


OpenVINO自從2018被公布以來,不斷的進步。對於IPC使用者提供了最直接,最容易,也是最高CP值的AI 應用技術。讓開發者不須具備太多的AI相關知識,就能將AI佈建到想要的場地。2022 Q1 Intel再次迎接了三年半以來最大的改版。因此這次要向大家介紹OpenVINO 2022 新版本的功能。
2022.1 版OpenVINO在效能上有很大的進步。OpenVINO的效能不斷優化,在2022.1版本的效能對比2018時的效能在INTEL XEON增加了13倍的效能。
INTEL在Q1 Announce新的OPENVINO AI 開發環境針對建構,優化,和佈署三分面做了一些改良。
首先在建構的部分,OpenVINO 2022.1已經將安裝包拆解為OpenVINO runtime 和 development tool兩個部分。相對於之前的版本,安裝OpenVINO runtime 變得更小更簡潔,只要安裝了OpenVINO runtime便可使用Intel 的硬體來加速執行AI相關的應用。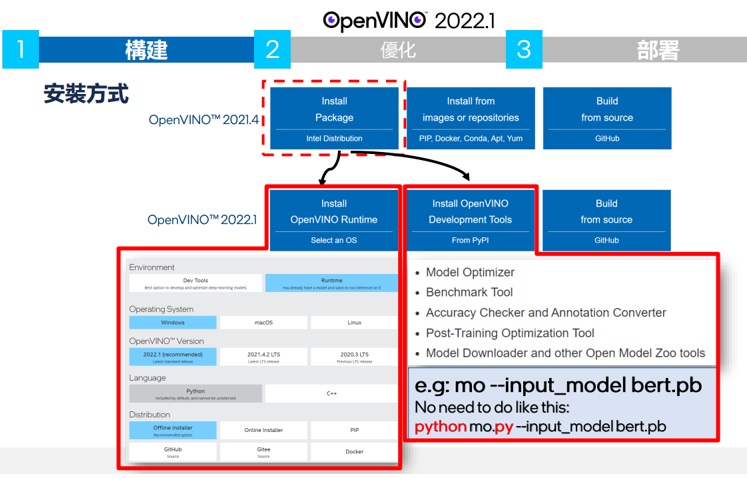
使用最新的OV2022.1的安裝包來安裝OV RUNTIME不同於之前的版本,可以節省下載的時間,安裝的所需的空間。
在Intel的官網上你可以使用圖形介面來選擇你要安裝的方式,在作業系統方面延續之前的版本,一樣是Windows 10,Ubuntu20.04, 以及 Mac OS. 如果您之前已經使用過OpenVINO的使用者你會發現安裝完run time之後,OpenCV,Development Tool, Open Model Zoo的開源碼都不見了。
是的,針對有模型轉換或是需要優化工具需求的在OV RUNTIME安裝完成後,再經由PYTHON工具來安裝開發包。
新版的OpenVINO推論已經不需要使用到OpenCV, 以下整理一張表格讓大家容易了解,新舊版本OpenVINO目錄夾安裝後的比較。
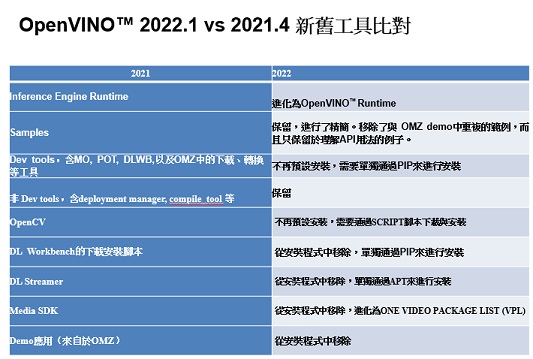
這些被移除掉的東西除了media SDK已經改由 One VPL來加速外其餘您還是可以使用OpenVINO所幫您準備的script或是文檔簡單的步驟安裝回來。以MO, 及Benchmark APP來說您可以使用 python 安裝起來,下面的指令可以讓使用tensorflow或是pytorch, caffe的使用者安裝mo的轉檔工具。
pip install openvino-dev[onnx,tensorflow2,pytorch,caffe]==2022.1.0
另外值得一提的是,不管您是使用mo轉檔或是使用model downloader, model converter下載open model zoo 模型,已經不需要再提供執行檔的絕對路徑,在安裝結束openvino-dev後,系統已經自動加入環境變數,可以在系統任何目錄夾直接使用方便開發,也無須加入副檔名來執行
ex. mo --inputmodel bert.pb...

