

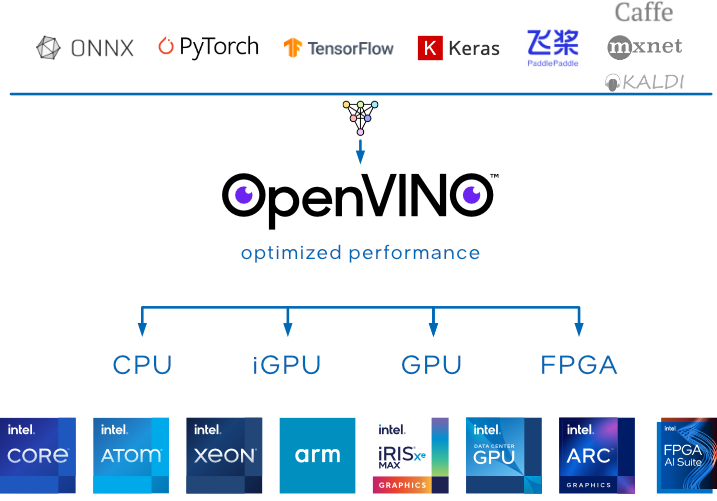
介紹
英特爾® Distribution of OpenVINO™ 工具套件是一款開源解決方案,用於在計算機視覺、自動語音識別、自然語言處理、推薦系統等領域優化和部署人工智能推理。
憑藉其插件架構,OpenVINO 允許開發人員一次編寫並在任何地方部署 (Write once. Deploy anywhere.)。
我們很自豪地宣布發布 OpenVINO 2023.0,做了許多改良,並且引入了一系列新功能,旨在增強開發人員體驗。 這些特色像是:
- 允許直接加載市面上常見的神經網路框架(例如 TensorFlow 和 PyTorch)訓練的模型。
- 通過應用模營再訓練或微調(例如訓練後量化)來優化深度學習模型的推理。
- 支持跨英特爾硬件的異構執行,使用英特爾 CPU、英特爾集成顯卡、英特爾獨立顯卡和其他常用加速器的通用 API
2023版本的新增和更改
主要功能和改進摘要
- 更多集成, 最大限度地減少代碼更改
- 現在,您可以直接在 OpenVINO Runtime 和 OpenVINO Model Server 中加載 TensorFlow 和 TensorFlow Lite 模型,模型會自動轉換! 為了獲得最佳性能,仍然建議在加載模型之前轉換為 OpenVINO 中間表示或 IR 格式。此外,我們還引入了與 PyTorch 模型類似的功能作為預覽功能,您可以直接轉換 PyTorch 模型,而無需轉換為 ONNX。
- 支持Python 3.11
- 新功能:C++ 開發人員現在可以從 Conda Forge 安裝
- 新功能:CPU 插件現在支持 ARM 處理器,包括動態形狀、完整的處理器性能以及廣泛的示例代碼/筆記本覆蓋範圍。已針對 Raspberry Pi 4 和 Apple® Mac M1/M2 進行正式驗證
- 預覽:引入了新的 Python API,允許開發人員直接從 Python 腳本轉換和優化模型
- 更廣泛的模型支持和優化
-
對生成式 AI 的擴展模型支持:CLIP、BLIP、Stable Diffusion 2.0、文本處理模型、變壓器模型(即 S-BERT、GPT-J 等)以及其他值得注意的模型:Detectron2、Paddle Slim、RNN-T、Segment Anything Model (SAM)、Whisper 和 YOLOv8 等等。
-
初步支持 GPU 上的動態形狀 - 在利用 GPU 時不再需要更改為靜態形狀,這對於 NLP 模型尤其重要。
-
神經網絡壓縮框架(NNCF)是現在主要的量化解決方案。您可以將其用於訓練後優化和量化感知訓練。嘗試一下:pip install nncf
- 便攜性和性能
-
CPU 插件現在在第 12 代英特爾® 酷睿及更高版本上提供線程調度。您可以選擇在 E 核、P 核或兩者上運行推理,具體取決於應用程序的配置。現在可以根據需要優化性能或節能。
-
新功能:默認推理精度 - 無論您使用哪種設備,OpenVINO 都會默認採用可實現最佳性能的格式。例如,用於 GPU 的 FP16 或用於第四代 Intel® Xeon® 的 BF16。您不再需要預先將模型轉換為特定的 IR 精度,並且如果需要,您仍然可以選擇在精度模式下運行。
-
GPU 上的模型緩存現已得到改進,模型加載/編譯更加高效。
支持變更和棄用通知
- 以下 OpenVINO C++/C/Python 1.0 API 已棄用,並將在 2023.1 版本中刪除:
-
傳統 API 的 NV12 和 I420 顏色格式
-
允許創建 nv12 和 i420 blob 的方法和函數
-
InferRequest::SetBatch() 方法
-
InferRequest::SetBlob() 方法,允許為 Infer 請求中的特定張量設置預處理
- Legacy properties: DYN_MATCH_LIMIT 和 DYN_BATCH_ENABLED
- Python 3.7 支持現已棄用,並將在 2023.2 版本中刪除。
