

前言
大多現在文件範例中都還是使用非常舊版(yolov5 甚至 v3)的模型進行即時偵測,本篇博文是關於如何自行將state-of-the-art(SOTA)的模型實作在聯詠 NT9852x 晶片上。
尋找state-of-the-art(SOTA)的模型修改sample code 以便客戶參考,並將其移植到聯詠晶片上運行。
本文
流程圖
使用模型: yolov11n
- 來源: https://docs.ultralytics.com/zh/models/yolo11
- 使用其中的 pytorch 模型,轉換成 onnx
基於 NT9852x 晶片提供的 0.75 TOPS 專用 CNN 加速能力,並假設目標為 30 FPS 即時性能,理論上只有 YOLOv11n (6.5 B FLOPs) 和 YOLOv11s (21.5 B FLOPs) 這兩個版本能夠在該晶片上運行並滿足即時運算速度的需求。
移除後處理
先看需移除的部份

需才切成下面這樣

說明 :
主要是為了某些 Operator 不要因為經過量化導致出問題, 通常會需要將後處理拉出來,是因為在 ONNX 模型最後一層 Convolution 之後,會接上如 sigmoid / softmax 這類對數值分布敏感的非線性函數。在量化後(尤其 INT8),這些函數的輸入值若經過縮放與截斷,容易造成飽和或精度損失(例如 sigmoid 輸入範圍太大導致輸出接近 0 或 1)。因此我們通常會將後處理(sigmoid / softmax / NMS / decode 等)拉出來於 host 端執行,以避免精度下降。
驗證後處理 :
驗證後處理實需將切除部份接回來這裡會驗證三個部份 :
- 未裁切版本 :
- 裁切後處理版本 :
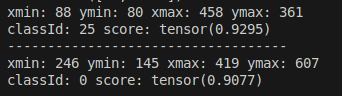

與原本未裁切版本 相比 是一樣結果 代表後處理部份完成
這裡附上後處理驗證程式碼 :
#!/usr/bin/env python3 # -*- coding:utf-8 -*- import argparse import os import sys import os.path as osp import cv2 import torch import numpy as np import onnx from onnx import helper, TensorProto import onnxruntime as ort from math import exp ROOT = os.getcwd() if str(ROOT) not in sys.path: sys.path.append(str(ROOT)) CLASSES = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'] class_num = len(CLASSES) head_num = 3 nms_thresh = 0.3 object_thresh = 0.3 strides = [8, 16, 32] input_height = 640 input_width = 640 anchors = int(input_height / strides[0] * input_width / strides[0] + input_height / strides[1] * input_width / strides[1] + input_height / strides[2] * input_width / strides[2]) print("anchors:", anchors) class DetectBox: def __init__(self, classId, score, xmin, ymin, xmax, ymax): self.classId = classId self.score = score self.xmin = xmin self.ymin = ymin self.xmax = xmax self.ymax = ymax def IOU(xmin1, ymin1, xmax1, ymax1, xmin2, ymin2, xmax2, ymax2): xmin = max(xmin1, xmin2) ymin = max(ymin1, ymin2) xmax = min(xmax1, xmax2) ymax = min(ymax1, ymax2) innerWidth = xmax - xmin innerHeight = ymax - ymin innerWidth = innerWidth if innerWidth > 0 else 0 innerHeight = innerHeight if innerHeight > 0 else 0 innerArea = innerWidth * innerHeight area1 = (xmax1 - xmin1) * (ymax1 - ymin1) area2 = (xmax2 - xmin2) * (ymax2 - ymin2) total = area1 + area2 - innerArea return innerArea / total def NMS(detectResult): predBoxs = [] sort_detectboxs = sorted(detectResult, key=lambda x: x.score, reverse=True) for i in range(len(sort_detectboxs)): xmin1 = sort_detectboxs[i].xmin ymin1 = sort_detectboxs[i].ymin xmax1 = sort_detectboxs[i].xmax ymax1 = sort_detectboxs[i].ymax classId = sort_detectboxs[i].classId if sort_detectboxs[i].classId != -1: predBoxs.append(sort_detectboxs[i]) for j in range(i + 1, len(sort_detectboxs), 1): if classId == sort_detectboxs[j].classId: xmin2 = sort_detectboxs[j].xmin ymin2 = sort_detectboxs[j].ymin xmax2 = sort_detectboxs[j].xmax ymax2 = sort_detectboxs[j].ymax iou = IOU(xmin1, ymin1, xmax1, ymax1, xmin2, ymin2, xmax2, ymax2) if iou > nms_thresh: sort_detectboxs[j].classId = -1 return predBoxs def postprocess(outputs, image_h, image_w): # print('postprocess ... ') scale_h = image_h / input_height scale_w = image_w / input_width detectResult = [] output = outputs[0] for i in range(0, anchors): cls_index = 0 cls_vlaue = -1 for cl in range(class_num): val = output[i + (4 + cl) * anchors] if val > cls_vlaue: cls_vlaue = val cls_index = cl if cls_vlaue > object_thresh: cx = output[i + 0 * anchors] cy = output[i + 1 * anchors] cw = output[i + 2 * anchors] ch = output[i + 3 * anchors] xmin = (cx - 0.5 * cw) * scale_w ymin = (cy - 0.5 * ch) * scale_h xmax = (cx + 0.5 * cw) * scale_w ymax = (cy + 0.5 * ch) * scale_h box = DetectBox(cls_index, cls_vlaue, xmin, ymin, xmax, ymax) detectResult.append(box) # NMS # print('detectResult:', len(detectResult)) predBox = NMS(detectResult) return predBox def precess_image(img_src, resize_w, resize_h): image = cv2.resize(img_src, (resize_w, resize_h), interpolation=cv2.INTER_LINEAR) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = image.astype(np.float32) image /= 255.0 return image def detect(img_path): orig = cv2.imread(img_path) img_h, img_w = orig.shape[:2] image = precess_image(orig, input_height, input_width) image = image.transpose((2, 0, 1)) image = np.expand_dims(image, axis=0) # print("image: ", image) ort_session = ort.InferenceSession('input/model/yolov11nNoPostProcess.onnx') pred_results = (ort_session.run(None, {'images': image})) outputs = [] pred_result_1_ConV = pred_results[1] pred_result_2_Sigmoid = pred_results[0] # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~Sigmoid~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # 將 NumPy 陣列轉換為 PyTorch 張量 pred_result_2_Sigmoid_tensor = torch.from_numpy(pred_result_2_Sigmoid).float() processed_Sigmoid_output = torch.sigmoid(pred_result_2_Sigmoid_tensor) # print("processed_output shape:", processed_Sigmoid_output.shape) # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~Sigmoid~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ConVProcess~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # 將 NumPy 陣列轉換為 PyTorch 張量 pred_result_1_ConV_tensor = torch.from_numpy(pred_result_1_ConV).float() reshaped = pred_result_1_ConV_tensor.reshape(1, 4, 8400) # print("reshaped shape:", reshaped.shape) # Shape shape = torch.tensor(reshaped.shape) # Gather indices = torch.tensor([1]) gathered = shape[indices] # gathered.item() = 4 # Add b1 = torch.tensor([1]) # 這裡的 b1 是一個張量,值為 1 added = gathered + b1 # 結果 added.item() = 5 # Div b2 = torch.tensor([2]) # 這裡的 b2 是一個張量,值為 2 divided = added / b2 # 結果 divided.item() = 2.5 # Mul(左路徑) b3 = torch.tensor([1]) # 這裡的 b3 是一個張量,值為 1 mul_left = divided * b3 # mul_left.item() = 2.5 # Mul(右路徑) b4 = torch.tensor([2]) # 這裡的 b4 是一個張量,值為 2 mul_right = divided * b4 # mul_right.item() = 5.0 # Step 3: 左Slice sliced_left = reshaped[:, 0:int(mul_left.item()), :] # 從 channel 0 到 2,不含 2,即取 channel 0, 1 # Step 4: 右Slice sliced_right = reshaped[:, int(mul_left.item()):int(mul_right.item()), :] # 從 channel 0 到 2,不含 2,即取 channel 0, 1 # x_centers: 每個 grid cell 的 x index + 0.5 x_centers = [] y_centers = [] for feat_w, feat_h in [(80,80), (40,40), (20,20)]: for y in range(feat_h): for x in range(feat_w): x_centers.append(x + 0.5) y_centers.append(y + 0.5) x_centers = torch.tensor(x_centers).reshape(1, 1, 8400) # [1, 1, 8400] y_centers = torch.tensor(y_centers).reshape(1, 1, 8400) # [1, 1, 8400] constant_9 = torch.cat([x_centers, y_centers], dim=1) # [1, 2, 8400] # constant_9 是預先建立好的 [1, 2, 8400] sub_result = constant_9 - sliced_left # 最後 shape: [1, 2, 8400] add_result = constant_9 + sliced_right # 最後 shape: [1, 2, 8400] sub_operation = add_result - sub_result # [1, 2, 8400] add_operation = sub_result + add_result # [1, 2, 8400] # Div b5 = 2 add_divided = add_operation / b5 # 結果 [2] # Concat concat_result = torch.cat([add_divided, sub_operation], dim=1) # [1, 4, 8400] # Mul B <1 x 8400> [8, 8, 8, 8,...., 16, 16, 16, 16,...., 32, 32, 32, 32] 陣列內有 6400個8, 1600個16, 400個32 b6 = torch.tensor([8] * 6400 + [16] * 1600 + [32] * 400).reshape(1, 8400) mul_result = concat_result * b6 # 結果 [1, 4, 8400] # Concat Sigmoid & Mul_result concat_result = torch.cat([mul_result, processed_Sigmoid_output], dim=1) # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ConVProcess~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ for i in range(len(concat_result)): print(concat_result[i].shape) outputs.append(concat_result[i].reshape(-1)) predbox = postprocess(outputs, img_h, img_w) # print('obj num is :', len(predbox)) for i in range(len(predbox)): xmin = int(predbox[i].xmin) ymin = int(predbox[i].ymin) xmax = int(predbox[i].xmax) ymax = int(predbox[i].ymax) classId = predbox[i].classId score = predbox[i].score print('xmin:', xmin, 'ymin:', ymin, 'xmax:', xmax, 'ymax:', ymax) print('classId:', classId, 'score:', score) print('-----------------------------------') cv2.rectangle(orig, (xmin, ymin), (xmax, ymax), (255, 0, 0), 2) ptext = (xmin, ymin) title = CLASSES[classId] + "%.2f" % score cv2.putText(orig, title, ptext, cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 1, cv2.LINE_AA) cv2.imshow('result', orig) cv2.waitKey(0) cv2.imwrite('yolov11n/NoPostPross_onnx_result.jpg', orig) if __name__ == '__main__': # print('This is main ....') img_path = 'input/data/test_jpg/000000442306.jpg' detect(img_path)
- 未裁切版本 :
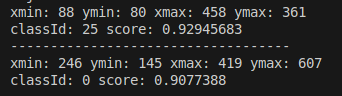

模擬測試 :
- 這部份是指經由 Nova 原廠 SDK docker環境模擬板端測試偵測 並 量化轉成nvt_model.bin
在經由量化工具 gen / sim tool 執行後過後, 可以在 output 資料夾內 找到對應 onnx模型 輸出的bin檔
以上述yolov11為例 可得兩個輸出bin檔 :
- 對應著 Conv後的輸出 及 Sigmoid 後的輸出
- input/output/yolov11n/debug/golden_tensor/Conv__model.23_dfl_conv_Conv_output_0_Y.bin
- input/output/yolov11n/debug/golden_tensor/Split__model.23_Split_output_1_Y.bin
這邊能夠在利用上述2個bin檔 去取代onnx跑驗證程式碼
# 讀取 conv_output with open("input/output/yolov11n/debug/golden_tensor/Conv__model.23_dfl_conv_Conv_output_0_Y.bin", "rb") as f: conv_data = np.fromfile(f, dtype=np.float32) pred_result_1_ConV = conv_data.reshape(1, 4, 8400) # 讀取 sigmoid_output with open("input/output/yolov11n/debug/golden_tensor/Split__model.23_Split_output_1_Y.bin", "rb") as f: sigmoid_data = np.fromfile(f, dtype=np.float32) pred_result_2_Sigmoid = sigmoid_data.reshape(1, 80, 8400)經過這段程式碼後能夠驗證 量化時測試用的影像得到的output.bin檔是否正確
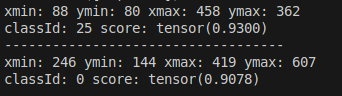

可以觀察到 與 先前的結果一致, 表示量化後的模型沒有問體
修改範例程式
這邊比較多需要注意的
Stream 配置
- stream[0]:main,對應 set_proc_param。
- stream[1]:sub,對應 set_proc_param_extend。
- stream[2]:sub2,對應 set_proc_param_extend。
範例:
ret = set_proc_param_extend(stream[2].proc_path, SOURCE_PATH, NULL, &sub2_dim, HD_VIDEO_DIR_NONE, 1);
在sample code中 還需要注意
- 記憶池類型
- HD_COMMON_MEM_POOL_TYPE:
- HDAL 內部記憶池。
- 使用者定義記憶池。
帶 DISP 的 pool(如 HD_COMMON_MEN_DISPx_IN_POOL):
- 與顯示相關,為 HD_VIDEOPROCESS 的 output buffer,指向 LCD 或 HDMI。
觀察sample code中某些block, 指定 net 使用 DDR_ID1
// config common pool (in) p_mem_cfg->pool_info[i].type = HD_COMMON_MEM_CNN_POOL; p_mem_cfg->pool_info[i].blk_size = p_net->net_cfg.binsize; p_mem_cfg->pool_info[i].blk_cnt = 1; p_mem_cfg->pool_info[i].ddr_id = DDR_ID1;- 與顯示相關,為 HD_VIDEOPROCESS 的 output buffer,指向 LCD 或 HDMI。
其中最主要修改的區域是 network_sync_start 中的 network_proc_thread
static VOID *network_proc_thread(VOID *arg) { const char *CLASSES[80] = { "person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch", "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush" }; HD_RESULT ret = HD_OK; VIDEO_LIVEVIEW *p_stream = (VIDEO_LIVEVIEW*)arg; static struct timeval tstart, tend; printf("\r\n"); while (p_stream->net_proc_start == 0) sleep(1); //~~~~~~~~~~~~~~~~~~~~~modify by yolov11n~~~~~~~~~~~~~~~~~~~~~ // 解讀模型output layer name 並利用 p_stream->net_path (proc_id) 使 layer_buffer 有值 // get nn layer 0 info network_get_ai_inputlayer_info(p_stream->net_path); CHAR out_layer_name[2][128] = {"Mul_custom_output_2_Y", "Conv_output_0_Y"}; // modify yolov11n UINT32 outlayer_num = 0; UINT32 outlayer_path_list[256] = {0}; UINT32 outlayer_path_list_tmp[256] = {0}; network_get_ai_outlayer_list(p_stream->net_path, &outlayer_num, outlayer_path_list_tmp); printf("output layer number: %d\r\n", outlayer_num); memcpy(outlayer_path_list, outlayer_path_list_tmp, sizeof(UINT32) * outlayer_num); for(UINT32 i = 0; i < outlayer_num; i++) { VENDOR_AI_BUF layer_tmp; network_get_ai_outlayer_by_path_id(p_stream->net_path, outlayer_path_list_tmp[i], &layer_tmp); printf("%d %hd %s\r\n", i, outlayer_path_list_tmp[i], layer_tmp.name); for(UINT32 k = 0; k < outlayer_num; k++) { if(strncmp(out_layer_name[k], layer_tmp.name, strlen(out_layer_name[k])) == 0) { outlayer_path_list[k] = outlayer_path_list_tmp[i]; //printf(" --> %d %s \r\n", k, conf_loc_layer_name[k]); break; } } } VENDOR_AI_BUF *layer_buffer = (VENDOR_AI_BUF *)malloc(outlayer_num * sizeof(VENDOR_AI_BUF)); FLOAT **out_layer_float = (FLOAT **)malloc(outlayer_num * sizeof(FLOAT)); // ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~out_tensor_fixed 為 out_layer_float的後處理輸出~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ FLOAT **out_tensor = (float **)malloc(84 * sizeof(float *)); for (int i = 0; i < (CONV_CHANNELS + SIG_CHANNELS); ++i) { out_tensor[i] = (float *)malloc(GRID_CELLS * sizeof(float)); } // 你需要將 float** 轉換成 float[84][8400] 的樣子來使用 FLOAT (*out_tensor_fixed)[GRID_CELLS] = (float (*)[GRID_CELLS])out_tensor; // ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~out_tensor_fixed 為 out_layer_float的後處理輸出~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ for(UINT32 i = 0; i < outlayer_num; i++){ network_get_ai_outlayer_by_path_id(p_stream->net_path, outlayer_path_list[i], &(layer_buffer[i])); printf(" layer (%s)\n", layer_buffer[i].name); printf(" width (%lu)\n", layer_buffer[i].width); printf(" height (%lu)\n", layer_buffer[i].height); printf(" channel (%lu)\n", layer_buffer[i].channel); UINT32 length = layer_buffer[i].width * layer_buffer[i].height * layer_buffer[i].channel * layer_buffer[i].batch_num; out_layer_float[i] = (FLOAT*) malloc(sizeof(FLOAT) * length); } //~~~~~~~~~~~~~~~~~~~~~modify by yolov11n~~~~~~~~~~~~~~~~~~~~~ printf("\r\n"); while (p_stream->net_proc_exit == 0) { if (1) { gettimeofday(&tstart, NULL); VENDOR_AI_BUF in_buf = {0}; //VENDOR_AI_BUF out_buf = {0}; // VENDOR_AI_POSTPROC_RESULT_INFO out_buf = {0}; // VENDOR_AI_BUF out_buf = {0}; HD_VIDEO_FRAME video_frame = {0}; ret = hd_videoproc_pull_out_buf(p_stream->proc_path, &video_frame, -1); // -1 = blocking mode, 0 = non-blocking mode, >0 = blocking-timeout mode if(ret != HD_OK) { printf("hd_videoproc_pull_out_buf fail (%d)\n\r", ret); goto skip; } //prepare input AI_BUF from videoframe in_buf.sign = MAKEFOURCC('A','B','U','F'); in_buf.width = video_frame.dim.w; in_buf.height = video_frame.dim.h; in_buf.channel = HD_VIDEO_PXLFMT_PLANE(video_frame.pxlfmt); //conver pxlfmt to channel count in_buf.line_ofs = video_frame.loff[0]; in_buf.fmt = video_frame.pxlfmt; in_buf.pa = video_frame.phy_addr[0]; in_buf.va = 0; in_buf.size = video_frame.loff[0]*video_frame.dim.h*3/2; // printf("video_frame.dim.w = %d, video_frame.dim.h = %d, video_frame.pxlfmt = %d\n", video_frame.dim.w, video_frame.dim.h, video_frame.pxlfmt); if (ai_async == 0) { // network_get_ai_inputlayer_info(p_stream->net_path); // set input image ret = vendor_ai_net_set(p_stream->net_path, VENDOR_AI_NET_PARAM_IN(0, 0), &in_buf); if (HD_OK != ret) { printf("proc_id(%u) set input fail !!\n", p_stream->net_path); goto skip; } // do net proc ret = vendor_ai_net_proc(p_stream->net_path); if (HD_OK != ret) { printf("proc_id(%u) proc fail !!