如上圖,OMZ提供的模型已超過兩百七十個,可以用來測試OPENVINO的在各個領域應用及英特爾平台上的效能測試的項目已經超過了視覺的應用包含了聲音及其他大數據資料都可以經由OPENVINO在英特爾平台上得到相當好的效能
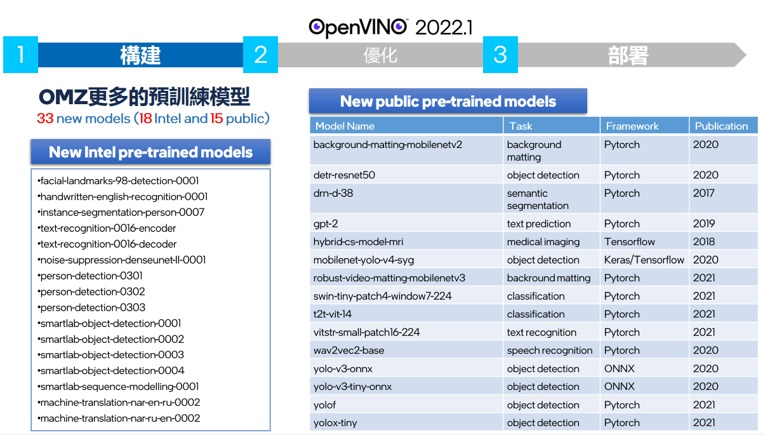
OpenVINo 2022.1新增了33個模型,提供了更多的預先訓練好的模型包含了18個INTEL INTEL PROPRIETARY 模型和15個PUBLIC優化過的模型,讓模型總數超過了三百個以上!!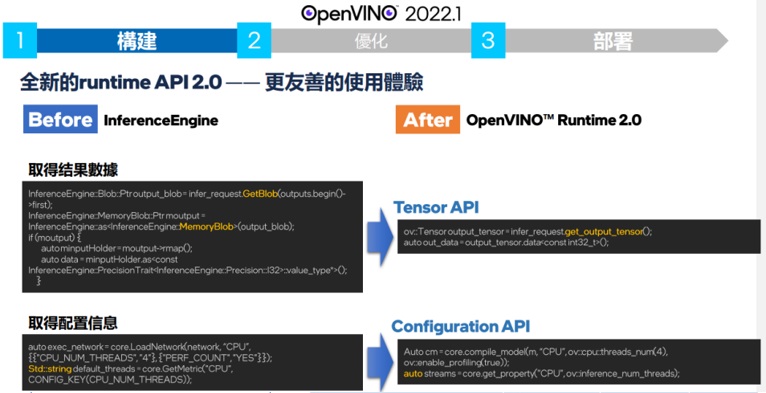
OpenVINO 2022.1最大的修正莫過於對Tensorflow開發者靠攏。Tensorflow每年號稱有6000萬次的下載, 相較於40-50萬次下載量的OpenVINO,Intel從善如流的針對API使用上進行了重大的修改來改善Tensorflow使用者的體驗。並將此新的API稱為runtime API2.0 或是OV 2.0。比如以上圖的的範例來說,推論後回傳的資料原本配置的信息放棄了原先無格式的多維多媒體緩衝空間blob而改採用tensorflow的 get_output_tensor。改用了類似tensorflow tf.Tensor語意的get_output_tensor API 讓tensor flow的使用者更方便的使用
