

一、概述
當今 AI 技術已無所不在,從智慧城市、工業 4.0 到自動駕駛與智慧醫療,人工智慧不再只是理論,而是推動世界進步的核心引擎。然而,AI真正的挑戰在於即時反應與低功耗運算,這也是邊緣運算(Edge Computing)崛起的關鍵原因。雖然雲端AI運算具備強大的運算能力,但面臨數據傳輸延遲與高頻寬需求的瓶頸,導致許多需要毫秒級決策的應用,例如自動駕駛車輛的行車識別、工業機械手臂控制、監控系統即時警報,無法依賴雲端回應。
為了讓 AI 運算更接近資料來源並提升即時性,MemryX提出了專為邊緣運算設計的AI加速解決方案。MemryX MX3 AI加速卡採用BF16浮點計算架構,突破傳統邊緣設備僅支持整數運算(INT8)的限制,在影像識別、語音處理與目標檢測等高精度AI任務上展現卓越性能,提供5 TFLOPS/W的能效比與高達20 TFLOPS的運算能力,實現低延遲、高精度的AI推理。
除此之外,MemryX 也打造完整的開發生態系統,讓開發者能夠無縫整合 AI 模型的設計、編譯、部署與優化包含 Neural Compiler(將 AI 模型轉換為 DFP 格式)、Simulator(預測吞吐量與延遲)、Benchmark(性能基準測試)以及 Viewer(GUI 視覺化工具),讓 AI 應用開發更加直觀高效。透過這些即插即用的開發工具,MemryX 能夠幫助開發者快速部署 AI 模型,靈活適配 TensorFlow、PyTorch、ONNX 等主流框架,無需重新訓練模型即可應用於各類邊緣場景。
隨著 AI 與 IoT 技術的融合加速,MemryX 以強大的計算能力與低功耗設計,驅動 AI 邊緣計算新時代,為智慧城市、工業自動化與 AIoT 設備提供創新解決方案。MemryX 的目標不僅是提升 AI 推理效能,更是讓 AI 計算變得簡單、靈活、高效,成為 AI 開發者手中的關鍵武器,推動邊緣智能技術的快速演進。
二、開發套件
MemryX 提供了一套軟體開發工具包(Software Development Kit)其中包含了編譯工具(Neural Compiler Tool)、晶片模擬工具(Simulator Tool)、加速器應用工具(Accelerator)、視覺化介面(Viewer)。目前此套件僅能應用於 PC 端,並支援 Ubuntu 與 Windows 作業系統,其安裝方式請按照以下步驟操作:
