

►前言
模型合併是近年來興起的新技術。它允許將多個模型合併成一個模型。這樣做不僅可以保持質量,還可以獲得額外的好處。假設我們有幾個模型:一個擅長解決數學問題,另一個擅長寫程式碼。在兩種模型之間切換是一個很麻煩的問題,但是我們可以將它們組合起來,並利用兩者的優點。而這種組合的方法可以不需要GPU來完成。本文將介紹使用Mergekit合併大語言模型,達到模型不需重複訓練的結合效果。
►Mergekit 介紹
MergeKit 是一個開源工具,專門用來 合併多個大型語言模型(LLM),讓開發者可以透過「權重合併」的方式,把不同模型的特性融合在一起,而不需要重新從頭訓練。這個方法的靈感來自於社群流行的「模型合併(model merging)」技術,例如 SLERP、TIES、DARE 等方式。
Mergekit的主要特點包括:
多種合併方法
1. Linear Merge:簡單線性加權平均(常見於 checkpoint 融合)。
2. SLERP Merge(Spherical Linear Interpolation):保持向量角度差異,更平滑的融合。
3. TIES Merge:選擇性地合併權重,避免破壞模型已學到的專長。
4. DARE Merge:引入隨機 dropout,提升模型泛化能力。
高效與模組化
1. 可以只合併 部分層(layer-wise merge),避免整個模型崩壞。
2. 支援 權重比例自訂,方便針對特定下游任務調整。
3. 與 LoRA / Adapter 相容能直接把 LoRA 模型權重合併到基礎模型,避免推理時額外載入 LoRA。
支援不同模型格式
1. Hugging Face Transformers (.bin, .safetensors)
2. GGUF (量化模型)
3. 支援 Llama、Mistral 等主流架構。
►操作流程
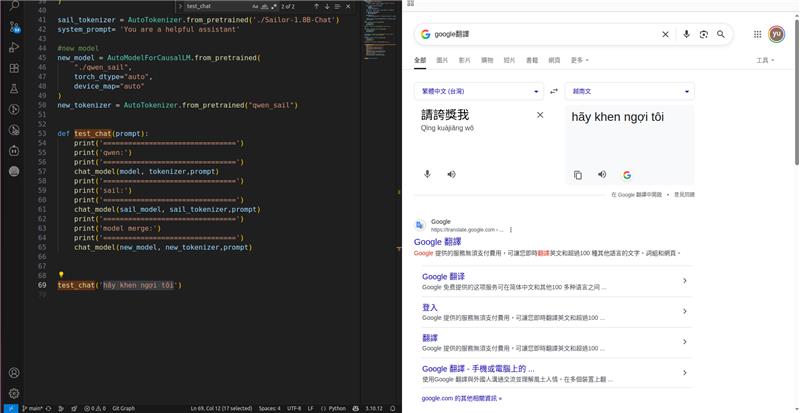
定義config.yaml
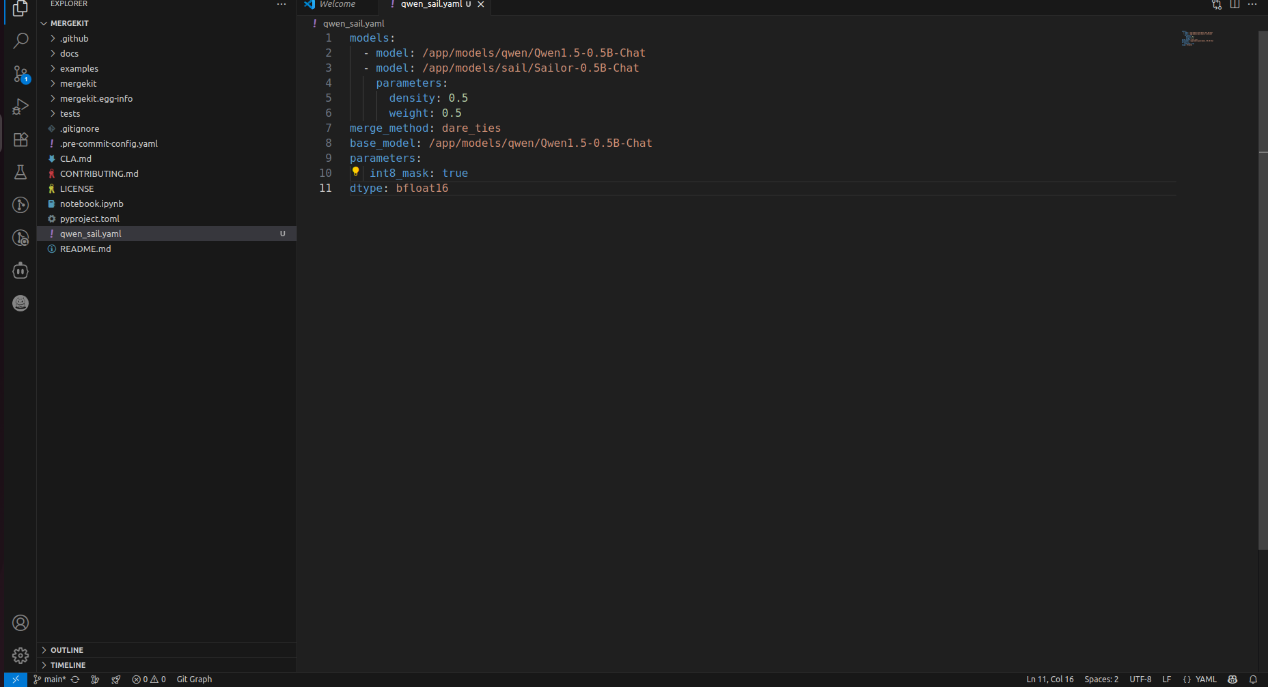
使用Qwe-0.5B與Sailor-0.5B進行合併
調用結合模型 模型輸出結果
►小結
透過以上講解,搭配程式碼進行範例講解,相信各位對於使用Mergekit合併大語言模型能有更深刻的理解,期待下一篇博文吧!
►Q&A
問題一:MergeKit 可以合併不同架構的模型嗎?
不行。MergeKit 主要支援 相同架構的模型(例如都是 LLaMA、Mistral、Falcon 系列),因為不同架構的參數設計不同,權重無法直接對齊。
問題二:合併後的模型一定會比原本的好嗎?
不一定。如果模型差異太大,或訓練方向不一致,合併後反而可能性能下降。
問題三:MergeKit 需要 GPU 嗎?
需要但要求不高,合併過程需要載入模型權重,因此 至少需要一張能載入模型大小的 GPU。
問題四:合併 LoRA 時有什麼注意事項?
MergeKit 可以把 LoRA 權重「寫回」到基礎模型,生成一個完整模型,部署更簡單,LoRA rank 不能太大,否則可能造成合併後的模型漂移。
問題五:常見的合併方法怎麼選?
Linear:簡單平均,適合模型很接近的情況。
SLERP:融合更平滑,常用於聊天模型合併。
TIES:避免破壞專業能力,適合知識型模型。
DARE:隨機 dropout,適合需要更強泛化能力的情境。
►參考資料
評論