

從2020.1版本開始,OpenVINO™工具包提供了後訓練優化工具,該工具旨在通過應用不需要重新訓練的特定方法(例如,後期處理)將深度學習(DL) 模型轉換為更加硬件友好的表示形式,從而加快DL模型的推理速度。
後訓練優化工具包括獨立的命令行工具和Python * API,它們提供以下關鍵功能:
- 兩種支持的訓練後量化算法:快速DefaultQuantization和精確AccuracyAwareQuantization。以及包括多種尚在實驗中的方法
- 使用樹結構的Parzen Estimator對訓練後量化參數進行全局優化
- 對稱和非對稱量化方案
- 針對不同硬件目標(例如CPU,GPU)的壓縮
- 各個Channel的卷積層和其連接算法層的量化
- 多種領域:包含計算機視覺,及其他支援之系統。
- 能夠通過支持的API執行自定義的優化pipeline。
先決條件
- Python * 3.5或更高版本
- OpenVINO 2020.1或更高
安裝後訓練優化工具包(pot)
該工具包作為OpenVINO發行包的一部分分發,並且可以從Windows安裝後使用/deployment_tools/tools/post_training_optimization_toolkit。建議在安裝OpenVINO組件之前創建一個單獨的Python *環境。要將工具包安裝到您的環境中,請按照以下步驟操作:
0. 打開命令視窗
- 在使用優化工具包之前,請安裝AccuracyChecker組件:
- Browse至/deployment_tools/open_model_zoo/tools/accuracy_checker。
- 運行setup.py腳本:
python3 setup.py安裝
2. 安裝工具箱:
- Browse至/deployment_tools/tools/post_training_optimization_toolkit。
- 運行setup.py腳本:
python3 setup.py安裝
現在,該工具包可以在命令行中通過pot別名使用。
使用後訓練優化命令行工具
該工具包需要與OpenVINO中間表示(IR)格式的預訓練模型一起使用,這意味著您需要在運行優化工具之前使用Model Optimizer轉換模型。此外,強烈建議使用AccuracyChecker工具,以便確保您可以成功推斷出該模型,並獲得與原始框架中的參考模型相似的準確度數值。
運行後訓練優化工具命令及步驟如下:
- 在命令行中運行shell script腳本來激活OpenVINO環境:
source /opt/intel/openvino/bin/setupvars.sh
2. 使用configs文件夾中的示例為該工具準備一個配置文件。為了簡化此步驟,可以使用和引用全精度模型的AccuracyChecker配置文件。
3. 使用並運行以下命令的配置文件啟動命令行工具:
pot -c <配置文件的路徑>
有關所有可用的用法選項,請使用-h,--help參數或參考下面的命令行參數。
- 默認情況下,結果將轉儲到運行工具所在目錄的文件夾中的單獨輸出子文件夾results中。使用 -e選項可直接從工具評估輸出算法準確性。
命令行參數
以下命令行選項可用於運行該工具:
|
論據 |
描述 |
|
-h, --help |
非必要。顯示幫助消息並退出。 |
|
-c CONFIG, --config CONFIG |
具有特定於任務/模型的參數的配置文件的路徑。 |
|
-e, --evaluate |
非必要。優化後,在整個數據集上評估模型。 |
|
--output-dir OUTPUT_DIR |
非必要。保存結果的目錄。默認值:./results。 |
|
-sm, --save-model |
非必要。保存原始(FP32)模型。 |
|
-d, --direct-dump |
非必要。將結果直接保存到輸出目錄,而無需其他子 文件夾。 |
|
--log-level {CRITICAL,ERROR,WARNING,INFO,DEBUG} |
非必要。要打印的日誌級別。INFO是默認設置。 |
量化
