

在神經網絡的訓練當中,神經網絡可能會因為各種各樣的問題,出現學習的效率不高,或者是因為干擾太多,學到最後並沒有很好的學到規律。而這其中的原因可能是多方面的,可能是數據問題,學習效率等參數問題。
Training and Test data:
為了檢驗,評價神經網絡,避免和改善這些問題,我們通常會把收集到的數據分為訓練數據和測試數據,一般用於訓練的數據可以是所有數據的70%,剩下的30%可以拿來測試學習結果。如果你想問為什麼要分開成兩批,那就想想我們讀書時的日子, 考試題和作業題大部分都是不一樣的。這也是同一個道理。
誤差曲線:
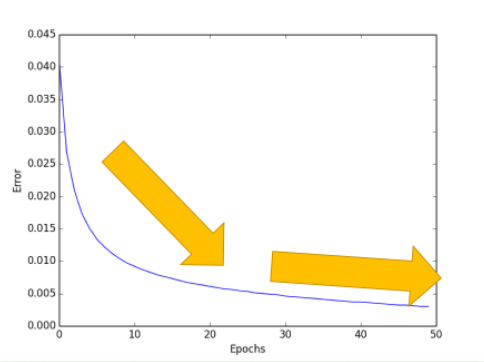
圖1 誤差曲線
對於神經網絡的評價基本上是基於這30%的測試數據,想想期末考試雖然花的時間少,但是佔得總成績肯定要比你平時作業的分多。所以說這30%雖然少,但是很重要,然後,我們就可以開始畫圖了。評價機器學習可以從誤差這個值開始,隨著訓練時間的變長,優秀的神經網絡能預測到更為精準的答案,預測誤差也會越少。到最後能夠提升的空間變小,曲線也趨於水平,從不及格到80分已經不容易,再往上沖刺到100分,就變成了更難的事了,機器學習也一樣。所以如果你的機器學習的誤差曲線是一條如圖1的曲線,那就已經是很不錯的學習成果。
準確度曲線:
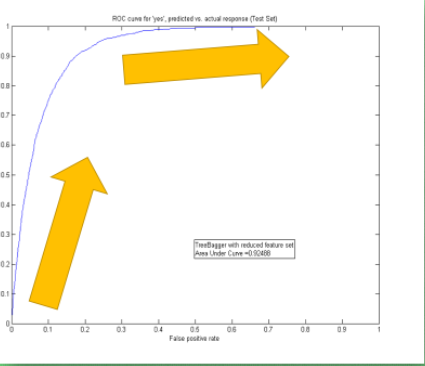
圖2 精確度曲線
同樣除了誤差曲線,我們可以看他的精確度曲線,最好的精度是趨向於100%精確。比如在神經網絡的分類問題中100個樣本,我有90張樣本分類正確,那就是說我的預測精確度是90%。不過不知道大家有沒有想過對於回歸的問題呢?怎樣看預測值是連續數字的精確度?這時我們可以引用R2 分數在測量回歸問題的精度,R2給出的最大精度也是100%,所以分類和回歸就都有的統一的精度標準。除了這些評分標準,我們還有很多其他的標準,比如F1 分數,用於測量不均衡數據的精度。
正規化:
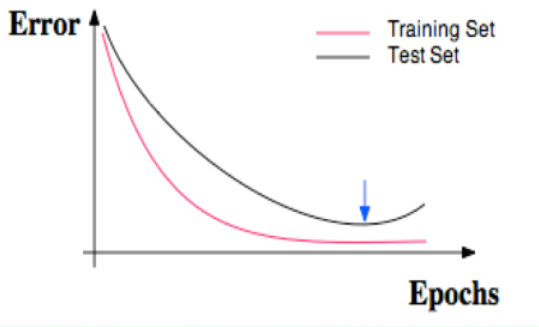
圖3 正規化曲線
比如有時候我們明明每一道作業習題都會做, 可是考試分數為什麼總是比作業分數低許多? 原來,我們只複習了作業題並沒有深入拓展研究作業反映出來的知識,這件事情發生在機器學習中,我們就叫做過擬合。我們在回到誤差曲線,不過這時我們也把訓練誤差畫出來,紅色的是訓練誤差,黑色的是測試誤差,訓練時的誤差比測試的誤差小,神經網絡雖然學習到了知識,但是對於平時作業太過依賴,到了考試的時候 卻不能隨機應變,沒有成功的把作業的知識擴展開來。在機器學習中,解決過擬合也有很多方法,比如l1、l2 正規化、dropout方法。
交叉驗證:
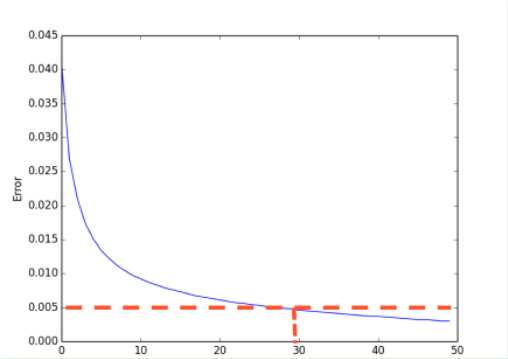
圖4 交叉驗證
神經網絡也有很多參數,我們怎麼確定哪樣的參數能夠更有效的解決現有的問題呢?這時交叉驗證就是最好的途徑。交叉驗證不僅僅可以用於神經網絡的調整參數,還能用於其他機器學習方法的調整參數。同樣是選擇你想觀看的誤差值或者是精確度,不過橫坐標不再是學習時間,而是你要測試的某一參數(比如說神經網絡層數),我們逐漸增加神經層,然後對於每一個不同層結構的神經網絡求出最終的誤差或精度,如圖4中,我們知道神經層越多計算機所需要消耗的時間和資源就越多,所以我們只需要找到那個能滿足誤差要求,有節約資源的層結構。比如說誤差在0.005以下都能接受,那我們就可以採用30層的神經網絡結構。
評論