- 從 2024.0 版本開始,CPU 屬性 ov::affinity 將不再可用。線程調度時,CPU 使用的核心類型將由 OpenVINO Runtime 自動識別。 2023.0 版本中提供了新屬性來設置 CPU 線程配置,包括:
-
ov::hint::enable_cpu_pinning 用於線程固定
-
ov::hint::scheduling_core_type 表示您選擇的核心類型(P 核心或 E 核心)
-
ov::hint::enable_hyper_threading 用於超線程控制
- 訓練後優化工具 (POT) 在 2023.0 版本中已被棄用。現在建議使用神經網絡壓縮框架(NNCF)進行訓練後優化和量化感知訓練。
- 從 2024 年開始,使用在 Caffe、Kaldi 或 MXNet 中訓練的模型將需要使用版本 2022.3 或 2023.2 LTS 轉換為 ONNX 或 OpenVINO IR。
- 所有 ONNX 前端舊 API(由 ONNX_IMPORTER_API 修飾)將在 2023.1 版本中棄用。作為 2024.0 版本的一部分,以下符號將不再可用:
-
ngraph::onnx_import::import_onnx_model
-
ngraph::onnx_import::is_operator_supported and ngraph::onnx_import::get_supported_operators
-
ngraph::onnx_import::register_operator and ngraph::onnx_import::unregister_operator
-
ngraph::onnx_import::Node and ngraph::onnx_import::NullNode
-
ngraph::op::is_null
-
ov::onnx_editor::ONNXModelEditor
- OpenVINO 與 TensorFlow 的集成。如果您希望繼續使用本機框架 API,可以考慮使用 Intel Extension for TensorFlow (ITEX)。另一種選擇是利用 OpenVINO 模型優化器,它可以轉換標準 TensorFlow 模型。最後,在 2023.0 中,TensorFlow 模型現在可以在運行時在 OpenVINO 中自動轉換,因此您不再需要離線轉換模型。
- 此版本將不再支持 OpenVINO 與 TorchORT 的集成。如果您希望繼續使用本機框架 API,可以考慮使用 Intel Extension for PyTorch (IPEX)。如果您正在使用 OpenVINO 尋求英特爾硬件的性能提升,請使用我們新的預覽版 PyTorch 自動轉換功能。
- Python 3.7 將在此版本中棄用,並將在 2023.2 中不再受支持
- OpenVINO Python API 一部分的“PerfomanceMode.UNDEFINED”屬性,該屬性將在 2024.0 版本中刪除。
- OpenVINO 運行時不再支持以下設備:
-
英特爾® 神經計算棒 2
-
採用英特爾® Movidius™ 視覺處理單元 (HDDL) 的英特爾® 視覺加速器設計
-
採用 Intel® Movidius™ Myriad™ X C0 VPU、MYDX x 1 的 AI 邊緣計算板
-
注意:OpenVINO 2022.3.1 LTS(即將推出)包括對上面列出的設備的支持。 OpenVINO 2022.3 的長期支持 (LTS) 將於 2024 年 12 月結束。
- 此版本中已刪除編譯工具,我們建議手動將預處理步驟添加到模型中,並建議保存到 IR 文件。請參考 Use Case - Integrate and Save Preprocessing Steps Into IR¶
其他更詳細訊息, 請造訪 Release Notes for Intel® Distribution of OpenVINO™ Toolkit 2023
參考來源