

在過去的三十年裡,GPU 徹底改變了從智慧型手機到整個運算生態系統和個人電腦到資料中心。 當今一些最令人興奮的應用程序,透過機器學習實現,如果沒有 GPU 加速,這是不可能的。
這段時間,不起眼的顯示卡已從普通的顯示卡轉變為固定功能卸載引擎到通用處理器,可加速程式語言,例如就像 Python、C++ 和 Fortran 一樣 - 而它的發展還在繼續。AMD 在過去十年中引領了系統架構的發展,統一了 CPU 和 GPU 運算規模空前。
AMD Instinct MI250X 是第一個 Exascale 系統的核心,由AMD CDNA™ 2 架構和先進封裝,以及 AMD Infinity Fabric™,連接Instinct GPU 和AMD EPYC 7453s CPU 具有快取一致性。
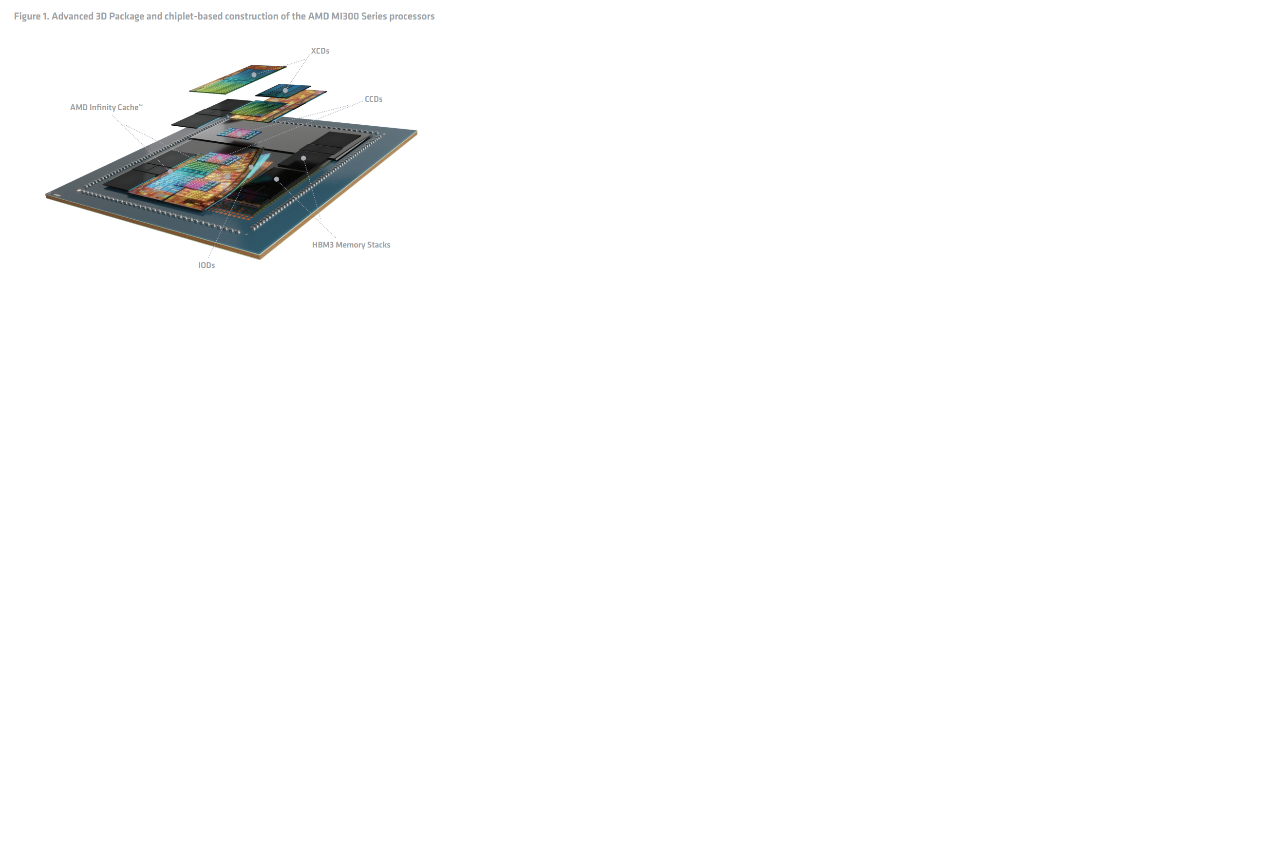
AMD Instinct™ MI200 加速器系列為先進封裝邁出了第一步,具有兩個相同的每個模具都包含計算、記憶體和通訊三個基本要素。 AMD CDNA™ 2 進行了全面改進,特別著重於改善通信接口可擴展到最大的系統。
隨著 AMD 加速運算策略,AMD CDNA™ 3 架構持續引領這一演變採用先進的封裝以實現異質整合。 該戰略提供了出色的性能,透過緊密耦合的連貫編程模型改變計算範式CPU 和 GPU 共同解決當今時代最棘手的問題。 AMD CDNA™ 3 架構提供了顯著的進步,並提供最高的性能、效率和可編程性在最新 AMD Instinct™ MI300 系列中。
這段時間,不起眼的顯示卡已從普通的顯示卡轉變為固定功能卸載引擎到通用處理器,可加速程式語言,例如就像 Python、C++ 和 Fortran 一樣 - 而它的發展還在繼續。AMD 在過去十年中引領了系統架構的發展,統一了 CPU 和 GPU 運算規模空前。
AMD Instinct MI250X 是第一個 Exascale 系統的核心,由AMD CDNA™ 2 架構和先進封裝,以及 AMD Infinity Fabric™,連接Instinct GPU 和AMD EPYC 7453s CPU 具有快取一致性。