該工具箱的主要優化功能是統一量化。通常,此方法支持任意數量的位(> = 2),用於表示權重和激活。在量化過程中,將FakeQuantize根據預定義的硬件目標將所謂的操作自動插入到模型圖中,以生成最友好的硬件優化模型。之後,不同的量化算法可以調整FakeQuantize參數或刪除一些操作,以滿足精度標準。可以在運行時解釋生成的“不足的”模型並將其轉換為真正的低精度模型,從而獲得真正的性能改善。
量化算法
該工具包提供了多種量化和輔助算法,有助於量化權重和激活後,恢復準確性。算法可以形成獨立的優化pipeline,您可以應用這些pipeline來量化模型。但是,INTEL團隊僅對以下兩種用於8位精度的量化算法進行了驗證,並建議使用它們來獲得穩定可靠的DNN模型量化結果:
- DefaultQuantization被用作默認方法,以獲取快速但大多數情況下8位量化的準確結果。
- AccuracyAwareQuantization用於在量化後保持在精度下降的預定範圍內,但會以提高性能為代價。可能需要更多時間進行量化。
TunableQuantization啟用量化超參數的調整。它是MinMaxQuantization的可調變體,它是DefaultQuantization管道的一部分,可與全局優化器一起使用,以基於預定義的精度下降和延遲改進標準來調整可能的量化方案。TunableQuantization通常與輔助算法一起用作管道的一部分。
量化公式
量化通過箝位範圍和量化級別數進行參數化:
input_low和input_high表示量化範圍和表示舍入到最接近的整數。
該工具包支持兩種量化模式:對稱和非對稱。它們之間的主要區別在於,在對稱模式下,浮點零直接映射到整數零。對於非對稱模式,它可以是任何整數,但在任何情況下,浮點零都將直接映射到量子,而不會舍入誤差。
對稱量化
該公式由scale在量化過程中調整的參數參數化:
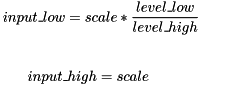
其中level_low和level_high代表離散信號的範圍。
- 對於重量:
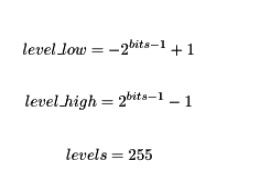
- 對於未簽名的激活:
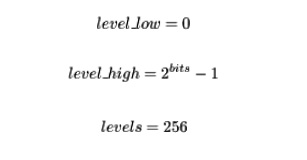
- 對於簽名的激活:
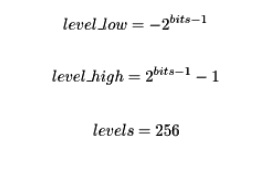
非對稱量化
量化公式由參數化,input_low並且input_range是可調參數:
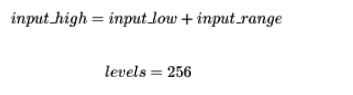
對於權重和激活,將應用以下量化模式:

默認量化算法
總覽
DefaultQuantization算法旨在執行快速但同時準確的NN的8位量化。它包含三種依次應用於模型的算法:
- ActivationChannelAlignment-用作量化之前的初步步驟,並允許您對齊卷積層的輸出激活範圍,以減少量化誤差。
- MinMaxQuantization-這是一種有效的量化方法,可以FakeQuantize根據指定的目標硬件自動將操作插入模型圖中,並使用在校準數據集上收集的統計信息將其初始化。
- FastBiasCorrection-基於該層的量化誤差來調整捲積層和完全連接層的偏差,以使整體誤差保持不變。
該算法使用兩階段統計信息收集程序,因此量化的間隔時間基本上取決於用於它的校準子集的大小。
參量
該算法接受它所依賴的三種算法引入的所有參數。所有這些參數可以大致分為兩組:必选和可選。
- 強制選項包括以下示例中描述的少量參數
- 所有其他選項都可以視為高級模式,並且需要對量化過程有深入的了解。以下是所有可能參數的整體說明:

AccuracyAware精準量化算法
總覽
AccuracyAware算法旨在執行精確的8位量化,並允許模型保持在精度下降的預定義範圍內,例如1%。與DefaultQuantization算法相比,這可能會導致性能下降,因為某些層可以還原為原始精度。通常,該算法包括以下步驟:
- 使用DefaultQuantization算法對模型進行完全量化。
- 在驗證集的子集上比較量化模型和全精度模型,以便找到目標精度度量中的不匹配項。基於不匹配提取排名子集。
