

在TensorFlow首先要定義神經網絡的結構如圖1,然後再把資料放入結構當中去運算和訓練。
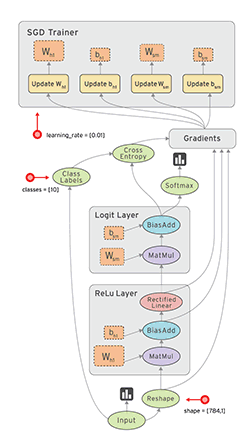
圖1 Tensorflow處理結構
因為TensorFlow是採用資料流程圖(data flow graphs)來計算,所以首先我們得創建一個資料流程圖,然後再將我們的資料(資料以張量(tensor)的形式存在)放在資料流程圖中計算。節點(節點)在圖1中表示數學操作,圖1中的線則表示在數組間相互聯繫的多維資料組,即張量(Tensor)。訓練模型時tensor會不斷的從資料流程圖中的一個流程圖流到另一節點,這就是TensorFlow名字的由來。
例子:
創建資料:
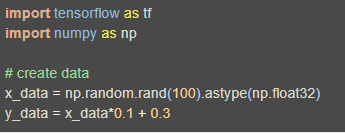
圖2創建資料
首先如圖2,我們這次需要加載tensorflow和numpy兩個模塊,並使用numpy來創建我們的資料,接著,我們用tf.Variable來創建描述y的參數。我們可以把y_data = x_data * 0.1 + 0.3想像成y =重量(Weights)* x +偏差(Biases),然後神經網絡也就是學著把重量變成0.1,偏差變成0.3
創建結構:

圖3創建結構
tf.Variable這代表創建變數。創建Weights是一個一維陣列的變數,而這個一維變數的數值為-1到1之間。再創建biases變數而初始化為零。再定義y = Weights * x_data + biases,而y是神經網路預測的值,則圖2的y_data是實際的值,Weights相當於圖2的0.1,biases相當於圖2的0.3。
計算誤差:

圖4計算誤差
接着就是計算圖3的y 和圖2的y_data的誤差。
反向傳遞誤差:

圖5反向傳遞誤差
反向傳遞誤差的工作就教給optimizer了,我們使用的誤差傳遞方法是梯度下降法:Gradient Descent讓我們使用優化器來進行參數的更新。
訓練:

圖6初始化變數
目前為止,我們只是建立了神經網絡的結構,還沒有使用這個結構。在使用這個結構之前,我們必須先初始化所有之前定義的變量,所以這一步是很重要的!
執行程式:

圖7執行程式
然後,我們再創建會話(session)。Session可以想像成一個指標,指向init來完成初始化。之後再指向train,開始訓練神經網路。

圖8執行結果
然後每二十步就會列印出結果如圖8。
機器學習其實就是讓電腦不斷的嘗試模擬已知的數據。他能知道自己模擬的數據離真實的數據差異有多遠,然後不斷地改進自己模擬的參數,提高模擬的相似度。
如果紅色曲線的表達式為:y = a * x + b其中x代表輸入,y代表輸出,a和b是神經網絡訓練的參數。模型訓練好了以後,a和b的值將會被確定,例如a = 0.5,b = 2,當我們再輸入x = 3時,我們的模型就會輸出0.5 * 3 + 2的結果。模型通過學習數據,獲得能表達數據的參數,然後對我們另外給的數據再做出的預測。
在圖9中藍色離散點是我們的數據點,黑色虛線是神經網路初始的模擬曲線,紅線是通過神經網絡算法模擬出來的曲線。
神經網絡在幹嘛呢?它是對我們資料點的一個近似表達。在開始階段如圖9,黑色虛線的表達能力不強,誤差很大。不過通過不斷的學習,預測誤差將會被降低。所以學習到後來。如圖9紅線也能近似表達出數據的樣子,這就是神經網路的工作了。
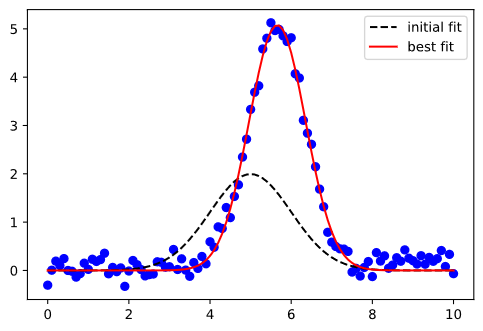
圖9 Fitting parameter

評論