

強化學習分為兩大類,Model-base和Model-free,可以看下圖的分類。

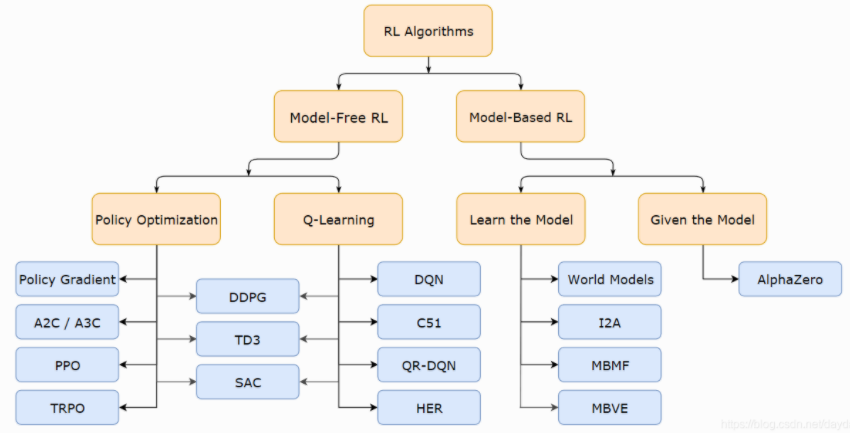
圖1 Model-base和Model-free分類
「Model-Based」既然被翻譯成「基於模型」,那麼關鍵就在於理解什麼是模型。這裡的「模型」,是我們常說的用機器學習的方法訓練出來的模型嗎?不是。這裡的模型是指,在一個環境中各個狀態之間轉換的機率分布描述。還是以天氣為例。我們想要用「模型」的概念描述天氣(或者說建立一個天氣模型),應該怎麼做呢?首先想辦法建立一個表格,如下表。
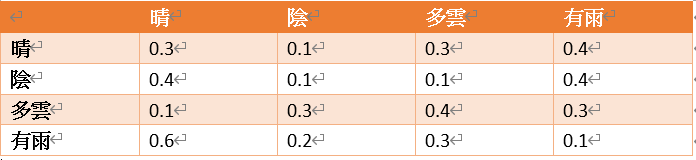
圖2 Model-base 模型
左側的縱坐標表示第一天的天氣狀況,上方的橫坐標表示第二天的天氣狀況。經過長期的統計,得到了這樣一個天氣轉移機率表。其中,第3 行第5 列表示在第一天是陰天的情況下第二天有雨的機率。
這就是一個天氣模型。擁有了這樣的模型(Model),我們能做什麼呢?不管是否滿足馬爾可夫特性,只要有這麼一個模型存在,就必然能夠在初始狀態確定的情況下找出一條滿足特定要求的路徑。只要模型是確定的,轉移機率就是確定的。只要轉移機率是確定的,我們就能知道對應於→ ′ 的轉移機率,以及在狀態 下做什麼樣的動作 會有最高的回報值。這樣,一個狀態的估值,以及一個狀態下的動作估值,就比較容易被準確地估計出來了。
圖1 Model-base和Model-free分類
「Model-Based」既然被翻譯成「基於模型」,那麼關鍵就在於理解什麼是模型。這裡的「模型」,是我們常說的用機器學習的方法訓練出來的模型嗎?不是。這裡的模型是指,在一個環境中各個狀態之間轉換的機率分布描述。還是以天氣為例。我們想要用「模型」的概念描述天氣(或者說建立一個天氣模型),應該怎麼做呢?首先想辦法建立一個表格,如下表。
圖2 Model-base 模型
左側的縱坐標表示第一天的天氣狀況,上方的橫坐標表示第二天的天氣狀況。經過長期的統計,得到了這樣一個天氣轉移機率表。其中,第3 行第5 列表示在第一天是陰天的情況下第二天有雨的機率。
這就是一個天氣模型。擁有了這樣的模型(Model),我們能做什麼呢?不管是否滿足馬爾可夫特性,只要有這麼一個模型存在,就必然能夠在初始狀態確定的情況下找出一條滿足特定要求的路徑。只要模型是確定的,轉移機率就是確定的。只要轉移機率是確定的,我們就能知道對應於→ ′ 的轉移機率,以及在狀態 下做什麼樣的動作 會有最高的回報值。這樣,一個狀態的估值,以及一個狀態下的動作估值,就比較容易被準確地估計出來了。
Model-free是指對於馬爾科夫決策過程(MDP)中的環境機制一無所知,具體而言是指給定當前狀態,agent採取動作後並不知道下一步狀態在哪,以及不知道獎勵會是多少。在這種情況我們並不能做規劃,因為你不知道下一步會遇到什麼。這時候,我們需要改變策略,採用先做實驗再估計的方法
Model-free就是不去學習和理解環境,環境給出什麼信息就是什麼信息,常見的方法有policy optimization和Q-learning。
Model-Based是去學習和理解環境,學會用一個模型來模擬環境,通過模擬的環境來得到反饋。Model-Based相當於比Model-Free多了模擬環境這個環節,通過模擬環境預判接下來會發生的所有情況,然後選擇最佳的情況。
根據強化學習是以策略為中心還是以值函數為中心分為兩大類Policy-Based和Value-Based如圖3: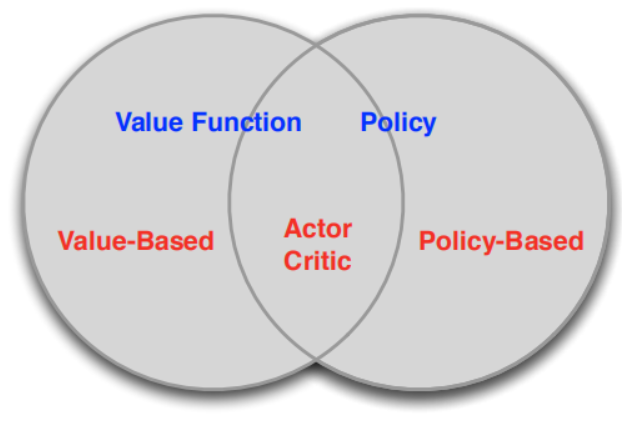
圖3 Policy-base and Value-base分類
Policy-Based的方法直接輸出下一步動作的概率,根據概率來選取動作。但不一定概率最高就會選擇該動作,還是會從整體進行考慮。適用於非連續和連續的動作。常見的方法有policy gradients。 Value-Based的方法輸出的是動作的價值,選擇價值最高的動作。適用於非連續的動作。常見的方法有Q-learning和Sarsa。 更為厲害的方法是二者的結合:Actor-Critic,Actor根據概率做出動作,Critic根據動作給出價值,從而加速學習過程。
評論