- 非必要下,如果使用完全對稱的量化不能滿足精度標準,則將量化模型轉換為混合模式,並重複步驟2。
- 為了獲得每個量化層對精度下降的貢獻,執行了逐層排序。
- 根據排名,最“有問題”的圖層將還原為原始精度。進行此更改之後,將對獲得的模型進行完整驗證集評估,以獲取新的精度下降。
- 如果所有預定義的精度指標均滿足精度標準,則算法結束。否則,它將繼續還原下一個“問題”層。
- 定期恢復可能無法獲得任何準確性的提高,甚至會降低準確性。然後按步驟4中所述觸發重新排名。
參量
由於DefaultQuantization算法用作初始化,因此其所有參數也是有效的並可指定。在這裡,我們僅描述AccuracyAware特定參數:
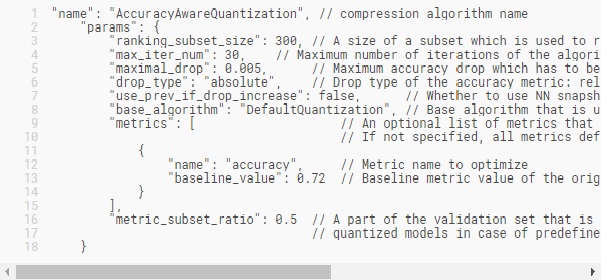
可調量化算法
算法概述
這是MinMaxQuantization的可調變體,通常與輔助算法一起用作管道的一部分。推薦的默認管道包含與** DefaultQuantization **相同的算法,其中MinMaxQuantization被該算法取代。
參量
該算法接受以下參數:
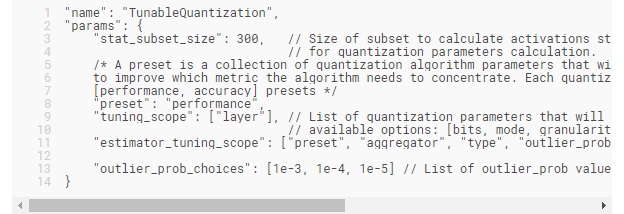
tuning_scope確定哪些量化配置將作為可行選項返回給優化器,並且可以是以下任何值的列表:
- bits,mode,granularity,range_estimator-用於量化配置推導如下所述,
- layer -在可能的量化配置選項中增加了特定層將不被量化的選項。
量化配置推導是通過創建目標硬件支持的所有可用量化配置的列表,然後使用基本配置(從preset最佳結果或先前的最佳結果)進行過濾的tuning_scope。通過從所有可用選項中僅選擇那些與基本配置不同的選項(僅在中指定的變量值)來進行過濾tuning_scope。
選擇是否使用preset或將先前的最佳結果用作基本配置取決於優化器的trials_load_method:
- cold_start- preset確定基本量化配置,
- fine_tune- preset忽略該選項,將用於在先前運行中獲得最佳結果的量化配置用作基本量化配置。
全局優化
全局優化是一項可選功能,讓您可以使用優化器之一來自動找到用於量化的最佳超參數。最優的定義取決於優化器及其配置,並且不一定是最佳解決方案,例如,優化器可能僅使用一種近似算法來搜索最優超參數。
優化器使用量化算法返回的超參數元數據來創建搜索空間,並從中選擇算法的超參數。超參數元數據生成的配置在算法級別完成。有關詳細信息,請參見特定量化算法的說明。
可用的優化器
當前,僅以下優化器可用:
樹型Parzen Estimator估算器(TPE)
基於序列模型的優化方法(SMBO)[1]是貝葉斯優化的形式化。順序指的是一個接一個地運行試驗,每次都通過應用貝葉斯推理並更新替代模型來嘗試更好的超參數。SMBO有五個主要方面:
- 域:超參數或搜索空間的域
- 目標函數:一種目標函數,將超參數作為輸入並輸出需要最小化(或最大化)的分數
- 代理功能:目標函數的代表性代理模型
- 選擇功能:一種選擇標準,用於評估從替代模型中選擇下一個試驗的超參數
- 歷史記錄:由算法用來更新代理模型的(分數,超參數)對組成的歷史記錄
SMBO有多種變體,它們在構建替代物和選擇標準方面有所不同(步驟3-4)。TPE [1]通過應用貝葉斯規則建立了一個替代模型。
注意:TPE需要多次迭代才能收斂到最佳解決方案,建議至少運行200次迭代。由於每次迭代都需要評估生成的模型,這意味著需要對數據集進行精度測量並使用基準測試來進行延遲測量,因此根據模型的不同,此過程可能需要24小時到幾天才能完成。因此,即使TPE支持所有OpenVINO™支持的模型,也僅在部分模型上對其進行持續驗證:
- SSD MobileNet V1可可
- Mobilenet V2 1.0 224
- 更快的R-CNN ResNet 50 COCO
- 更快的R-CNN Inception V2 COCO
- YOLOv3 TF Full COCO
算法概述
TPE算法包含多個(以下)步驟:
- 定義超參數搜索空間的域,
- 創建一個包含超參數的目標函數,並輸出一個我們想要最小化的分數(例如,損失,RMSE,交叉熵),