\n", p_stream->net_path); goto skip; } //~~~~~~~~~~~~~~~~~~~~~modify by yolov11n~~~~~~~~~~~~~~~~~~~~~ for(UINT32 i = 0; i < outlayer_num; i++) { hd_common_mem_flush_cache((VOID *)layer_buffer[i].va, layer_buffer[i].size); UINT32 length = layer_buffer[i].width * layer_buffer[i].height * layer_buffer[i].channel * layer_buffer[i].batch_num; ret = vendor_ai_cpu_util_fixed2float((VOID *)layer_buffer[i].va, layer_buffer[i].fmt, out_layer_float[i], layer_buffer[i].scale_ratio, length); } // printf("do vendor_ai_cpu_util_fixed2float after\n"); FLOAT *conv_raw = out_layer_float[1]; FLOAT *sig_raw = out_layer_float[0]; yolov11n_postprocess(conv_raw, sig_raw, out_tensor_fixed); FLOAT image_width = 640.0; FLOAT image_height = 640.0; // 檢測結果 Detection *detections = (Detection *)calloc(GRID_CELLS, sizeof(Detection)); UINT32 detection_count = 0; UINT32 Max_boxs = 100; // 處理檢測 // 利用 out_tensor_fixed 進行後處理輸出 process_detections(out_tensor_fixed, in_buf.height, in_buf.width, image_width, image_height, detections, &detection_count, Max_boxs, 0.75, 0.3); // printf("do process_detections after\n"); // printf("detection_count = %d\n", detection_count); // 輸出結果 for (UINT32 i = 0; i < detection_count; i++) { UINT32 class_id = detections[i].class_id; const char *class_name = (class_id < 80) ? CLASSES[class_id] : "unknown"; printf("Output Category: %s (Score: %.2f), [x1, y1, x2, y2]: [%.2f, %.2f, %.2f, %.2f]\n", class_name, detections[i].score, detections[i].x1, detections[i].y1, detections[i].x2, detections[i].y2); } // 釋放記憶體 未釋放 記憶體會爆炸 OOM free(detections); UINT32 frame_id=0; CHAR TXT_FILE[256], YUV_FILE[256]; FILE *fs, *fb; sprintf(TXT_FILE, "/mnt/sd/det_results/AI/txt/%09ld.txt", frame_id); sprintf(YUV_FILE, "/mnt/sd/det_results/AI/yuv/%09ld.bin", frame_id); // 儲存輸入到模型的 video frame // ai_video_path 填入 video process 輸出給 AI 的那一路 path UINT32 yuv_va = 0; HD_VIDEO_FRAME video_frame = {0}; ret = hd_videoproc_pull_out_buf(p_stream->net_path, &video_frame, -1); yuv_va = (UINT32)hd_common_mem_mmap(HD_COMMON_MEM_MEM_TYPE_CACHE, video_frame.phy_addr[0], video_frame.pw[0] * video_frame.ph[0] * 3 / 2); fb = fopen(YUV_FILE, "wb+"); fwrite((UINT8 *)yuv_va, sizeof(UINT8), (video_frame.dim.w * video_frame.dim.h * 3 / 2), fb); fclose(fb); // 儲存模型的預測結果 // obj_num, category, score, xmin, ymin, width, height, obj_id 請自行帶入自己的變數 fs = fopen(TXT_FILE, "w+"); for (UINT32 num = 0; num < detection_count; num++) { UINT32 class_id = detections[num].class_id; const char *class_name = (class_id < 80) ? CLASSES[class_id] : "unknown"; fprintf(fs, "%d %f %d %d %d %d %d\r\n", class_name, detections[num].score, detections[num].x1, detections[num].y1, (detections[num].x2 - detections[num].x1), (detections[num].y2 - detections[num].y1), 0); } fclose(fs); frame_id++; // ~~~~~~~~~~~~~~~~~~~~~modify by yolov11n~~~~~~~~~~~~~~~~~~~~~ } else if (ai_async == 1) { // // do net proc_buf // ret = vendor_ai_net_proc_buf(p_stream->net_path, VENDOR_AI_NET_PARAM_IN(0, 0), &in_buf, VENDOR_AI_NET_PARAM_OUT(VENDOR_AI_MAXLAYER, 0), &out_buf); // if (HD_OK != ret) { // printf("proc_id(%u) proc_buf fail !!\n", p_stream->net_path); // goto skip; // } } ret = hd_videoproc_release_out_buf(p_stream->proc_path, &video_frame); if(ret != HD_OK) { printf("hd_videoproc_release_out_buf fail (%d)\n\r", ret); goto skip; } gettimeofday(&tend, NULL); double time_ms = ((tend.tv_sec - tstart.tv_sec) * 1000000.0 + (tend.tv_usec - tstart.tv_usec)) / 1000.0; printf("Frame processing time (ms): %.3f\n\n", time_ms); // 輸出每幀時間(毫秒) } usleep(100); } skip: return 0; }在主程式中都修改完了進入 yolov11n 功能
process_detections(out_tensor_fixed, in_buf.height, in_buf.width, image_width, image_height, detections, &detection_count, Max_boxs, 0.75, 0.3);yolov11n_layer.c 主要處理 yolov11n後處理 也就是將先前 python 後處理直接搬過來