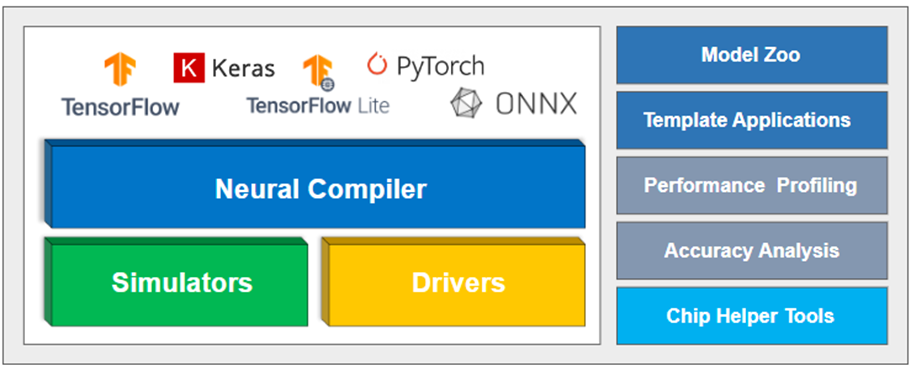
SDK 軟體開發套件示意圖 – 資料來源官方網站
1. 編譯器(Neural Compiler)
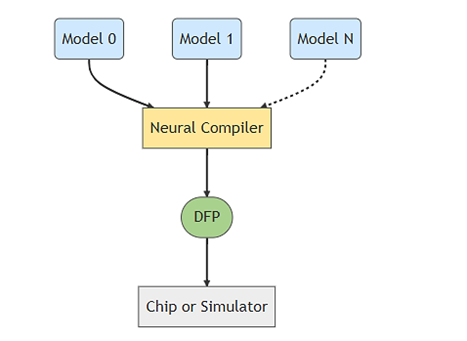
神經編譯器(Neural Compiler)為 MemryX 制式化的編譯工具(建議在 PC 電腦上使用)能夠將各種模組格式轉換編譯成DFP格式(Dataflow Program),透過此格式能夠告訴MX3晶片如何配置核心以及如何處理傳入的模組架構與參數資訊。同時支援多種機器學習框架,如TensorFlow、Keras、ONNX、Pytorch等。
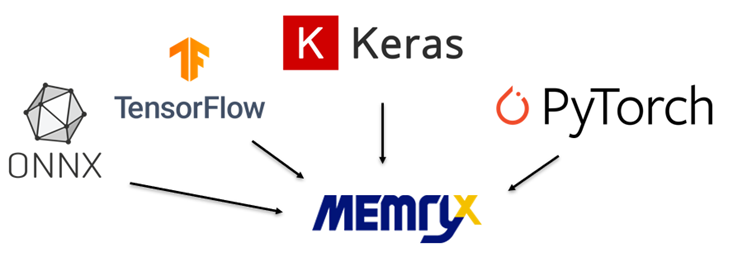
各模組格式轉換為 MemryX DFP 格式示意圖
編譯器細節可以分為四層,如下圖所示,依序為
(1)框架介面:將模組形式轉換為內部圖(internal graph)的形式。
(2)圖處理:透過重新拆解並優化內部圖。
(3)Mapper:將內部圖映射至最佳可配置的 MX3 硬體資源,以最大吞吐量(FPS)為目標。
(4)組譯器:生成 DFP 檔案。

DFP文件生成示意圖
單一模型應用(Single-Model)
使用方式:
句子: $ mx_nc -v -m<模型>
-m, --model:設定實際的模組路徑,支援 .h5 / .pb / .py / .onnx / .tflite 格式
-g, --chip_gen:設定晶片的世代(預設值:mx3)
-c, --num_chips:設定晶片的數量(預設值:1)
-v:查看編譯器程式資訊。
※ 一顆 MX3 晶片約可以處理 10 MB 的資料量。
※ 更多操作,請參考官網軟體開發工具包。
多模型應用(Multi-Model)
在眾多使用 AI 應用場景下,難免會需要將多種模組應用至一個模組的情境例如偵測人臉表情判斷,需要先定位到人臉位置,再透過判斷人臉的喜怒哀樂進行分類。