- 使用隨機選擇的一組超參數獲得幾個觀測值(分數),
- 按分數對收集到的觀察結果進行排序,然後根據一些分位數將它們分為兩組。第一組(x1)包含得分最高的觀察結果,第二組(x2)-所有其他觀察結果,
- 使用Parzen估算器(也稱為內核密度估算器)對兩個密度l(x1)和g(x2)進行建模,這是以現有數據點為中心的內核的簡單平均值,
- 從l(x1)提取樣本超參數,根據l(x1)/ g(x2)對其進行評估,然後返回產生在l(x1)/ g(x1)以下的最小值(對應於最大預期改進)的集合。然後在目標函數上評估這些超參數。
- 在步驟3中更新觀察列表
- 進行固定次數的試驗,重複步驟4-7
參量
TPE接受以下參數:
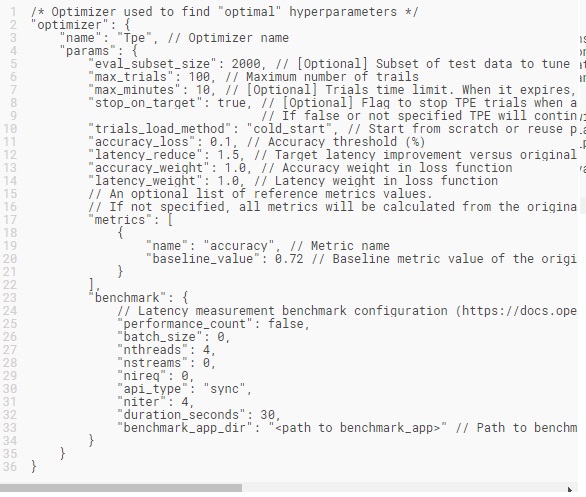
訓練後優化工具包API
總覽
本文檔介紹了訓練後優化工具包(POT)的Python * API,該API允許為單個或級聯/複合DL模型(聯合模型集)實現自定義優化管道。通過優化管道,我們意味著將優化算法連續應用到模型中。優化流水線的輸入是一個全精度模型,結果是一個優化模型。優化流水線配置為按指定的順序順序應用優化算法。應用優化算法的關鍵要求是,用於統計信息收集的校準數據集和用於準確性驗證的驗證數據集的可用性在實踐中可以是相同的。
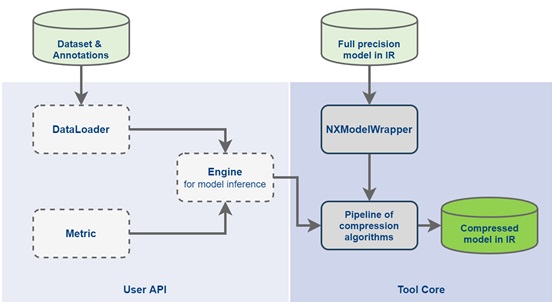
Python * POT API提供了Pipeline用於創建和配置優化管道並將其應用於模型的類。該Pipeline等級取決於它應該根據用戶定制的DL模型來實現以下型號特定接口的實現:
- Engine 負責模型推斷,並提供模型的統計數據和準確性指標。
注意:POT具有類名稱為IEEngine的Engine類的實現。它基於OpenVINO™推理引擎Python * API,可以用作客戶管道中的基準引擎,而不是抽象Engine類。
- DataLoader 負責數據集的加載,包括數據預處理。
- Metric 負責計算模型的準確性指標。
注意:如果要使用精度感知的優化算法(例如AccuracyAwareQuantization和INT4MixedQuantization算法),則需要度量標準。
與實施模式特定管道的接口,如Engine,DataLoader和Metric我們將調用自定義優化管道(見下面的類之間的關係顯示的圖片)。
使用範例
獲得優化模型的主要和最簡單的方法是使用培訓後優化命令行工具,您只需要準備配置文件即可。在深入研究Python * POT API之前,強烈建議您閱讀“ 最佳實踐”文檔,其中描述了使用培訓後優化命令行工具的各種情況。
在以下情況下,可以使用用於模型優化的POT Python * API:
- AccuracyChecker工具不支持模型或數據集。
- POT不支持“ 簡化模式”中的模型,或者生成的精度較低的優化模型。
- 您已經具有使用OpenVINO™推理引擎的Python *腳本來驗證模型的準確性。
API說明
以下是對POT Python * API的詳細說明,為了創建自定義優化管道,應該對其進行實現。
數據加載器
class compression.api.DataLoader(config)
所有DataLoader的基類。
DataLoader 從數據集中加載數據並對其進行預處理,從而可以按索引訪問預處理數據。
所有子類均應覆蓋__len__()函數,函數應返回數據集的大小__getitem__(),而則支持範圍為0到0的整數索引。len(self)
公制
class compression.api.Metric()
代表準確性度量的抽像類。
所有子類都應覆蓋以下屬性:
- value -返回最後一個模型輸出的精度度量值。
- avg_value -返回所有模型輸出的平均準確性度量值。
- attributes -返回度量標準屬性的字典:
{metric_name: {attribute_name: value}}
- 必填屬性:
- direction-(higher-better或higher-worse)一個字符串參數,用於定義在準確性感知算法中是否應增加度量值。