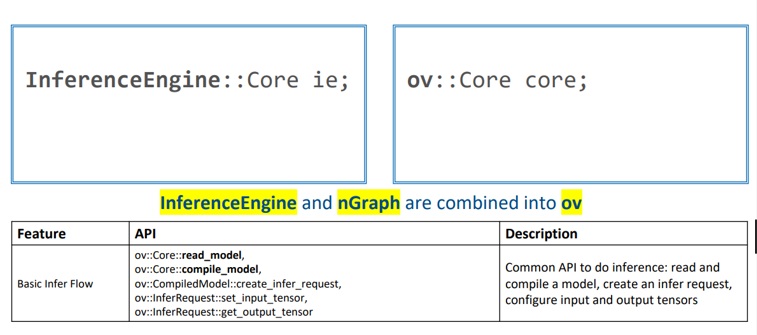
API2.0 包含了原先的inference engine還加入了nGraph API合稱為OV 2.0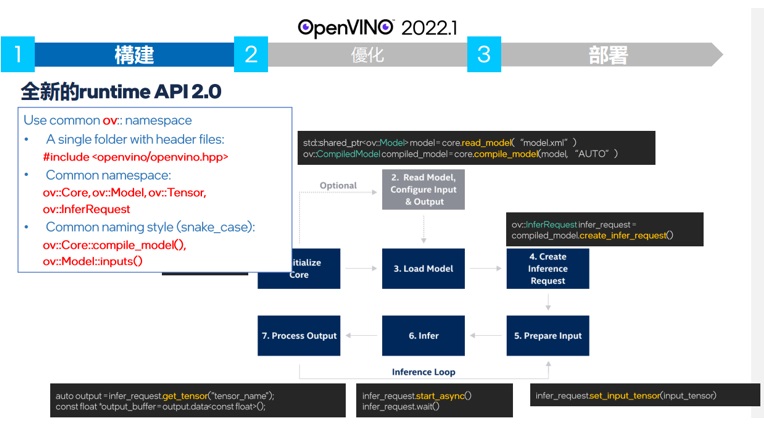
OV 2.0的 API的取名使用了tensorflow的 取名方式,也就是一貫的開頭小寫比用底線來代替空格的方式或稱為snake case
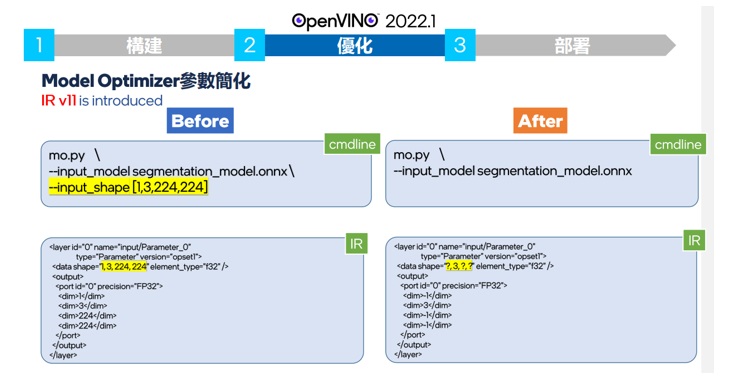
OpenVINO 2022.1 一樣針對tensorflow的相容性方面提供了相當大的優化,強化了使用者的便利性。如上圖所示過去版本的OpenVINO因為在要求static的圖形大小輸入,時常因為無法支援動態的大小變化。但因為很多模型需要在推論過程中需要讓layer可以處裡不同大小圖形,因此過去OpenVINO無法支持該類模型。
新版的OpenVINO2022.1支援了動態圖形尺寸的輸入, 解決了這個問題。並且像是OCR之類的應用,要辨識文字圖形會有不同大小的問題,也一併解決了。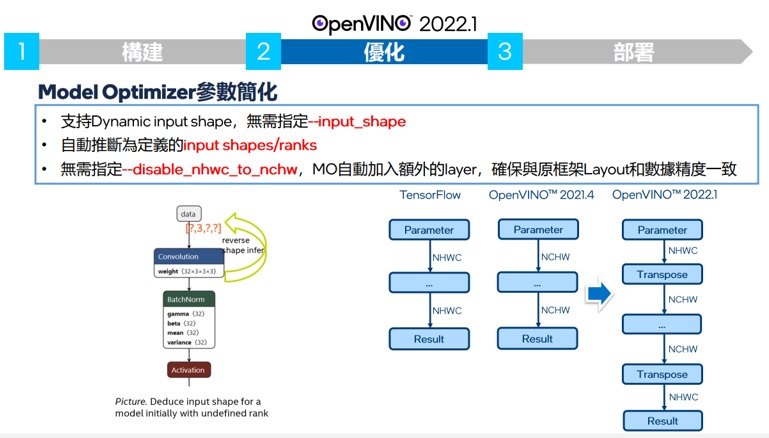