使用方法:
$mx_nc -v -m<model_1> <model_2> <model_3>
多晶片應用(Multi-Chip)
編譯器會自動將給定模型的工作負載分配到可用的晶片上。
使用方法:
$mx_nc -v-c 2-m<model_1> <model_2>
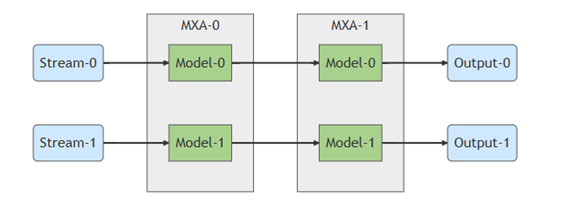
多流(Multiple Input Streams)& 共享輸入流(Shared Input Stream)應用
通常每個模型是獨立使用一個資料流。
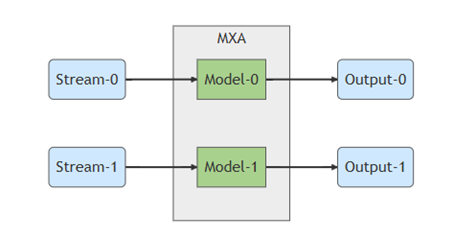
在多個模型且相同輸入流的情況下,編譯器允許共同使用同一個輸入。
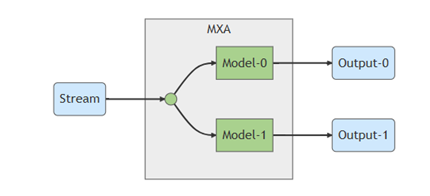
使用方法:
$ mx_nc -v -m<model_1> <model_2> --models_share_ifmap
改變輸入形狀(reshape)
以下範例展示了如何從命令列傳遞到神經編譯器的單輸入模型的典型情況中提供輸入形狀。
使用方式(單一模組):
$ mx_nc -m<模型> -是「300,300,3」
使用方式(多模組):
$ mx_nc -m<model_1> <model_2> 是「224,224,3」「300,300,3」
模組裁剪(Model Cropping)
在使用 AI 晶片時,難免會遇到必須要移除特定的架構層或運算單元(operators)才能更有效地發揮效能。因此,MemryX 也提供了這一功能,可以將模組拆分為影像前處理(Pre-Processing)、神經網路架構處理(Neural Network)、影像後處理(Post-Processing)等架構,能夠將其分工交給影像處理單元 ISP(image signal processor)、圖形處理器 GPU 或中央處理器 CPU,以實現更高效的異構多核心運算。
自動裁剪使用方式:
$ mx_nc -g -m<模型>-v --自動裁剪 -so
-- autocrop:系統自動裁剪前後處理。
手動裁剪使用方式:
$ mx_nc -m<模型>-v --so --outputs<層>-v -so
-is, --input_shapes:設定輸入端大小
--input_format:設定輸入端格式(預設值:BF16)
--inputs:指定預處理裁剪框架的名稱
--outputs:指定後處理裁剪框架的名稱
-so:查看編譯器程式的優化步驟
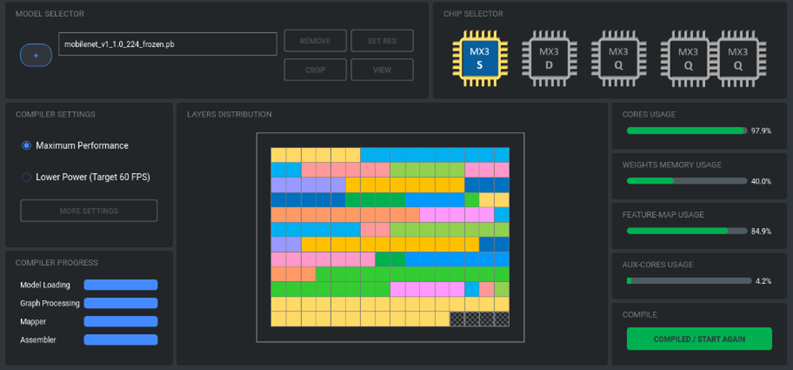
其執行結果如下,從圖片上可以查看計算單元、權重記憶體等的使用量。
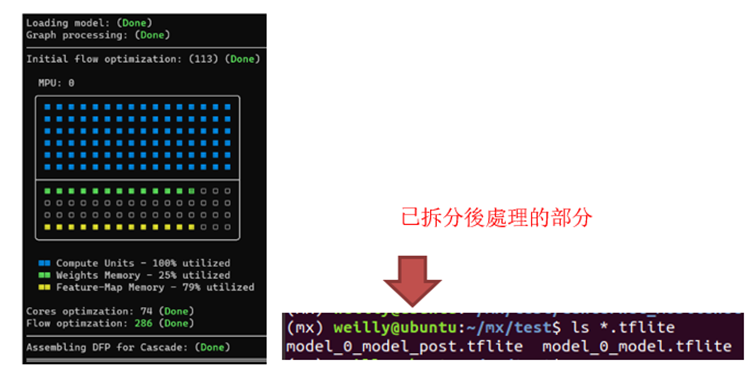
模組裁剪的示意圖
2. 基準測試(Benchmark)
基準測試(Benchmark)是 AI 晶片的標準工具之一,用來測試運行模組的效能。其中,MemryX 設計了用於 C/C++ 和 Python 的基準測試工具,分別是 acclBench 和 mx_bench。可以使用這些工具來測量 FPS 和延遲數據。
下載測試模組SSDlite-MobileNet-v2_300_300_3_tensorflow.zip
$ unzipSSDlite_MobileNet_v2_300_300_3_tensorflow.zip
(2)acclBench(C++)
acclBench [-h] [-v] [-d] [-m] [-n] [-f] [-iw] [-ow] [-device_ids] [-ls]
指令:
$ acclBench -d SSDlite_MobileNet_v2_300_300_3_tensorflow.dfp -f 100
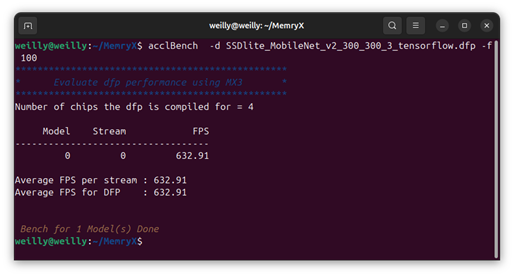
(3) mx_bench (Python)
$mx_bench [-h] [-v] [-d] [-f]
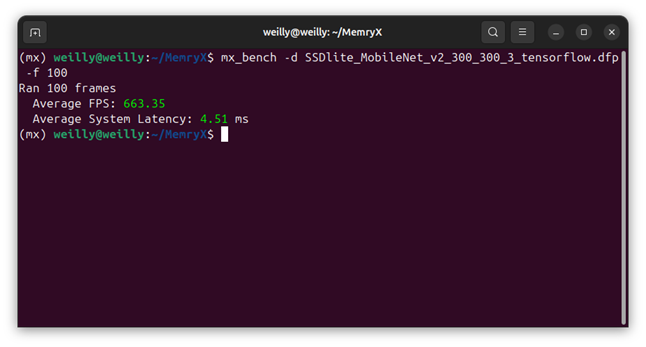
3. 模擬器(Simulator)
模擬器(Simulator)為 MemryX 制式化的工具(用於 PC 電腦使用)提供高精度的模擬性能,能夠準確模擬 MemryX AI 晶片的性能,並展示 FPS(幀數)和 Latency(延遲)的測試數據。