- type-度量標準類型的字符串表示形式。例如,“準確性”或“ mean_iou”。
所有子類都應重寫以下方法:
- update(output, annotation) -使用最後的模型輸出和註釋來計算和更新準確性度量值。
- reset() -重置收集的準確性指標。
Engine
class compression.api.Engine(config, data_loader=None, metric=None)
所有引擎的基類。
該引擎提供模型推斷,用於激活的統計信息收集以及數據集準確性度量的計算。
參量
- config -引擎特定的配置。
- data_loader- DataLoader實例遍歷數據集。
- metric- Metric計算模型準確性指標的實例。
所有子類都應重寫以下方法:
- set_model(model, for_stat_collection=False)-設置/重置模型。
參量 - model- NXModelWrapper推理實例(請參見下面的詳細信息)。
- for_stat_collection-是將模型設置為用於統計信息收集還是用於正常推斷(僅影響級聯模型)。要執行模型,OpenVINO™推理引擎的當前實現需要保存NXModelWrapper到IR,然後將其加載到中IENetwork。因此,應將此標誌傳遞給model.save()函數。
- predict(stats_layout=None, sampler=None, metric_per_sample=False, print_progress=False)-對指定的數據子集執行模型推斷。
參量 - stats_layout-統計收集功能字典。可選參數。
- sampler- Sampler提供迭代數據集的方法的實例。(請參閱下面的詳細信息)。
- metric_per_sample-如果Metric已指定且此參數設置為True,則應為每個數據樣本計算度量值,否則應為整個數據集計算度量值。
- print_progress -打印推斷進度。
返回值
如果metric_per_sample為True ,則每個樣本和整體指標值的字典元組
否則,將使用總體指標字典。
{ 'metric_name': metric_value }
收集的統計字典
Helper和內部模型表示
為了簡化優化管道的實現,我們提供了一組隨時可用的幫助器。在這裡,我們還描述了DL模型的內部表示以及如何使用它。
IE引擎
class compression.engines.IEEngine(config, data_loader=None, metric=None)
IEEngine是一個幫助程序,它基於OpenVINO™推理引擎Python * API實現Engine類。此類支持同步和異步模式下的推理,並且可以在自定義管道中按原樣重用或進行一些修改(例如,在對推理結果進行自定義後處理的情況下)。
可以在子類中覆蓋以下方法:
- postprocess_output(outputs, metadata)-使用在數據加載期間獲得的圖像元數據處理原始模型輸出。
參量 - outputs -模型的原始輸出。
- metadata -有關用於推理的數據的信息。
返回
- 後處理模型輸出
IEEngine支持DataLoader以下格式返回的數據:
(img_id, img_annotation), image)
或是
((img_id,img_annotation),image,image_metadata)
Metric實例返回的指標值應採用以下格式:
- 為value():
{metric_name:[metric_values_per_image]}
- 為avg_value():
{metric_name:metric_value}
為了實現自定義Engine類,您可能需要熟悉以下接口:
NXModelWrapper
Python * POT API提供了將該NXModelWrapper類作為一種接口,用於處理單個和級聯的DL模型。它用於加載,保存和訪問模型,如果是級聯模型,則訪問級聯模型的每個模型。
class compression.graph.nx_wrapper.NXModelWrapper(**kwargs)