#include <stdio.h> #include <string.h> #include <pthread.h> #include "hdal.h" #include "hd_type.h" #include "hd_common.h" #include "vendor_ai.h" #include <math.h> #include <stdlib.h> #include "yolov11n_layer.h" #include <sys/time.h> // 預設值 /** * 將 single-batch、conv 頻道數=4、sigmoid 通道數=80、每格點數=8400 的輸入 * 做與原 Python 同樣的後處理,並輸出合併後 84×8400 的結果。 * * @param pred_conv [in] 大小為 [4][8400] 的原始卷積輸出 * @param pred_sig [in] 大小為 [80][8400] 的原始 sigmoid 輸出 * @param out_tensor [out] 大小為 [84][8400] 的結果張量 */ void yolov11n_postprocess( float *pred_conv, // shape: [4 * 8400] float *pred_sig, // shape: [80 * 8400] float out_tensor[CONV_CHANNELS + SIG_CHANNELS][GRID_CELLS] ) { // 1) Sigmoid static float processed_sig[SIG_CHANNELS][GRID_CELLS]; for (int c = 0; c < SIG_CHANNELS; ++c) { for (int i = 0; i < GRID_CELLS; ++i) { processed_sig[c][i] = 1.0f / (1.0f + expf(-pred_sig[c * GRID_CELLS + i])); } } // 2) 固定算術操作 int left_ch = 2; int right_ch = 4; // 3) Slice static float sliced_left[CONV_CHANNELS][GRID_CELLS]; static float sliced_right[CONV_CHANNELS][GRID_CELLS]; for (int c = 0; c < left_ch; ++c) { for (int i = 0; i < GRID_CELLS; ++i) { sliced_left[c][i] = pred_conv[c * GRID_CELLS + i]; } } for (int c = left_ch; c < right_ch; ++c) { for (int i = 0; i < GRID_CELLS; ++i) { sliced_right[c - left_ch][i] = pred_conv[c * GRID_CELLS + i]; } } int sliced_right_ch = right_ch - left_ch; // 4) 建立 center static float x_centers[GRID_CELLS], y_centers[GRID_CELLS]; int idx = 0; int feats[3][2] = {{80, 80}, {40, 40}, {20, 20}}; for (int f = 0; f < 3; ++f) { int fw = feats[f][0], fh = feats[f][1]; for (int y = 0; y < fh; ++y) { for (int x = 0; x < fw; ++x) { x_centers[idx] = x + 0.5f; y_centers[idx] = y + 0.5f; ++idx; } } } // 5) constant_9 static float constant_9[2][GRID_CELLS]; for (int i = 0; i < GRID_CELLS; ++i) { constant_9[0][i] = x_centers[i]; constant_9[1][i] = y_centers[i]; } // 6) sub_result, add_result static float sub_result[2][GRID_CELLS], add_result[2][GRID_CELLS]; for (int c = 0; c < 2; ++c) { for (int i = 0; i < GRID_CELLS; ++i) { float sr = (c < sliced_right_ch) ? sliced_right[c][i] : 0.0f; sub_result[c][i] = constant_9[c][i] - sliced_left[c][i]; add_result[c][i] = constant_9[c][i] + sr; } } // 7) sub_operation, add_operation static float sub_operation[2][GRID_CELLS], add_operation[2][GRID_CELLS]; for (int c = 0; c < 2; ++c) { for (int i = 0; i < GRID_CELLS; ++i) { sub_operation[c][i] = add_result[c][i] - sub_result[c][i]; add_operation[c][i] = add_result[c][i] + sub_result[c][i]; } } // 8) add_divided = add_operation * 0.5 static float add_divided[2][GRID_CELLS]; for (int c = 0; c < 2; ++c) { for (int i = 0; i < GRID_CELLS; ++i) { add_divided[c][i] = add_operation[c][i] * 0.5f; } } // 9) concat1 [4][8400] static float concat1[4][GRID_CELLS]; for (int c = 0; c < 2; ++c) { for (int i = 0; i < GRID_CELLS; ++i) { concat1[c][i] = add_divided[c][i]; concat1[c + 2][i] = sub_operation[c][i]; } } // 10) b6 [8400] static float b6[GRID_CELLS]; for (int i = 0; i < GRID_CELLS; ++i) { if (i < 6400) b6[i] = 8.0f; else if (i < 8000) b6[i] = 16.0f; else b6[i] = 32.0f; } // 11) mul_result [4][8400] static float mul_result[4][GRID_CELLS]; for (int c = 0; c < 4; ++c) { for (int i = 0; i < GRID_CELLS; ++i) { mul_result[c][i] = concat1[c][i] * b6[i]; } } // 12) concat final [84][8400] for (int c = 0; c < 4; ++c) { for (int i = 0; i < GRID_CELLS; ++i) { out_tensor[c][i] = mul_result[c][i]; } } for (int c = 0; c < SIG_CHANNELS; ++c) { for (int i = 0; i < GRID_CELLS; ++i) { out_tensor[c + 4][i] = processed_sig[c][i]; } } } // 計算兩個框的 IoU(參考 bbox_iou) FLOAT compute_iou(FLOAT x1, FLOAT y1, FLOAT x2, FLOAT y2, FLOAT xx1, FLOAT yy1, FLOAT xx2, FLOAT yy2) { FLOAT inter_x1 = fmaxf(x1, xx1); FLOAT inter_y1 = fmaxf(y1, yy1); FLOAT inter_x2 = fminf(x2, xx2); FLOAT inter_y2 = fminf(y2, yy2); FLOAT inter_w = fmaxf(0.0f, inter_x2 - inter_x1); FLOAT inter_h = fmaxf(0.0f, inter_y2 - inter_y1); FLOAT inter_area = inter_w * inter_h; FLOAT