

強化學習是一個通過獎懲來學習正確行為的機制. 家族中有很多種不一樣的成員, 有學習獎懲值, 根據自己認為的高價值選行為, 比如Q learning, Deep Q Network, 也有不通過分析獎勵值, 直接輸出行為的方法, 這就是今天要說的Policy Gradients 了. 甚至我們可以為Policy Gradients 加上一個神經網絡來輸出預測的動作. 對比起以值為基礎的方法, Policy Gradients 直接輸出動作的最大好處就是, 它能在一個連續區間內挑選動作, 而基於值的, 比如Q-learning, 它如果在無窮多的動作中計算價值, 從而選擇行為。
什麼是策略網絡Policy Network?就是一個神經網絡,輸入是狀態,輸出直接就是動作(不是Q值)。這裡要提一下機率輸出的問題。對於DQN來說,本質上是一個接近於確定性輸出的算法。但是有很多時候,在某一個特定狀態下,很多動作的選擇可能都是可以的。比如說我有20塊錢去買飯。那麼不管我買的是蛋炒飯還是燒肉飯,結果都是一樣的填飽肚子。因此,採用輸出機率會更通用一些。而DQN並不能輸出動作的概率,所以採用Policy Network是一個更好的辦法。
Policy Gradient不通過誤差反向傳播,它通過觀測信息選出一個行為直接進行反向傳播,當然出人意料的是他並沒有誤差,而是利用reward獎勵直接對選擇行為的可能性進行增強和減弱,好的行為會被增加下一次被選中的機率,不好的行為會被減弱下次被選中的機率。舉例如下圖所示:輸入當前的狀態,輸出action的概率分佈,選擇機率最大的一個action作為要執行的操作。
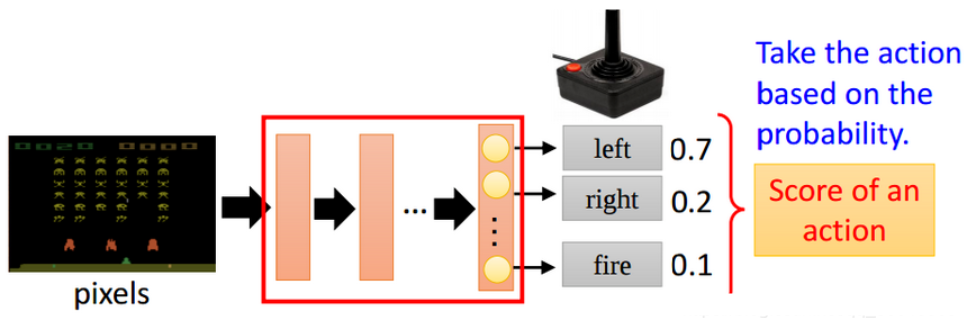
圖1 Policy Gradient
而一個完整的策略τ 代表的是一整個回合中,對於每個狀態下所採取的的動作所構成的序列,而每個回合episode中每個動作的回報和等於一個回合的回報值。
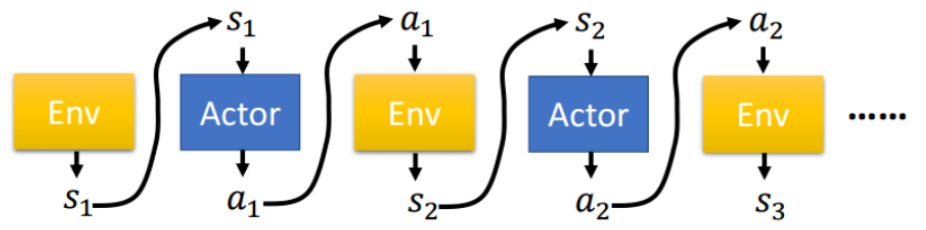
圖2 Policy Gradient策略
在參數為θ情況下時 τ 發生的機率:
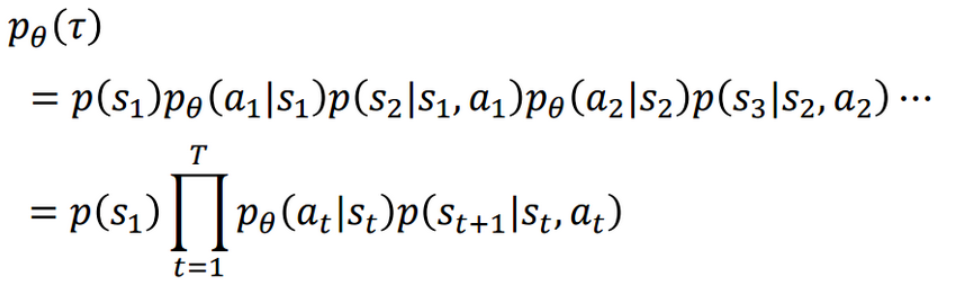
圖3 Policy Gradient 機率演算法
我們就可以根據採樣得到的回報值計算出數學期望,從而得到目標函數,然後用來更新我們的參數 θ。
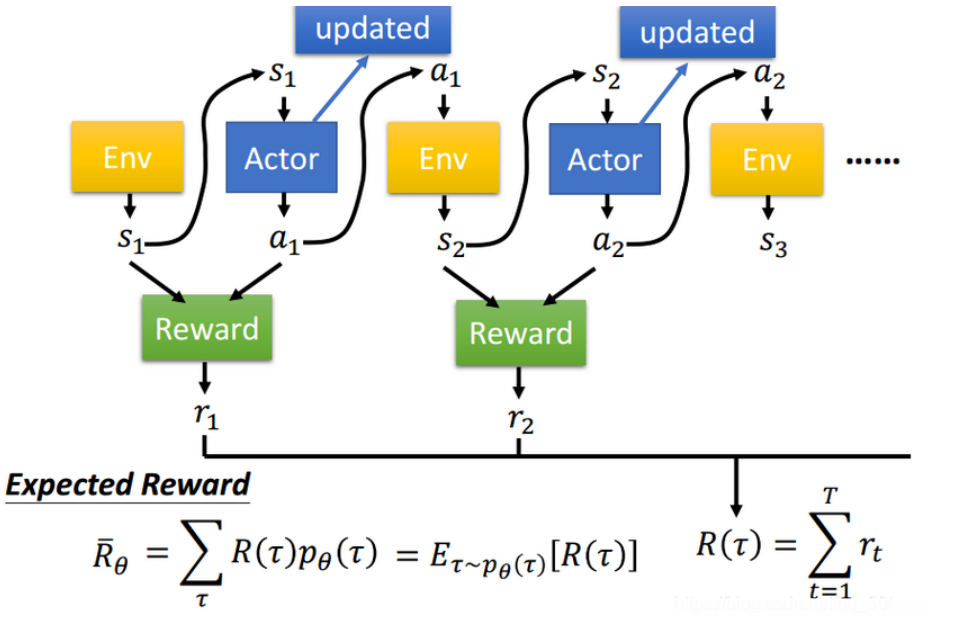
圖4 Policy Gradient 獎勵函數
優點:
- 連續的動作空間(或者高維空間)中更加高效;
- 可以實現隨機化的策略;
- 某種情況下,價值函數可能比較難以計算,而策略函數較容易。
缺點:
- 通常收斂到局部最優而非全局最優
- 評估一個策略通常低效
Policy Gradient提供了和DQN之類的方法不同的想法,之前有提到Value Based強化學習方法,那麼兩者能不能結合起來一起使用呢?答案是可以的,後續會討論到Policy Based+Value Based結合的策略梯度方法Actor-Critic。
評論