

ChatGPT 著實讓人們眼前一亮,大眾也“親密”體驗了人工智慧(AI)的神奇魔力,窺見了智能未來的璀璨前景之一斑。然而,就在這離生活愈來愈近的 AI 讓人們對未來充滿無限憧憬、滿懷激動的同時,也有冷靜的分析指出,諸如 ChatGPT 等 AI 規模應用也是一個“吞金獸”,其帶來的不僅僅是讓人急呼“AI 算力告急”;更有從雲端、邊緣到終端廣泛 AI 應用場景,使得 IT 運營環境日益複雜和多樣,讓各種 AI 方案在異構平台獲得便捷、易用且有效優化成為急迫的需求。
異構計算:主要指不同類型的指令集和體系架構的計算單元組成的系統的計算方式,在雲數據中心、邊緣計算場景等有著廣泛應用。
異構計算的興起與工作負載密切相關,在能有效發揮異構計算優勢的應用場景中,人工智慧場景可謂是典型的代表場景之一,不管是深度學習訓練,還是深度學習推理,都會進行大量矩陣運算,需要異構計算提供更有力支撐;而隨著 AI 應用快速走向邊緣,由此引致的雲邊端協同,對異構計算提出了更高要求。計算平台在提升自身算力水平的同時,也需要通過提供優化策略,幫助用戶更好地提升 AI 方案的性能,助力 AI 應用降本增效。
英特爾和騰訊雲協作,通過插件的方式將英特爾® Neural Compressor 集成到 TACO Kit,讓 TACO Kit 充分利用英特爾® Neural Compressor 的優勢特性。利用量化壓縮技術來為不同的深度深度框架(如 TensorFlow、PyTorch、ONNXRuntime 等)提供統一的模型優化 API,便捷實現模型推理優化(由 FP32 數據類型量化為 INT8 數據類型)。同時,也可以利用壓縮庫內置的精度調優策略,根據不同的模型內部結構生成精度更佳的量化模型,幫助用戶大幅降低模型量化的技術門檻,並有效提升 AI 模型的推理效率。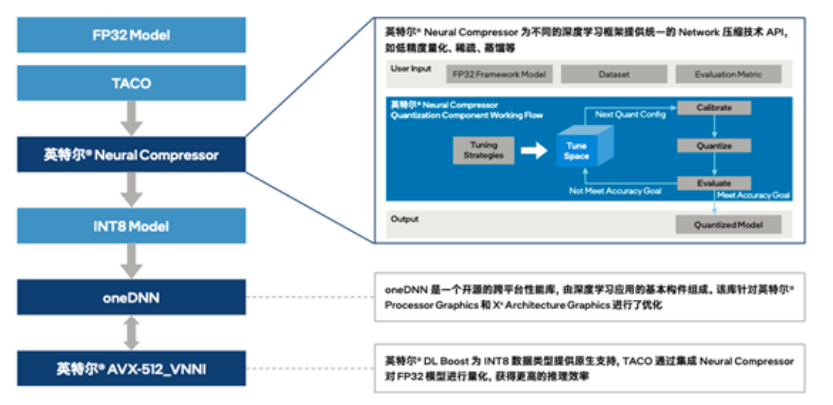
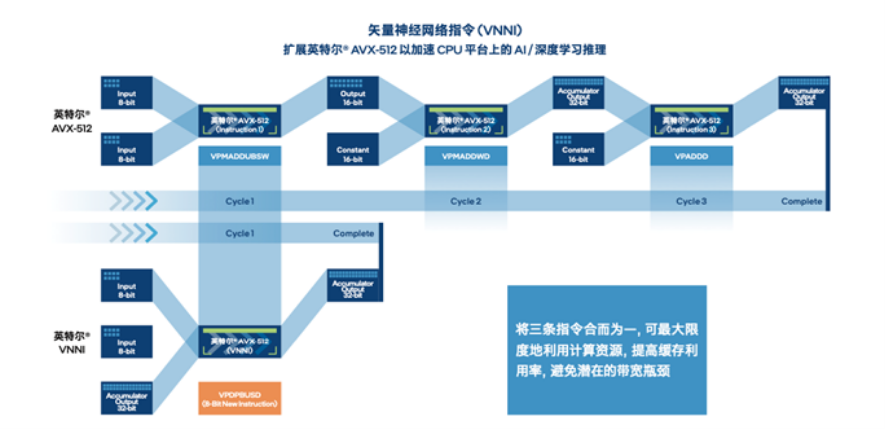
在雲端部署時,量化後的模型可通過英特爾® 至強® 可擴展平台內置的英特爾® DL Boost,來獲得有效的硬體加速和更高的推理效率。以指令集中的 vpdpbusd 指令為例,以往需要 3 條指令(vpmaddubsw、vpmaddwd、vpaddd)完成的 64 次乘加過程,現在僅需 1 條指令(vpdpbusd)即可,並能夠消除運行過程中的處理器飽和問題,再輔之以乘加過程中的中間數值直接從內存播送,可使得處理性能達初始 FP32 模型的 4 倍2。這無疑為 TACO Kit 加速推理,進而幫助用戶在異構環境更高效地構建和部署 AI 提供了關鍵助力。
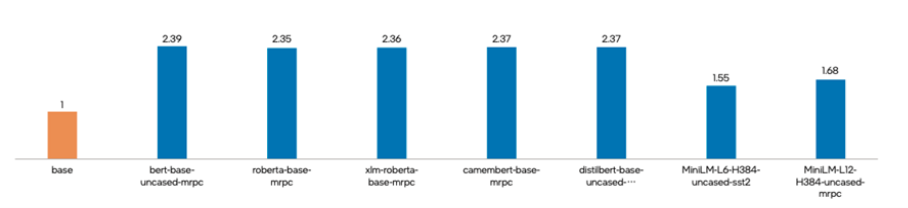
集成英特爾® Neural Compressor 後的 TACO Kit套件打造完成後,英特爾與騰訊雲選取了多種被廣泛應用的自然語言處理深度學習模型,對 TACO Kit 性能加速進行了驗證測試。
測試中,各個深度學習模型在通過 TACO Kit 進行優化後,使用英特爾® Neural Compressor 進行 INT8 量化及性能調優,在保持精度水平基本不變的情況下,各深度學習模型的推理性能均獲得顯著提升,提升幅度從 55% 到 139% 不等,在其中的 bert-base-uncased-mrpc 場景中,推理性能更是達到了基準值的 2.39 倍。
基於這一成果,英特爾和騰訊雲也將面向未來繼續深化合作,通過融合優化算子、自研 AI 編譯技術升級等措施,驅動 TACO Infer 在軟硬體兼容性和性能上不斷疊代優化。同時,雙方還計劃進一步將第四代英特爾® 至強® 可擴展平台及其內置的深度學習加速技術與騰訊計算加速套件 TACO Kit 相融合,藉助新平台更為澎湃的算力輸出與深度學習加速新技術,為用戶提供更加高效可用的異構 AI 加速能力,進而在推動 AI 走向更廣泛應用的同時,助力應對多模態大模型等對算力提出的更嚴峻挑戰。
評論