

前言
在現代安防系統中,最常見的應用是各種的影像辨識,例如物體識別、入侵偵測等功能。但除了影像外,聲音也能提供重要的資訊,可以與影像搭配使用,進一步提升監控設備的安全性和功能性。
本文將介紹如何將聲音辨識模型實做在安防攝影機上,以進一步提升其識別和監控能力。
數據集
首先,聲音辨識模型的實現需要一個良好的數據集作為基礎。這些數據應該包括各種可能出現在監控場景中的聲音,例如語音指令、警報聲或突發事件的聲音特徵。
本文使用的資料集是 UrbanSound8K,這個資料集包含了以下十種城市中常出現的聲音類別:
| 編號 | 類別 |
|---|---|
| 0 | 空調聲 (air_conditioner) |
| 1 | 喇叭聲 (car_horn) |
| 2 | 小孩玩鬧聲 (children_playing) |
| 3 | 狗吠聲 (dog_bark) |
| 4 | 電鑽聲 (drilling) |
| 5 | 引擎聲 (enginge_idling) |
| 6 | 槍聲 (gun_shot) |
| 7 | 手提鑽聲 (jackhammer) |
| 8 | 警報聲 (siren) |
| 9 | 街道音樂聲 (street_music) |
資料處理
獲得資料集後,需要對聲音資料進行前處理和特徵擷取,才能用來訓練模型。
本文資料處理方式參考以下網站:
1. https://github.com/yeyupiaoling/AudioClassification-Pytorch
2. https://murphypei.github.io/blog/2021/10/asr-fbank-mfcc。
前處理
- 以下以一個狗叫聲的 wav 檔作為範例,進行前處理的步驟。 下圖是原本音訊的時域和頻域圖:
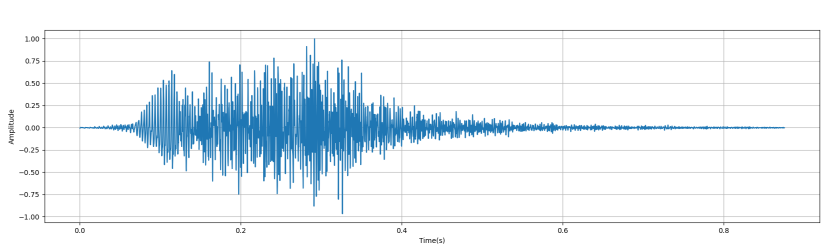
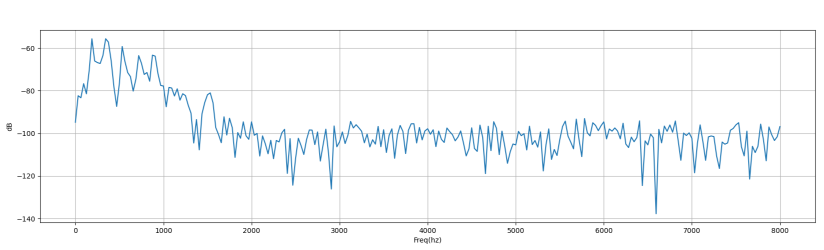
-
前處理步驟:
- 重採樣: 將音檔 resample 成 sample rate = 16000。
- 音量平衡: 針對音量做 normalization。
下圖是經過前處理後的音訊的時域和頻域圖:
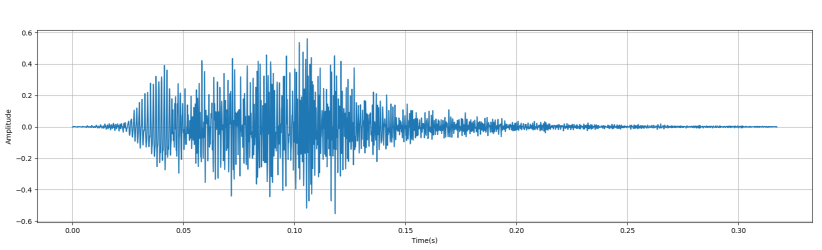
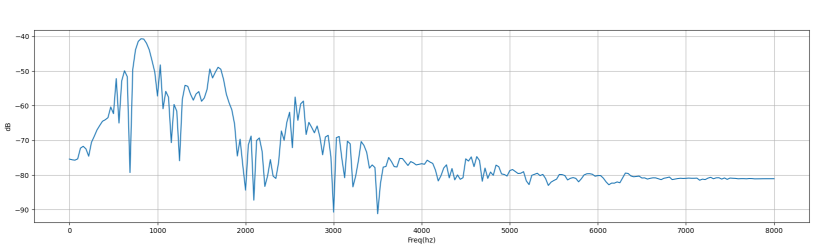