area1 = (x2 - x1) * (y2 - y1); FLOAT area2 = (xx2 - xx1) * (yy2 - yy1); FLOAT union_area = area1 + area2 - inter_area + 1e-6f; // 避免除以零 return inter_area / union_area; } // qsort 比較函數(依 score 由高到低排序) int compare_detections(const void *a, const void *b) { // printf("do compare_detections\n"); Detection *detA = (Detection *)a; Detection *detB = (Detection *)b; if (detA->score < detB->score) return 1; else if (detA->score > detB->score) return -1; else return 0; } // 非極大值抑制(參考 non_max_suppression) void non_max_suppression(Detection *detections, UINT32 *detection_count, FLOAT conf_thres, FLOAT nms_thres, UINT32 max_detections, FLOAT image_width, FLOAT image_height) { // 按分數排序 // printf("do non_max_suppression\n"); qsort(detections, *detection_count, sizeof(Detection), compare_detections); int *suppressed = (int *)calloc(*detection_count, sizeof(int)); UINT32 final_count = 0; Detection *final_detections = (Detection *)malloc(*detection_count * sizeof(Detection)); for (UINT32 i = 0; i < *detection_count && final_count < max_detections; i++) { if (suppressed[i]) continue; // 保留當前檢測 // final_detections[final_count] = detections[i]; memcpy(&final_detections[final_count], &detections[i], sizeof(Detection)); // 更安全 // 將正規化座標轉回圖像尺寸 // final_detections[final_count].x1 *= image_width; // final_detections[final_count].y1 *= image_height; // final_detections[final_count].x2 *= image_width; // final_detections[final_count].y2 *= image_height; final_count++; // 對後續檢測進行 IoU 比較 for (UINT32 j = i + 1; j < *detection_count; j++) { if (suppressed[j]) continue; FLOAT iou = compute_iou(detections[i].x1, detections[i].y1, detections[i].x2, detections[i].y2, detections[j].x1, detections[j].y1, detections[j].x2, detections[j].y2); if (iou > nms_thres) { suppressed[j] = 1; } } } // 更新檢測結果 for (UINT32 i = 0; i < final_count; i++) { detections[i] = final_detections[i]; } *detection_count = final_count; free(suppressed); free(final_detections); } // 主處理函數 void process_detections(FLOAT out_tensor_fixed[CONV_CHANNELS + SIG_CHANNELS][GRID_CELLS], int image_h, int image_w, FLOAT image_width, FLOAT image_height, Detection* result_boxes, UINT32* detection_count, UINT32 max_boxes, FLOAT object_thresh, FLOAT nms_thresh) { // Calculate total anchors based on strides const int strides[STRIDES_NUM] = {8, 16, 32}; uint32_t anchors = 0; for (int s = 0; s < STRIDES_NUM; s++) { anchors += (image_height / strides[s]) * (image_width / strides[s]); } // 將 2D 數組視為 1D 數組 FLOAT* output = (FLOAT*)out_tensor_fixed; // Scaling factors FLOAT scale_h = (FLOAT)image_h / 640.0; FLOAT scale_w = (FLOAT)image_w / 640.0; uint32_t box_count = 0; // Process each anchor for (uint32_t i = 0; i < anchors; i++) { // Find max class score and index FLOAT max_score = -1.0f; uint32_t max_class_idx = 0; for (uint32_t c = 0; c < SIG_CHANNELS; c++) { FLOAT score = output[i + (4 + c) * anchors]; if (score > max_score) { max_score = score; max_class_idx = c; } } if (max_score < object_thresh || box_count >= max_boxes) { continue; } // Extract box coordinates FLOAT cx = output[i + 0 * anchors]; FLOAT cy = output[i + 1 * anchors]; FLOAT w = output[i + 2 * anchors]; FLOAT h = output[i + 3 * anchors]; // printf("cx = %f, cy = %f, w = %f, h = %f\n", cx, cy, w, h); // Convert to image coordinates FLOAT xmin = (cx - 0.5f * w) * scale_w; FLOAT ymin = (cy - 0.5f * h) * scale_h; FLOAT xmax = (cx + 0.5f * w) * scale_w; FLOAT ymax = (cy + 0.5f * h) * scale_h; // printf("xmin = %f, ymin = %f, xmax = %f, ymax = %f\n", xmin, ymin, xmax, ymax); // Store result result_boxes[box_count].class_id = max_class_idx; result_boxes[box_count].score = max_score; result_boxes[box_count].x1 = xmin; result_boxes[box_count].y1 = ymin; result_boxes[box_count].x2 = xmax; result_boxes[box_count].y2 = ymax; box_count++; } *detection_count = box_count; // 執行 NMS non_max_suppression(result_boxes, detection_count, object_thresh, nms_thresh, max_boxes, image_width, image_height); }yolov11n_layer.h
