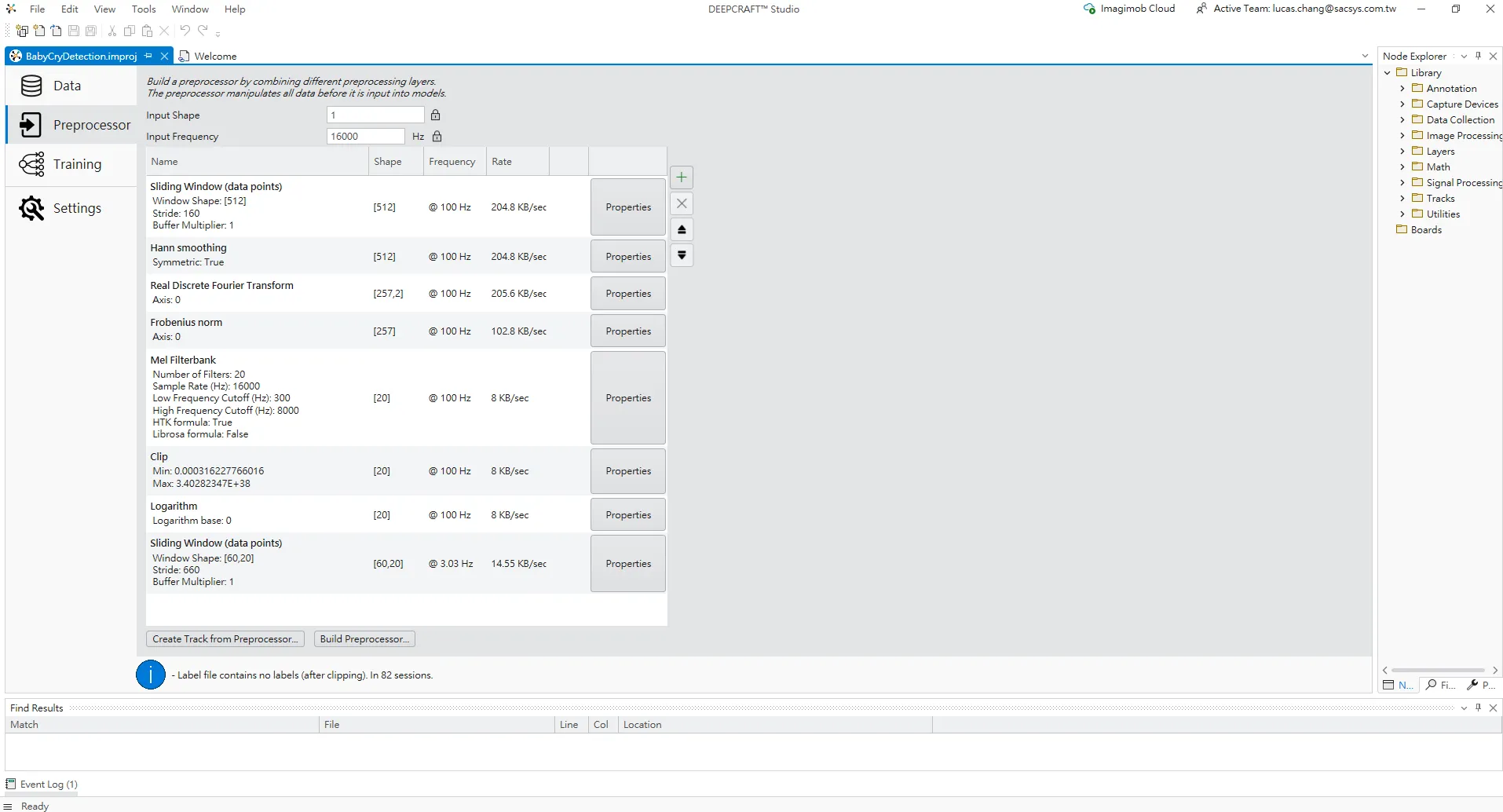
前處理(Preprocessor)流程
Preprocessor 分頁。左側是前處理管線中的各個步驟,依次包含:
滑動視窗(數據點)– 以固定的視窗大小和步距將原始波形切分成一段一段的框架。
Hann 平滑處理 – 應用 Hann 窗口,減少邊界效應。
實數離散傅立葉變換 – 將時域信號轉換為頻域表示。
Frobenius範數——對頻譜進行能量計算。
Mel濾波器組 – 應用20個Mel濾波器,將頻率轉換到更符合人耳感知的Mel頻率軸。
Clip – 將數值限制在一定範圍內,避免極端值。
對數 – 對特徵取對數,使數值分佈更平滑。
滑動視窗(數據點)——再次通過時間視窗將特徵堆疊成二維時頻圖像,供後續 CNN 使用。
畫面上方可以看到輸入形狀與輸入頻率(Input Shape = 1、Input Frequency = 16000),右側則顯示每一層的輸出形狀、產生頻率與數據率。這個預設流程實際上就是幫助使用者建立一個適合音訊分類的時頻特徵(類似 log-Mel spectrogram),避免從零開始設計複雜的 DSP 流程。
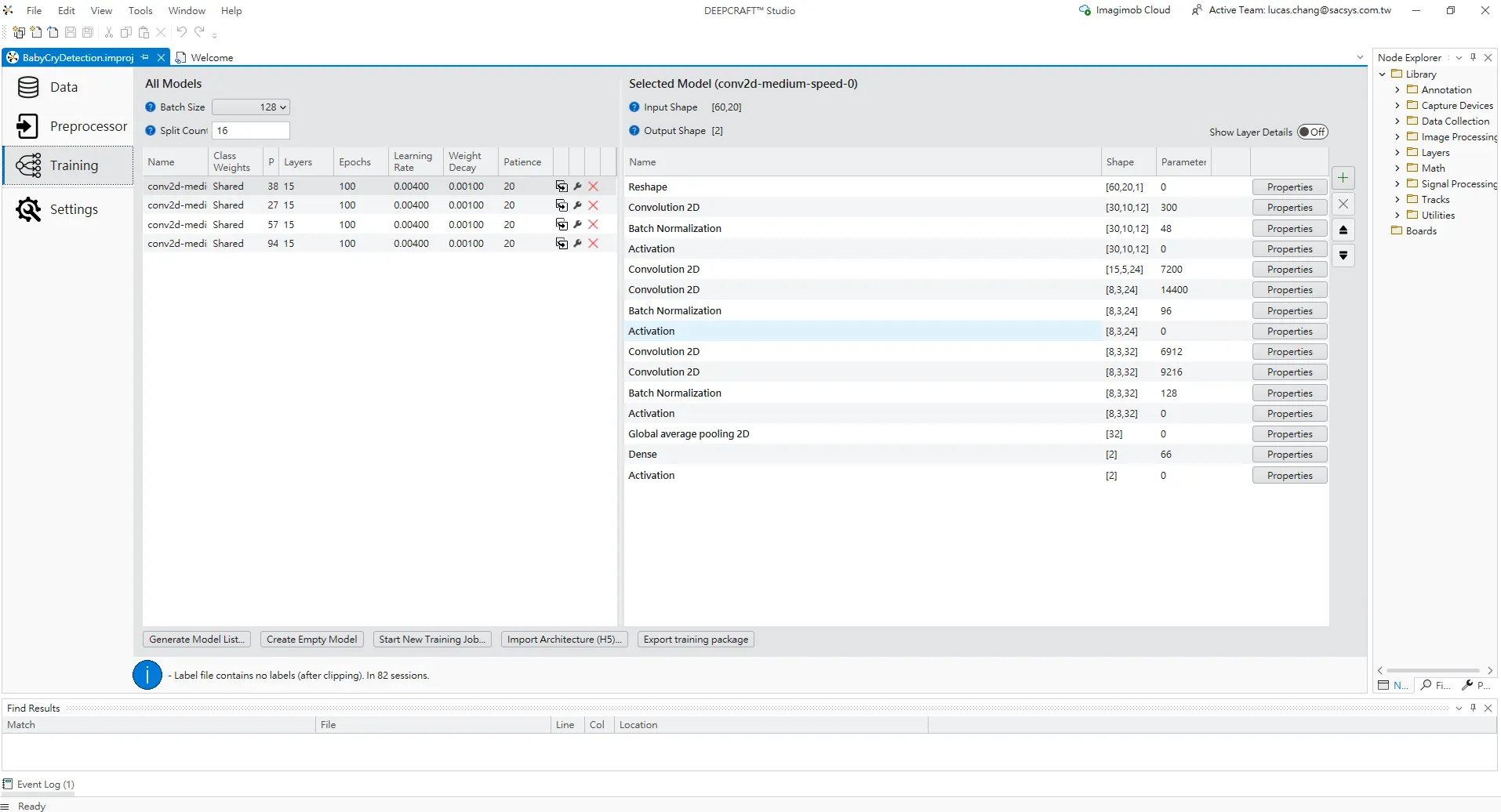
Training 頁面 — BabyCry CNN 模型設定與結構