針對了和tensorflow的channel order不同的狀況,OpenVINO 2022.1在轉檔過程中自動插入了轉換成,解決了tensorflow在轉檔過程中需要使用手動指定channel不同,需要預處裡的問題。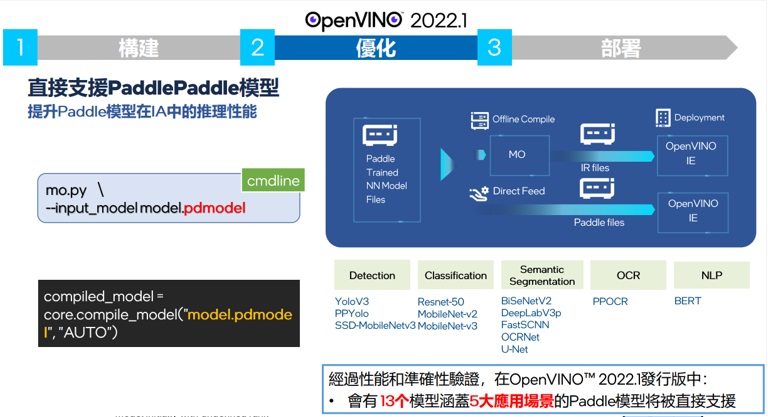
除了ONNX外,OpenVINO 2022.1 新加入了無須轉檔直接支援PADDLE MODEL的13個模型直接推論功能。在效能上的差異上,2022.1在自動優化佈署做了進化,
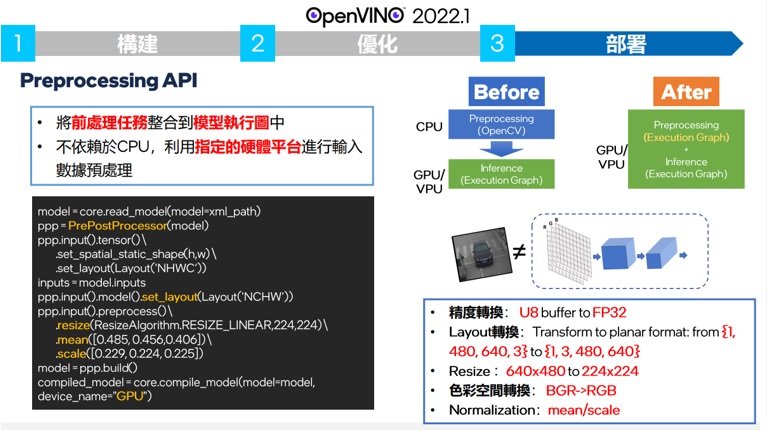
推論用的原本OPENCV做的事情交由GPU/VPU或其他推論影情來做,自動加入到深度學習算法層中的預先處裡和後處理,對於還是有使用OPENCV加速需求的使用者,可以到安裝的目錄夾中找取extra目錄中,使用script選擇性的下載已經加速過的OpenCV版本。
實際使用上,如上圖使用者必須調用API2.0並指定要整合部分的算法到模型之中。
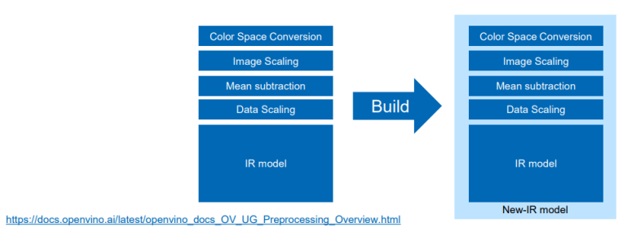
將預處理和後處理的算法加入AI模型中,讓我們可以把LOADING轉換到推論時來處哩,讓CPU的BANDWIDTH來做其他適合CPU做的事情。