AMD Instinct™ MI200 加速器系列為先進封裝邁出了第一步,具有兩個相同的每個模具都包含計算、記憶體和通訊三個基本要素。 AMD CDNA™ 2 進行了全面改進,特別著重於改善通信接口可擴展到最大的系統。
隨著 AMD 加速運算策略,AMD CDNA™ 3 架構持續引領這一演變採用先進的封裝以實現異質整合。 該戰略提供了出色的性能,透過緊密耦合的連貫編程模型改變計算範式CPU 和 GPU 共同解決當今時代最棘手的問題。 AMD CDNA™ 3 架構提供了顯著的進步,並提供最高的性能、效率和可編程性在最新 AMD Instinct™ MI300 系列中。
此設計提供了建造 AMD CDNA™ 3 變體的多功能性,例如 MI300X 獨立 GPU 或MI300A APU,如下圖 2 所示。
MI300X 獨立 GPU 主要專注於加速器運算,並內含 8 個加速器複合模具 (XCD)。 對於機器學習中常見的精度降低的數據,MI300X 獨立 GPU 顯著提升效能,峰值吞吐量提高 3.4-6.8 倍。
FP8 理論 峰值效能為 2.6 PFLOP/s。MI300-11 適用於使用單通道和單通道的經典 HPC 工作負載雙精度,計算吞吐量提高了 1.7-3.4 倍,提供 163.4 TFLOP/SFP64 矩陣單處理器。
AMD CDNA 3 包含矩陣核心技術,可透過改善的指令層級平行處理提供增強的運算輸送量,包括支援各種精度(INT8、FP8、BF16、FP16、TF32、FP32 和 FP64),以及稀疏矩陣資料(即稀疏性)。
AMD Instinct MI300 系列加速器提供領先業界的 HBM3 容量與記憶體頻寬1,2,以及共享記憶體與 AMD Infinity Cache™(共用末級快取記憶體),從而避免資料複製並改善延遲。新一代 AMD Infinity Architecture 搭配 AMD Infinity Fabric™ 技術,可在單一裝置與跨多裝置平台上,為 AMD 顯示卡和處理器小晶片技術實現與堆疊式 HBM3 記憶體一致的一貫高輸送量。它還提供具有 PCIe® 5 相容性的增強型 I/O。
參考來源