DEEPCRAFT Studio 專案中的 Training 頁面,用於設定和查看 Baby Cry 專案的訓練模型。
左上角 All Models 區塊:
Batch Size 設定為 128,代表每次訓練更新參數時會一次處理 128 個樣本。
Split Count 為 16,表示訓練時會將資料切成 16 個分割批次來處理。
下方表格列出了所有可用的模型組合,例如 conv2d-medi...(中等大小的 2D CNN 模型),每一列顯示:
類別權重(此處為 Shared,表示使用共享類別權重)
P:模型的參數量(例如 38、27、57、94 等)
層數:層數(均為15層)
Epochs:預計訓練的週期數(100)
學習率:學習率(0.004)
權重衰減:Weight Decay(0.001)
耐心:早停條件的耐心次數(20)
右側 Selected Model 區塊:
上方顯示當前選擇的模型(例如 conv2d-medium-speed-0)的 Input Shape = [60,20]、Output Shape = [2],對應二分類輸出。
下方列表是模型的實際層級結構:
首先使用 Reshape 將預處理後的特徵重塑為 2D 圖像;
接著多層 Convolution 2D → Batch Normalization → Activation 交錯堆疊,負責提取時頻特徵;
再通過 Global average pooling 2D 將特徵圖縮成向量;
最後通過 Dense 全連接層與輸出 Activation 層生成二元分類結果(是否有嬰兒哭聲)。
總體來說,在 BabyCryDetection 專案中如何選擇不同的 CNN 模型版本,以及其中一個 conv2d-medium-speed 模型的具體網路架構。
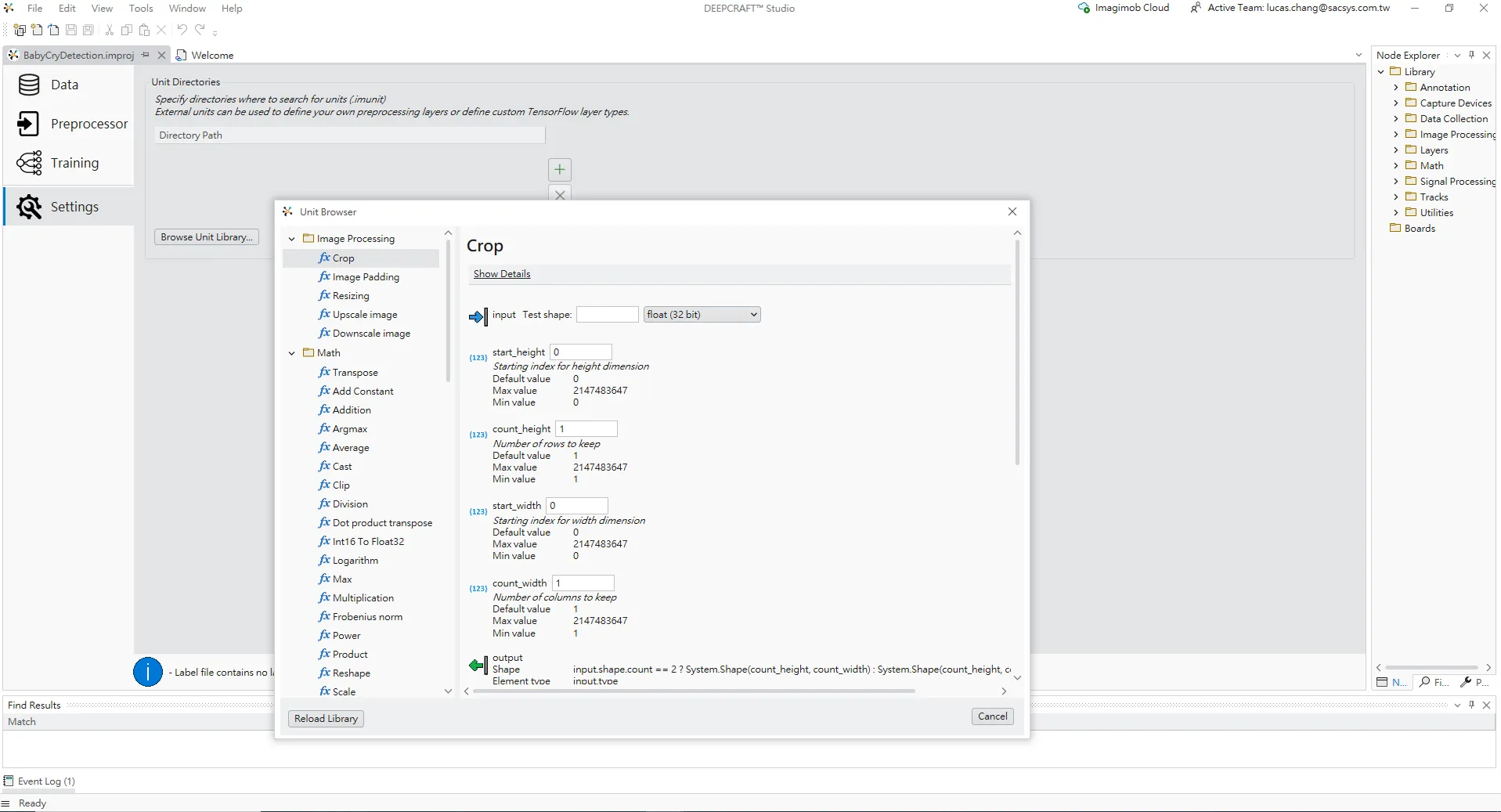
單元瀏覽器與自訂前處理單元
Settings 分頁中的 Unit Browser 視窗。背景顯示的是 Unit Directories 設定,前景視窗則是瀏覽可用的 processing units。左側有不同分類,例如 Image Processing、Math 等。
畫面中已選擇 Image Processing → Crop 單元,右側顯示其可調整參數:
start_height / count_height:在高度(行)方向的起始位置與保留的行數
start_width / count_width:在寬度(columns)方向的起始位置與保留的列數
這些設定說明 DEEPCRAFT Studio 並不侷限於預設的 pipeline,開發者可以透過 Unit Browser 將額外的運算元件加入到前處理或模型中,以滿足更高階的特徵切割、資料增強或模型客製化需求。
結論