使用方法:
$mx_sim -v -d<dfp>-f 4
-d, --dfp:設定實際的 DFP 檔案路徑
-f, --frames:設定模擬的幀數(隨機數值)
-v:查看編譯器程式資訊。
--no_progress_bar:關閉進度條
--sim_directory:模擬的資料夾路徑(預設值:./simdir)
※ 模擬器無法指定晶片的數量,必須由 dfp 所設定的晶片大小來決定。
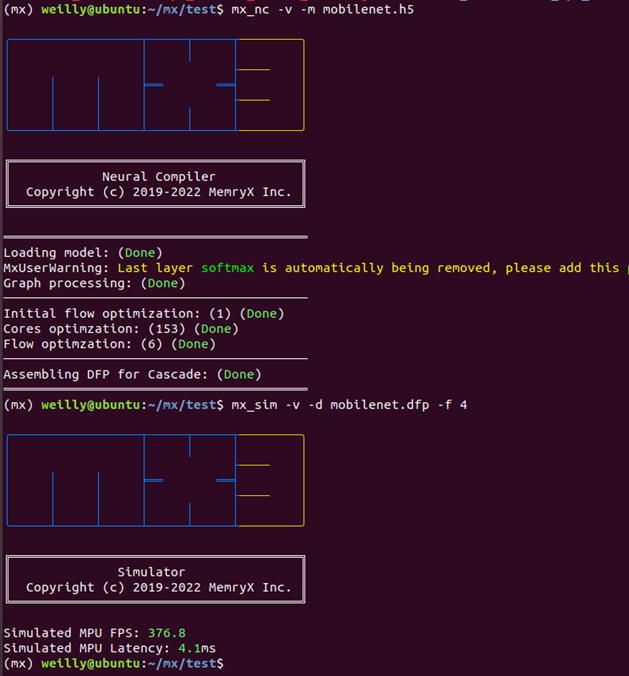
模擬工具的示意圖
來源出處 Memry 文件
4. 視覺化工具(Viewer)
可視化工具(Viewer)是 MemryX 提供的 GUI 介面,包含上述編譯器、模擬器、加速器。
使用方法:
$ mx_viewer
編譯器 :
步驟1:選擇神經網路模型
步驟 2:選擇目標系統

步驟 3:編譯模組
步驟4:執行結果
模擬器
步驟 1:設定張數

步驟 2:執行模擬
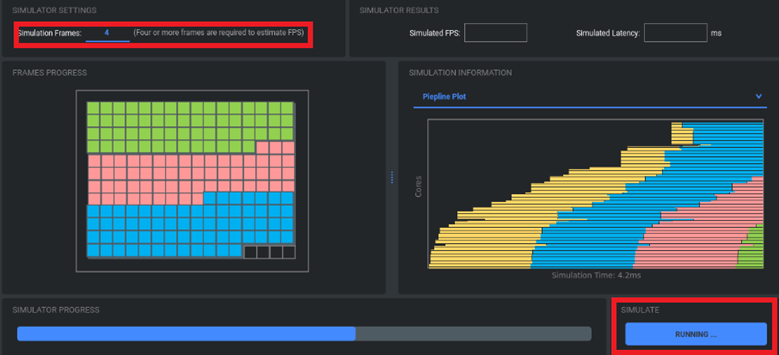
步驟 3:查看結果

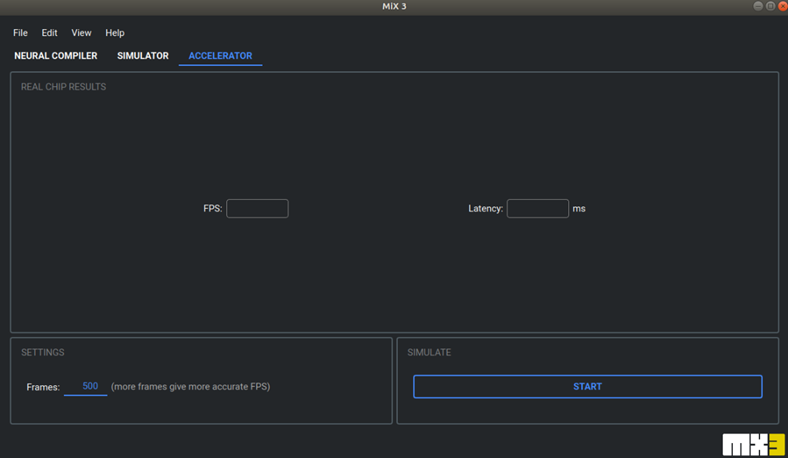
加速器
需要連接上實體的 MX3 EVK,其操作方式與模擬器相似。
5. 檢視器(DFP Inspect)
檢視器(DFP Inspect)為 MemryX 提供的一套檢查 dfp 文件的工具。
使用方法:
句子: $dfp檢查<dfp>
輸出資訊
● DFP
■ 使用的編譯器版本
■ 編譯日期和時間
■ 目標晶片數量
■ 目標架構生成
■ 模擬器配置與 MXA 硬體配置的檔案大小(以 MB 為單位)
● 編譯模型的檔案名稱
● 主動輸入和輸出端口配置
示例:

6. 開源模組資源(Model Zoo)
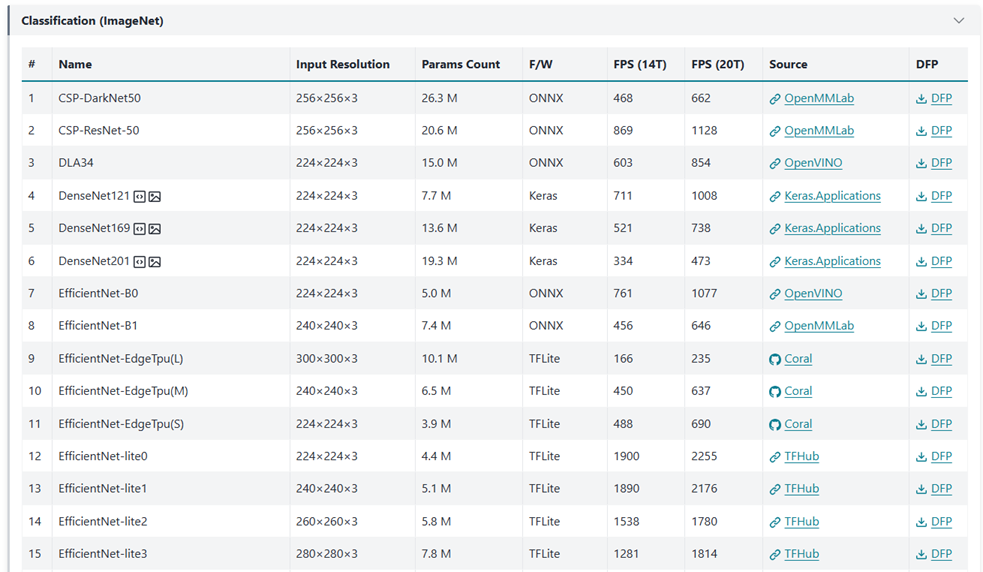
原廠官網也提供豐富的開源模組資源與分析,如下圖所示。
模組分析
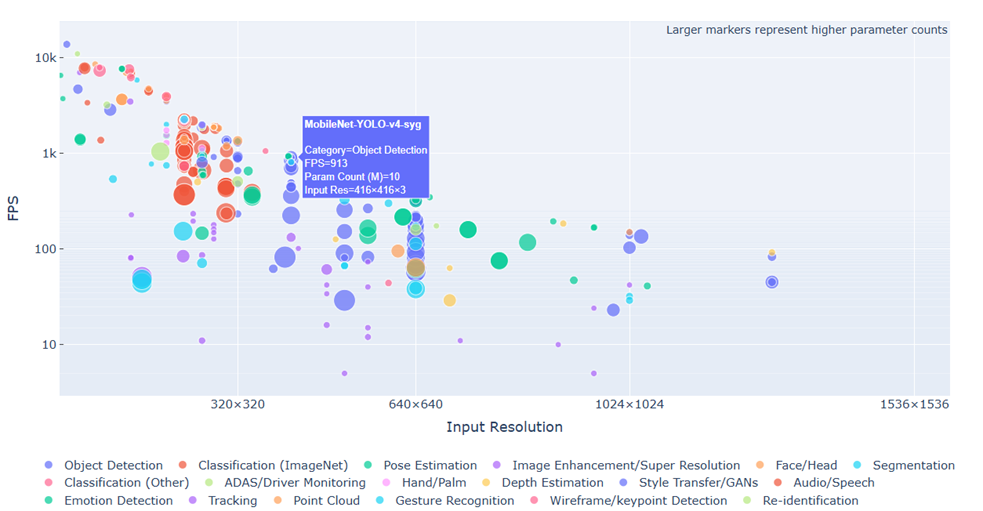
模組資源
三、結語