/******************************************************************** INCLUDE FILES ********************************************************************/ #include "kflow_ai_net/kflow_ai_net.h" #include "vendor_ai_net/nn_net.h" // 定義檢測結果結構 typedef struct _Detection { UINT32 class_id; FLOAT score; FLOAT x1, y1, x2, y2; } Detection; #define STRIDES_NUM 3 #define CONV_CHANNELS 4 #define SIG_CHANNELS 80 #define GRID_CELLS 8400 void yolov11n_postprocess( float *pred_conv, float *pred_sig, float out_tensor[CONV_CHANNELS + SIG_CHANNELS][GRID_CELLS] ); FLOAT compute_iou(FLOAT x1, FLOAT y1, FLOAT x2, FLOAT y2, FLOAT xx1, FLOAT yy1, FLOAT xx2, FLOAT yy2); int compare_detections(const void *a, const void *b); void non_max_suppression(Detection *detections, UINT32 *detection_count, FLOAT conf_thres, FLOAT nms_thres, UINT32 max_detections, FLOAT image_width, FLOAT image_height); void process_detections(FLOAT out_tensor_fixed[CONV_CHANNELS + SIG_CHANNELS][GRID_CELLS], int image_h, int image_w, FLOAT image_width, FLOAT image_height, Detection* result_boxes, UINT32* detection_count, UINT32 max_boxes, FLOAT object_thresh, FLOAT nms_thresh);
編譯與上板程式
printf("usage : ai_video_liveview_with_net (out_type) (ai_async) (job_opt) (job_sync) (buf_opt)\n");./ai_video_liveview_with_yolov11n 1 0 11 0 0在程式輸出
Output Category: person (Score: 0.84), [x1, y1, x2, y2]: [573.00, -5.48, 1570.50, 1074.52] Frame processing time (ms): 284.621 Output Category: person (Score: 0.84), [x1, y1, x2, y2]: [577.50, 7.17, 1572.00, 1074.52] Frame processing time (ms): 282.542 Output Category: person (Score: 0.78), [x1, y1, x2, y2]: [570.75, 0.00, 1582.50, 1068.61] Frame processing time (ms): 279.544 Output Category: person (Score: 0.84), [x1, y1, x2, y2]: [586.50, 0.00, 1587.75, 1061.44] Frame processing time (ms): 289.171 Output Category: person (Score: 0.78), [x1, y1, x2, y2]: [576.00, 0.00, 1579.50, 1065.66] Frame processing time (ms): 281.126 Output Category: person (Score: 0.84), [x1, y1, x2, y2]: [573.00, 0.00, 1564.50, 1069.03] Frame processing time (ms): 282.137 Output Category: person (Score: 0.89), [x1, y1, x2, y2]: [577.50, -2.53, 1589.25, 1074.52]
💡 常見問題(FAQ)
問題 1:為什麼在移植 YOLOv11 模型到 NT9852x 時,需要移除後處理(如 sigmoid、NMS)?
回答:
因為後處理層(sigmoid、softmax、NMS 等)屬於數值分布敏感的非線性運算,若經過量化(特別是 INT8),輸入值會被縮放與截斷,容易導致輸出飽和或精度嚴重下降。
例如 sigmoid 的輸入若過大,量化後會全部接近 0 或 1,造成物件分數錯判。
因此我們會將後處理移至 host 端(CPU)執行,而僅保留卷積主幹與檢測頭在硬體加速端(CNN accelerator)執行,以兼顧效能與精度。
問題 2:為什麼選擇 YOLOv11n 作為移植目標模型,而不是 YOLOv11s 或更大版本?
回答:
NT9852x 晶片的 CNN 加速器峰值效能約為 0.75 TOPS。
若以 30 FPS 的即時偵測為目標,則能支撐的模型理論上不超過 20 B FLOPs。
YOLOv11n 約為 6.5 B FLOPs,YOLOv11s 約 21.5 B FLOPs。前者能穩定在 30 FPS 執行,後者則需在低分辨率下才可能達標。
因此本實驗選擇 YOLOv11n 作為示範模型。
問題 3:如何驗證後處理移除後的模型結果正確?
回答:
驗證方法是比對「原始未裁切模型」與「裁切後(移除後處理)的模型 + Python 實作後處理」的輸出結果。
若兩者的 bounding box 與分類結果一致,即代表後處理部分在 host 端重現成功。
在文中提供的 Python 範例中,兩者結果圖 相同,即證明後處理正確接回。
問題 4:量化過程中如何確認輸出結果對應 ONNX 模型?
回答:
在 Nova SDK 環境中使用量化工具(gen / sim tool)後,會在 output/debug/golden_tensor/ 目錄中輸出多個 .bin 檔案。
例如:
Conv__model.23_dfl_conv_Conv_output_0_Y.bin ← 對應卷積輸出
Split__model.23_Split_output_1_Y.bin ← 對應 Sigmoid 前輸出
這兩個 .bin 可直接取代 ONNX Runtime 的推論輸出,再接入 Python 的後處理驗證流程,以確保模擬結果與模型一致。
問題 5:這篇流程是否可直接套用到其他 YOLO 系列模型(如 YOLOv8、YOLOv10)?
回答:
可以,但需注意各版本 head 結構與輸出維度不同,例如:
YOLOv8 / YOLOv10 採用 decoupled head,輸出 tensor 結構與 anchor-free 設計不同。
YOLOv11 引入更簡化的 DFL head。
若要套用相同流程,需修改 Python 後處理部分的 tensor reshape 與 decode 運算。
整體概念一致,但輸出層 channel 與 NMS 對應需依模型結構調整。
評論