NXModelWrapper類提供DL模型的表示。單個模型和級聯模型可以表示為此類的實例。級聯模型存儲為模型列表。
物產
- models -級聯模型的模型列表。
- is_cascade -如果加載的模型是層疊模型,則返回True。
從IR載入模型
Python * POT API提供了實用程序功能來從OpenVINO™中間表示(IR)加載模型:
compression.graph.model_utils.load_model(model_config)
參量
- model_config-描述包含以下屬性的模型的字典:
- model_name - 型號名稱。
- model -網絡拓撲的路徑(.xml)。
- weights -模型權重(.bin)的路徑。
model_config單個模型的示例:
model_config級聯模型的示例:
返回值
- NXModelWrapper 實例
將模型保存到IR
Python * POT API提供了實用程序功能,可以將模型保存在OpenVINO™中間表示(IR)中:
compression.graph.model_utils.save_model(model,save_path,model_name = None,for_stat_collection = False)
參量
- model- NXModelWrapper實例。
- save_path -保存模型的路徑。
- model_name -用來保存模型的名稱。
- for_stat_collection-是否保存模型以用於統計信息收集或用於正常推斷(僅影響級聯模型)。如果設置為False,則從節點名稱中刪除模型前綴。
退貨
- 帶有路徑的詞典列表:
取樣器
class compression.samplers.Sampler(data_loader = None,batch_size = 1,subset_indices = None)
所有採樣器的基類。
採樣器提供了一種遍歷數據集的方法。
所有子類都覆蓋__iter__()方法,提供一種對數據集進行迭代的__len__()方法,以及一種返回返回的迭代器長度的方法。
參量
- data_loader- DataLoader加載數據的類的實例。
- batch_size -批處理項目數,默認為1。
- subset_indices-加載樣本的索引。如果subset_indices設置為“無”,則採樣器將從整個數據集中獲取元素。
批量採樣器
class compression.samplers.batch_sampler.BatchSampler(data_loader,batch_size = 1,subset_indices = None):
如果subset_indices指定了採樣器,則在指定的數據集子集上或在給定的整個數據集上提供迭代器batch_size。返回數據項列表。
管道
class compression.pipline.pipeline.Pipeline(engine)
管道類表示優化管道。
參量
- engine- Engine用於模型推斷的類的實例。
通過調用實例run(model)所在model的方法,可以將管道應用於DL模型NXModelWrapper。
創建管道
POT Python * API提供了實用程序功能來創建和配置管道:
compression.pipline.initializer.create_pipeline(algo_config, engine)
參量
- algo_config-定義優化算法及其優化管道中包含的參數的列表。在優化管道中將它們應用於模型的順序由列表中的順序確定。
管道算法配置示例:
- engine- Engine用於模型推斷的類的實例。
返回值
- Pipeline類的實例。
使用範例
在運行優化工具之前,強烈建議您確保
- 該模型是從使用源框架轉換成OpenVINO™中間表示(IR)ModelOptimization。
- 可以使用OpenVINO™推理引擎以浮點精度成功推斷模型。
- 該模型實現了與原始訓練框架相同的準確性。