MemryX MX3+ AI 加速卡以其卓越的計算性能與低功耗特性,為 AI 開發者提供了一個強大且靈活的解決方案。更重要的是,內建完整的軟體開發工具鏈,讓開發者能夠快速部署 AI 模型,同時輕鬆調整前後處理流程實現最佳化的 AI 推理效能。從模型轉換到效能優化,MemryX 提供了一站式的開發支援,讓 AI 開發更加高效且直觀。
為了滿足開發者的需求,MemryX 精心打造了一系列專業工具,包括 Neural Compiler、Simulator、Benchmark 和 Viewer。這些工具不僅功能強大,還以簡單易用為核心設計理念。Neural Compiler 讓模型轉換變得快速且無縫;Simulator 可在部署前模擬運行效能,幫助開發者預測實際應用表現;Benchmark 提供詳細的吞吐量與延遲分析;而 Viewer 則以視覺化介面呈現數據,讓開發過程更加直觀。這些工具的整合,讓開發者能專注於創新,而不必被繁瑣的技術細節所困擾。
在實際測試中,MemryX 晶片展現了其卓越的性能與靈活性。在 C/C++ Python DEMO 測試中,單顆晶片即可同時處理多路攝影機流,並支援多個 AI 模型的並行運行,充分展現其在邊緣運算場景中的優勢。此外,MemryX 的自動化模型裁剪與編譯流程,讓開發者無需修改原始模型即可直接部署,顯著降低了開發門檻,並大幅提升了開發效率。
隨著 AI 技術的快速演進,MemryX 正引領邊緣運算的技術潮流,為各行各業提供高效能、低功耗且靈活的 AI 解決方案。本篇所介紹的工具與應用範例,旨在幫助開發者快速掌握 MemryX MX3+ 的使用方法,讓 AI 技術的應用更加普及化,推動智慧生活的實現。如果您對 MemryX 產品感興趣,或希望獲得更多技術支援與合作機會,請隨時聯繫。聯繫伊布小編!謝謝
四、參考文件
[1]MemryX 官方網站
[2] MemryX開發者中心技術網站
[4] MemryX_範例
[5] 美通社 - MemryX 宣布 MX3 邊緣 AI 加速器正式投產
如有任何相關MemryX技術問題,歡迎在文章底下留言提問!
接下來還會分享更多MemryX技術文章 !!敬請期待【ATU Book-MemryX 系列】 !!

評論