透過 Infineon DEEPCRAFT Studio 的 Baby Cry Detection Studio Accelerator,開發者可以在極短的時間內完成一個可用的嬰兒哭聲檢測模型。
從模板快速建立專案並自動獲取資料集;在 Data 頁面查看並管理標註品質以及訓練/驗證/測試的分配。
使用預先設計好的音訊前處理流程生成適合 CNN 的時頻特徵;在 Training 頁面中,使用者可以一次查看多個 conv2d-medium-speed 模型的訓練參數(包括 batch size、epochs、learning rate 等),並展開其中一個模型的網路結構,看到由 Reshape、連續多層 Convolution 2D+Batch Normalization+Activation、Global Average Pooling,再到最終 Dense 輸出層所組成的輕量化 2D CNN,以便針對推理速度與準確率進行調整與比較。
通過 Unit Browser 添加額外單元,自訂前處理或模型架構。
對於希望在 Edge 設備上實現聲音 AI 應用的工程師而言,DEEPCRAFT Studio 不僅提供完整的工具鏈,還內建了實戰經驗累積的最佳實踐範本。以 BabyCry 模型為起點,使用者可以很快地將整套流程遷移或延伸到其他場景,例如寵物叫聲檢測、家電異音檢測或工業設備故障聲音監測,讓 AI 在更多真實場景中發揮價值。
評論