

這裡使用機器學習的分類器作為貫穿特徵選擇的例子,分類器只有你在提供好特徵時,才能發揮出最好效果,這也意味著找到好的特徵,才是機器學習能學好的重要前提。如何區分哪些是好的特徵(good feature)?
我們在用特徵描述一個物體,比如A和B兩種物體中,包括兩個屬性長度和顏色。然後用這些屬性描述類別,好的特徵能夠讓我們更輕鬆的辨別出相應特徵所代表的類別,而不好的特徵會混亂我們的感官,帶來一些沒用的資訊,浪費計算資源。

圖1 特徵類別
比如對比金毛和吉娃娃,它們有很多特徵可以對比,比如眼睛的顏色、毛色、體重、身高等,為了簡化我們的問題,我們主要觀察毛色和身高這兩個特徵,而且我們假設這兩種狗毛色僅為偏黃色或偏白色。接著我們來對比毛色,結果發現金毛和吉娃娃兩種顏色的比例各佔一半。

圖2 身高

圖3 毛色
然後我們將它們用資料形式展現出來,假設只有兩種顏色(偏黃、偏白),用紅色表示金毛,藍色表示吉娃娃,兩種狗所佔比例各為一半。該資料說明:給你一隻毛色偏黃的特徵,你是無法判斷這隻狗是金毛還是吉娃娃的,這就意味著通過毛色判斷兩種狗的品種是不恰當的,這個特徵在區分品種上沒有起到作用,我們要避免這種無意義的特徵資訊。
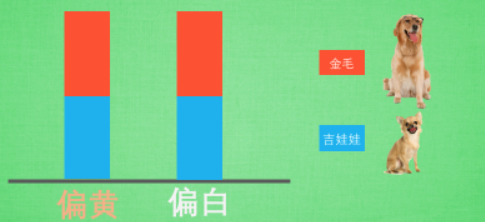
圖4 避免無意義的資訊
接下來我們嘗試用身高來進行分類。

如下圖所示,高度為50的紅色這組資料中,基本上判斷這隻狗就是金毛,同樣高度大於50的也是金毛;而當資料為20時,我們能夠說它很可能就是吉娃娃;而高度為30的範圍,我們很難判斷它是金毛還是吉娃娃,因為兩種狗都存在而且數量差別不大。所以,雖然高度是一個非常有用的特徵,但並不完美,這就需要我們引入更多的特徵來判斷機器學習中的問題。
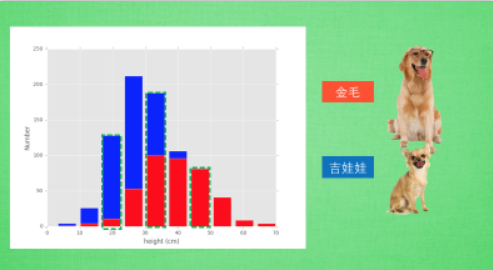
圖5 身高分類
如果要收集更多的資訊,我們就要剔除那些沒有意義或不能區分資訊的特徵,比如毛色,而高度比較有用,保留該特徵;同時需要尋找更多的特徵來彌補高度的不足,比如體重、跑步速度、耳朵形狀等,用這些加起來的資訊我們就能彌補單一特徵所缺失的資訊量。
有時候,我們會有很多特徵資訊資料,而有些特徵雖然名字不同,但描述的意義卻相似,比如描述距離的公里和裡兩種單位,雖然它們在數值上並不重複,但都表示同一個意思。在機器學習中,特徵越多越好,但是把這兩種資訊都放入機器學習中,它並沒有更多的幫助。
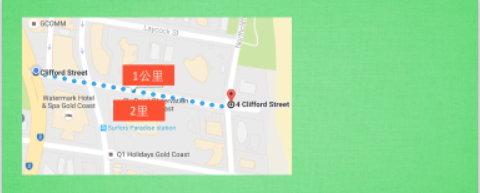
圖6 避免重複資訊
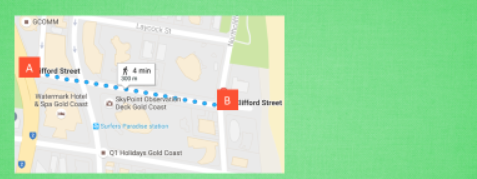
圖7 避免複雜資訊
同樣在這張圖片中,如果從A到B,有兩種方式可供選擇,一種是經緯度,另一種是AB之間的距離。雖然都屬於地理為止資訊,但是處理經緯度會比計算距離麻煩很多,所以我們在挑選特徵時,會增加一條:避免複雜的特徵。因為特徵與結果之間的關係越簡單,機器學習就能夠更快地學習到東西,所以選擇特徵時,需要注意這三點:避免無意義的資訊、避免重複性的資訊、避免複雜的資訊。
評論