特徵提取
再來是將前面做完前處理的資料,用 Fbank 做特徵提取。
本文 Fbank 的 Mel 濾波器設定為80個,所以最後獲得的特徵是 (80, 30)。
下圖是將提取出的特徵可視化:
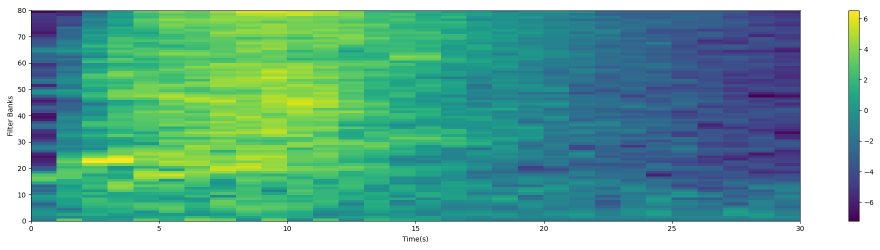
模型
其次,選擇合適的模型架構是實現成功的關鍵。常見的方法包括使用深度學習技術,如卷積神經網絡(CNN)或長短期記憶網絡(LSTM),來處理聲音數據並進行識別。這些模型能夠有效地捕捉聲音特徵並進行準確的分類,從而提升監控系統的智能化水平。
本文是使用 res2net 做為分類模型,以 Urbansound 8k 資料集訓練,準確率達到 93.8%。模型訓練參考此網站: https://github.com/yeyupiaoling/AudioClassification-Pytorch
前述的資料處理是在電腦端先行處理,再將取得的特徵放置到晶片上輸入至模型,得到預測的聲音類別。
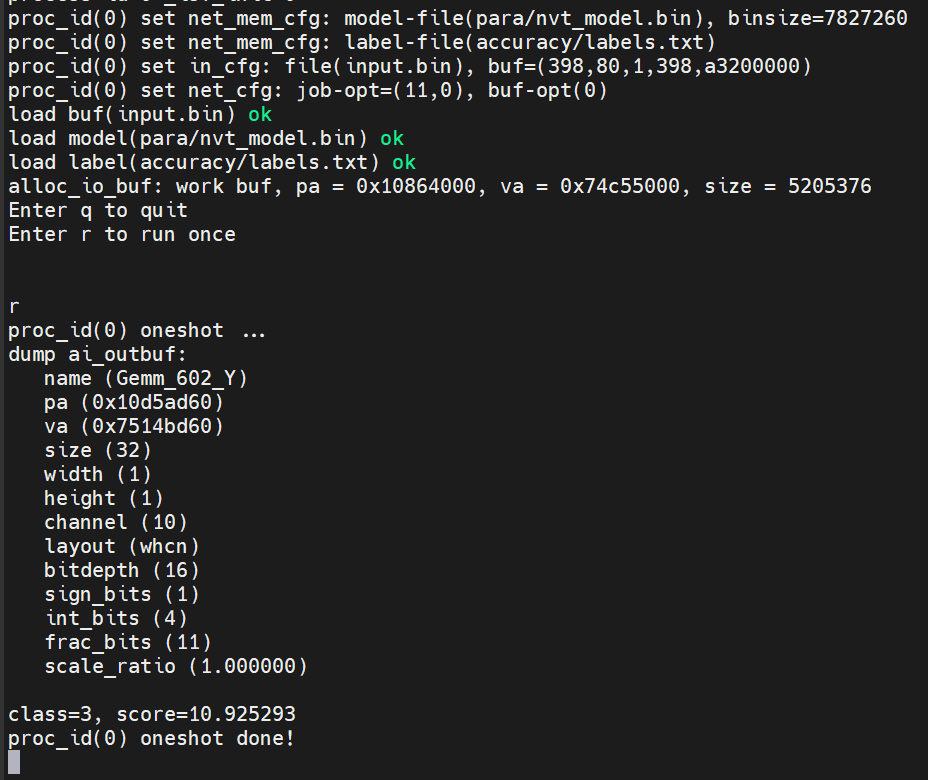
預測出的類別 ID 會是 3,也就是 UrbanSound 8k 類別中狗叫聲的ID。
結語
總結來說,聲音辨識模型在安防攝影機上的應用不僅可以提升監控系統的智能化水平,還能夠在實時監控和事件檢測中發揮關鍵作用。
通過適當的數據準備、模型選擇和系統集成,可以有效實現這一技術,為安全監控帶來全新的可能性和應用前景。
問與答
1.問: 聲音辨識有甚麼應用場景?
答: 城市噪音監測、入侵檢測、智能家居等等。
2.問: 針對音訊資料,在前處理和特徵提取過程中,是否有其他替代方法或技術可以提升辨識精度?
答: 可以調整特徵提取方式,例如從 Fbank 調整成 MelSpectrogram、Spectrogram、MFCC。
3.問: 除了 Res2Net,是否有其他模型架構適合聲音辨識,並且在嵌入式系統上表現優異?
答: ResNetSE、CAMPPlus、ERes2Net、ERes2NetV2、PANNS、TDNN。
4.問: Float32 資料可以直接輸入到板端的模型嗎?
答: 不行。因為模型是 fixed point,輸入也需要轉成 fixed point 才能和模型進行運算。
5.問: 為何本文使用 CNN 而非 LSTM 進行聲音辨識?
答: 因為本文提取出的特徵是二維資料,適合用 CNN 進行訓練和預測。
評論