

非監督學習簡單來說就是學習人類沒有標記過的數據。對於沒有標記的數據最常見的應用就是通過聚類(Clustering)的方式將數據進行分類。對於這些數據來說通常有非常多的維度或者說Features。如何降低這些數據的維度或者說“壓縮”數據,從而減輕模型學習的負擔,我們就要用到Autoencoder了。
而Autoencoder就是做資訊的壓縮,當在一層當中使用神經元愈多,可以儲存的資訊量也就愈多,相反的神經元越少,可以儲存的資訊量越少,如果要使用Neurel Network作資料壓縮的話,希望的是可以使用比原本更少的資訊量來儲存,其架構中可細分為 Encoder(編碼器)和 Decoder(解碼器)兩部分,它們分別做壓縮與解壓縮的動作,Autoencoder從輸入層到最中間層的數據處理過程叫做數據編碼(Encode)過程,從中間層到輸出層則為解碼(Decode)過程,最後保證輸出等於輸入。
AutoEncoder是如何工作?
AutoEncoder把數據作為輸入,將其編碼轉換為一個向量,並輸出看起來像輸入的數據。換句話說,它可以學習輸入中的模式,通過反向傳播,可以生成新的非常接近輸入數據的東西。
Autoencoder由2個主要部分:
- Encoder:模型在其中學習如何減小輸入尺寸並將輸入數據壓縮為編碼表示。
- Decoder:在該模型中,模型學習如何從編碼表示中重建數據,使其盡可能接近原始輸入。
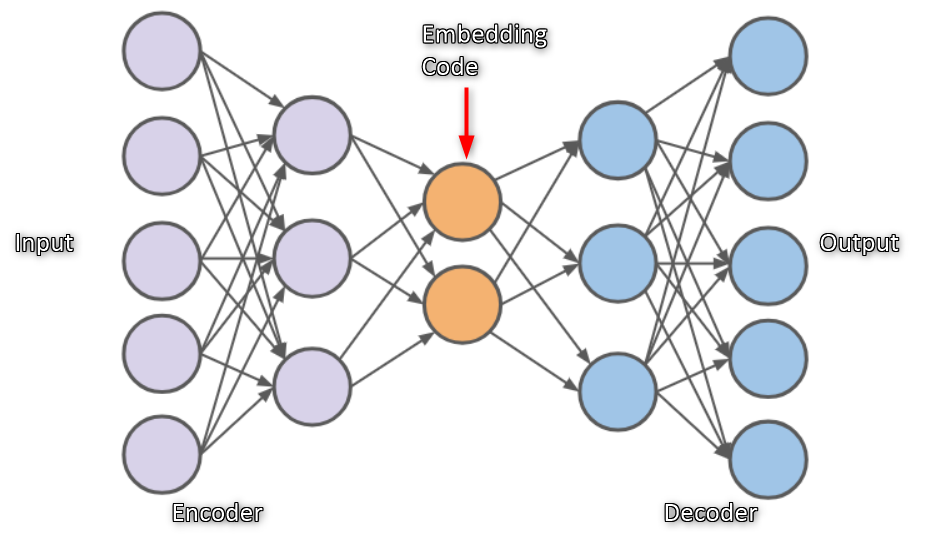
當然encoder是對輸入進行編碼生成一個向量表達,decoder負責基於該向量生成output。AutoEncoder的input與output的神經元數目是完全一致的。 Hidden Layer的神經元數目比較少,這樣可以使網絡提取到更重要的特徵,而不是將輸入直接複製到輸出裡如下圖1。
Autoencoder code:

圖2 定義參數
我們的MNIST數據,每張圖片大小是 28x28 pix,即 784 Features:

圖3 MNIST 數據
在壓縮環節:我們要把這個Features不斷壓縮,經過第一個隱藏層壓縮至256個 Features,再經過第二個隱藏層壓縮至128個。
在解壓環節:我們將128個Features還原至256個,再經過一步還原至784個。
在對比環節:比較原始數據與還原後的擁有 784 Features 的數據進行 cost 的對比,根據 cost 來提升我的 Autoencoder 的準確率,下圖是兩個隱藏層的 weights 和 biases 的定義:

圖4 兩個隱藏層Weights 和 biases定義
下面來定義 Encoder 和 Decoder ,使用的 Activation function 是 sigmoid, 壓縮之後的值應該在 [0,1] 這個範圍內。在 decoder 過程中,通常使用對應於 encoder 的 Activation function:

圖5 encoder and decoder 定義
來實現 Encoder 和 Decoder 輸出的結果:

圖6 定義Encoder and Decoder 輸出
再通過我們非監督學習進行對照,即對 “原始的有 784 Features 的數據集” 和 “通過 ‘Prediction’ 得出的有 784 Features 的數據集” 進行最小二乘法的計算,並且使 cost 最小化:

圖7 定義 loss and optimizer
最後,通過 Matplotlib 的 pyplot 模塊將結果顯示出來, 注意在輸出時MNIST數據集經過壓縮之後 x 的最大值是1,而非255:
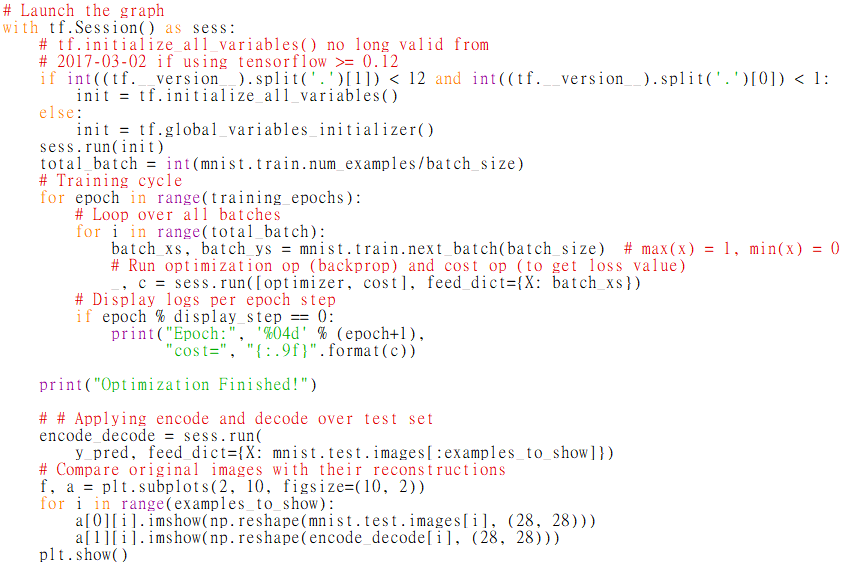
圖8 pyplot 模塊
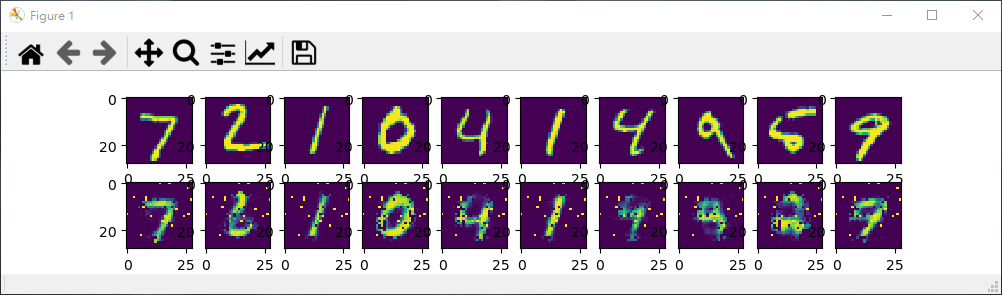
圖9 輸出結果
通過5個 Epoch 的訓練,(通常情況下,想要得到好的的效果,我們應進行10 ~ 20個 Epoch 的訓練)我們的結果如上,上面一行是真實數據,下面一行是經過 encoder 和 decoder 之後的數據,如果繼續進行訓練,效果會更好。
評論