

- 回合更新和單步更新兩大類方法:
- On-Policy和Off-Policy的兩大類:
你評估policy或者value-function的時候,需要用到一些樣本,這些樣本也是需要採用某種策略(可能固定、可能完全隨機、也可能隔一段時間調整一次)產生的。那麼,判斷on-policy和off-policy的關鍵在於,你所估計的policy或者value-function 和 你生成樣本時所採用的policy 是不是一樣。如果一樣,那就是on-policy的,否則是off-policy的。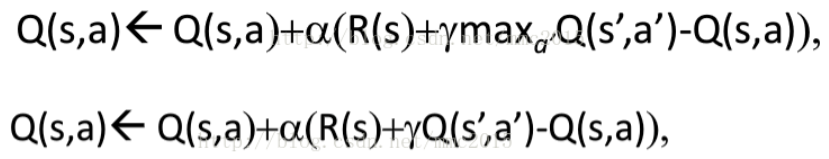
圖1 off-policy的Q-learning、on-policy的sarsa
q-learning每次只需要執行一次動作得到(s,a,r,s')就可以更新一次;因為a'永遠是最優的那個action,因此你估計的策略應該是最優的,即Q_π *(s,a)。而你生成樣本時用的策略則不一定是最優的,因此是off-policy。sarsa必須執行兩次動作得到(s,a,r,s',a')才可以更新一次;而且a'是在特定π的指導下執行的動作,因此估計出來的Q(s,a)是在該π之下的Q-value,即Q_π(s,a)。樣本生成用的π和估計的π是同一個,因此是on-policy。
另一方面,如果sarsa每次的a'都選擇最優的,即特定的π是一個greedy的π,那麼sarsa和q-learning學到的Q-value就是一致的(但是兩者的性質仍然不同)。
所以說,基於experience replay的方法基本上都是off-policy的。
最後強化學習的分類整理如下:
強化學習模型分類
- 通過value選行為:
- Q learning
- Sarsa
- Deep Q Network
- 直接選行為:
- Policy Gradients
- 想像環境並從中學習:
- Model based RL
- 強化學習方法
不理解環境(Model-Free) vs 理解環境(Model-Based)
- 不理解環境
- Q Learning
- Sarsa
- Policy Gradients
基於概率(Policy-Based) vs 基於價值(Value-Based)
- 基於概率
- Policy Gradients
- 基於價值
- Q Learning
- Sarsa
- 兩者結合
- Actor-Critic
- 回合更新
2. 基礎版的 Policy Gradientsl
- 單步更新
2. 升級版的 Policy Gradients
在線學習(On-Policy) vs 離線學習(Off-Policy)
- 在線學習
2. Sarsa lambdal
- 離線學習
2. Deep Q Network
評論