如上文所述,DataLoader,Metric並Engine以創建模型中的自定義優化管道接口應實現。在某些情況下,您可能會使用OpenVINO™推理引擎為模型提供Python *驗證腳本,實際上,該腳本包括加載數據集,模型推理和計算準確性指標。所以,你只需要包裝在驗證腳本的現有功能DataLoader,Metric和Engine接口。在另一種情況下,您需要從頭開始實現接口。
為了方便使用Python * POT API,我們實現了IEEngine類,該類提供了Vision域中大多數模型的模型推斷,這些模型可以重用於任意模型。
在實現,接口之後YourDataLoader,可以如下創建自定義優化管道並將其應用於模型:YourMetricYourEngine
有關使用Python * POT API的深入示例,請瀏覽OpenVINO™工具包安裝中包含的樣本,該樣本可在/deployment_tools/tools/post_training_optimization_toolkit/sample目錄中找到。
配置文件說明
在以下說明中,後訓練優化工具目錄/deployment_tools/tools/post_training_optimization_toolkit稱為。是安裝英特爾®OpenVINO™工具包的目錄。
該工具包旨在與配置文件一起使用,其中指定了優化所需的所有參數。這些參數被組織為字典,並存儲在JSON文件中。JSON文件允許使用jstylesonPython *軟件包支持的註釋。邏輯上,所有參數都分為三組:
- 與模型定義相關的模型參數(例如,模型名稱,模型路徑等)
- 引擎參數,用於定義引擎參數,這些參數負責用於優化和評估的模型推斷和數據準備(例如,預處理參數,數據集路徑等)
- 與優化算法相關的壓縮參數(例如算法名稱和特定參數)
型號參數
本節僅包含三個參數:
- "model_name" -定義模型名稱的字符串參數,例如 "MobileNetV2"
- "model" -字符串參數,用於定義輸入模型拓撲(.xml)的路徑
- "weights" -定義輸入模型權重(.bin)路徑的字符串參數
引擎參數
訓練後優化工具中有兩種引擎類型。
- AccuracyChecker引擎。在推論DL模型和使用數據集時,它依賴於深度學習準確性驗證框架(AccuracyChecker)。此模式的好處是可以在有批註的情況下計算準確性。並執行準確性感知算法家族。在該模式下,有兩個選項可以定義引擎參數:
- 對於SE-ResNet-50模型: /configs/examples/quantization/classification/se_resnet50_pytorch_int8.json
- 對於SSD-MobileNet模型: /configs/examples/quantization/object_detection/ssd_mobilenetv1_int8.json
- 請參考由YAML文件表示的現有AccuracyChecker配置文件。它可以是用於精確模型驗證的文件。在這種情況下,您應該僅定義"config"包含AccuracyChecker配置文件路徑的參數。
- 直接在JSON文件中定義所有必需的AccuracyChecker參數。有關更多詳細信息,請參閱該工具隨附的相應AccuracyChecker信息和配置文件示例:
- 簡化了。它不使用AccuracyChecker工具和註釋。要測量準確性,如果AccuracyChecker支持您的模型和數據集,則應實現與樣本類似的自己的管道或從工具文件夾運行評估腳本。如果使用評估腳本,則還應該定義AccuracyChecker配置。
- 要運行簡化模式,請mobilenetV2_tf_int8_simple_mode.json從/configs/examples/quantization/classification/目錄中定義類似於示例文件的引擎部分。
壓縮參數
本節定義優化算法及其參數。有關具體優化算法的參數的更多詳細信息,請參閱相應的文檔。
配置文件示例
為了快速入門,提供了一些流行的DL模型的配置文件示例。配置文件位於/configs/examples文件夾中。有關如何使用示例配置文件運行培訓後優化工具的詳細信息,請參閱說明。
評論