另外,針對以往必須要等上近兩分鐘才可以看到第一張推論的GPU/VPU的問題在2022.1也有了解決,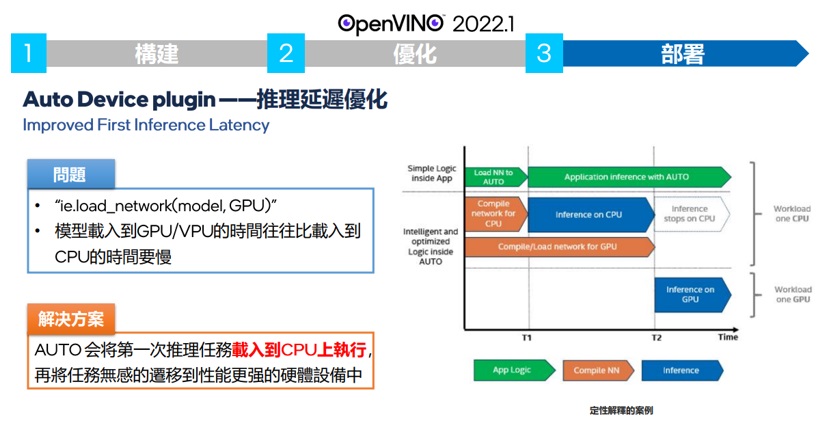
首先OPENVINO會讓第一,或第二張推論使用CPU來做,等到GPU或VPU已經準備好的時候 再切換過去到指定的推論裝置,實測YOLOV4載入時間約九秒左右。而這些都是要拜OPENVINO新的 AUTO DEVICE PLUGIN所賜。如下圖,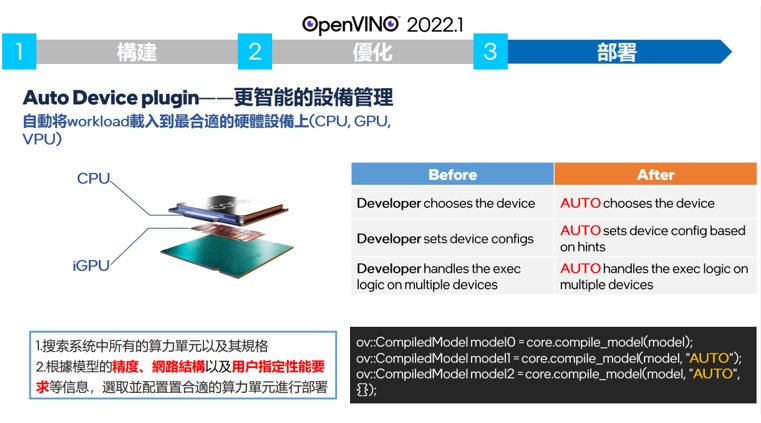
一旦當使用者指定該模型使用AUTO的裝置 OPENVINO會針對搜索系統中的適合模型算力的加速硬體,根據它的單位,規格,並偵測模型精度,網路結構,以及用戶使用的性能的要求,選取適合的算力單位來進行部屬。
最後OpenVINO 2022.1提供了一個很好用的效能自動偵測需求的推論關鍵字,PERFORMANCE HINT。如下圖,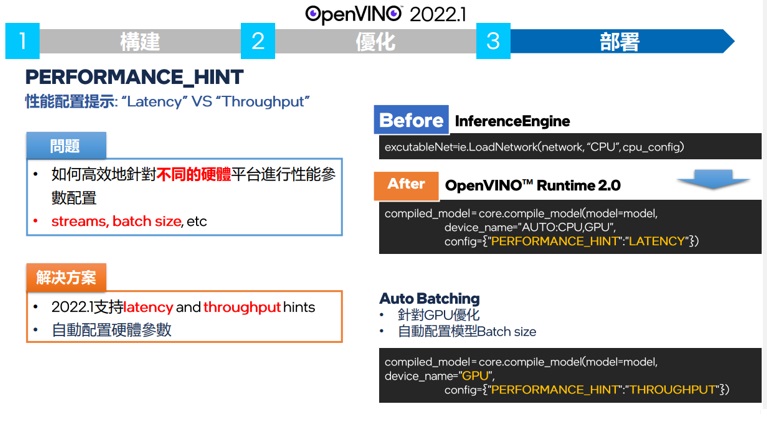
當使用者有指定使用THRU PUT先決還是LATENCY先決的性能要求,可以使用PERFORMANCE HINT來讓OpenVINO 2022.1幫您調整stream 和 batch size的數量來達到您所需要的性能要求。
以上是我針對新版本OpenVINO功能的分享,希望對您有幫助。下次見囉。
評論