

Local Voice Commands 與市面上的智慧音箱、你我手機裡頭的語音助理不同,可以不需要透過網路即可執行語音命令,除了在應用上帶來些許便利性,也保障了使用者的隱私安全;與高成本的 MPU 架構不同,只需透過賽微科技 (Cyberon) 提供的 DSpotter 搭配 NXP i.MX RT106S MCU 即可實現 Local Voice Commands。
i.MX RT106S 專案提供 Automatic Speech Recognition (ASR) 及 Audio Front End (AFE) 幫助語音辨識準確率及基礎抗噪能力,將語音資料進行上述處理後,再經由 DSpotter 進行語音辨識。
本文說明語音命令設計提示。
下圖為 DSpotter 軟體架構流程,當 Init 完成後將聲音丟入 Add Sample,當確認聲音符合命令時透過 Get Result 取得結果,如果還有下個命令則透過 Reset 重設 Buffer,如沒有命令要繼續辨識,則透過 Release 釋放相關資源。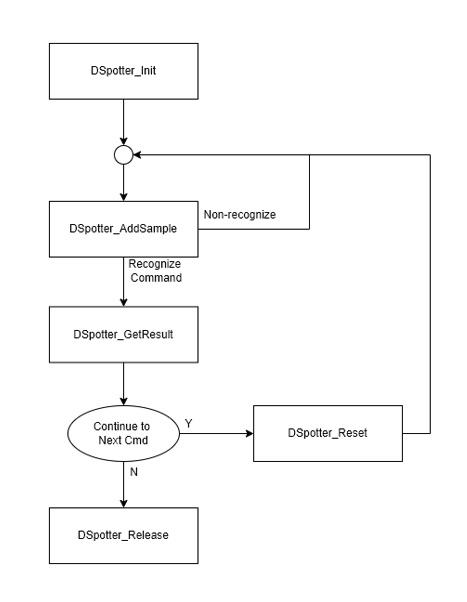
語音辨識流程已包成 lib 檔,上述流程僅供參考。
命令設計建議遵循以下規則,在辨識度上會較佳。
1.命令長度建議 4-6 音節,音節太短的話容易造成誤判,中文字的話一個字為一個音節,英文的話以母音組合為一個音節。
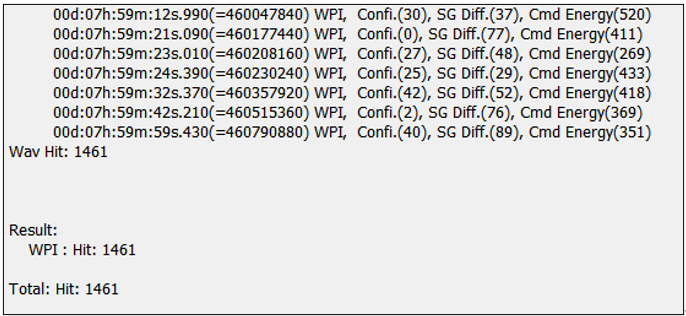
如僅以 WPI 這作為命令僅 3 個音節在 8 HR TV 聲音測試下誤觸發達到 1461
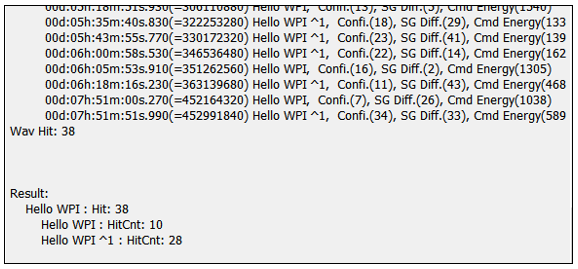
但修改為 Hello WPI 作為命令以同樣條件下測試可降低誤差率到 38 次
2.音節之間的發音盡量與每個命令差異性需足夠,如 Light on /Light off 差異僅在尾音, 在語音模組下不容易辨識。
3.每個音節需子音母音(a,e,i,o,u)組合,盡量避免單一母音字。
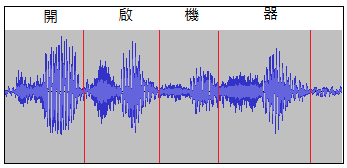
4.避免語音命令摩擦音結合,如開啟機器。
如下圖所示機字與器字在二字結合下振福差異不大,在環境較差的狀況下容易被干擾
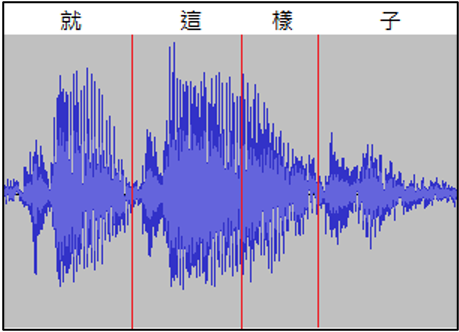
5.抑揚頓挫分開,如中文的「就這樣子」容易變成「就降子」,這的"ㄜ"音跟樣的"ㄧ"音容易結合。
如下圖所示”這樣”的聲紋幾乎沒有振福差異,如果語速快一點可能導致辨識不易
6.指令結尾盡量母音或有聲子音結尾,如英文的 Alexa,Siri,Google
7.盡量避免命令中含有其他命令的部分,如命令為 Search something,Search someone 等相似命令。
8.收集測試資料庫,在調校過程中找尋對應語言的五名男性及五名女性重複 10 次每個命令,透過此資料庫進行調校命令調整 Confidence Score 參數降低 Energy Threshold Level 跑 Offline 模擬測試並看看分數分布,根據結果調整 Global 參數再進行測試
9.增加ㄧ些 Garbage Word,故意配置與目標命令相似詞調整其 Phoneme 刪除某單一音節,將配置的命令其 CmdMapID 配置為 0,並將其藉此濾掉與命令相似的詞彙,如 Hey NXP 音標為:<en-US>hh-ey1.SIL0<en-US>eh1.n-eh-kc1.s-p-iy1 這個命令,會在新增Garbage如 NXP,hi NXP,Hey NX,Hey NP,Ney XP
下圖為經過 8 HR TV Sound 測試 Hey NXP 有三筆誤觸發

下圖增加了 Garbage Word 後 8HR TV Sound 誤觸發率降低至 0

10.失效測試,收集相關語音的 24HR 電視聲音檔案,並將待測物進行 24HR 聲音檔撥放測試,藉此觀察命令配置是否容易誤觸發,觀察命令設計是否合宜。
- AN13212 Speech Model Generation for i.MX RT10xS Local Voice Solution
- Alexa_Manual_Acoustic_Testing_User_Guide_v3_9_7