

一,前言
在目前AI的運算處理器中,英特爾可以說是最齊全的了,所開發的OpenVino除了支援所有各式的CPU處理器提供給AI給各式平台來使用,英特爾更買下了 ALTERA, MOVIDIUS,並布局了雲端資料中心。要讓這些強大的硬體發揮效能,唯有提供相對應的軟體及函示庫可以讓開發商可以在其中得到最大效益。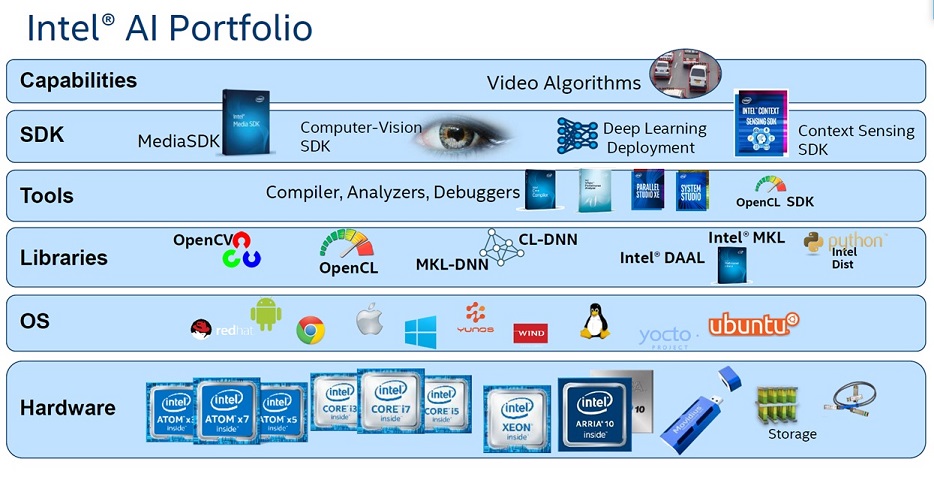
圖 1
另外INTEL針對HPC平台處理器所開發分析所使用的工具如Vtune各式開發工具,或是AI開發工具包 OpenVino 也都是能讓其硬體效能發揮極致所提供的軟體。 最後為了整個AI生態圈的建立,INTEL收購了俄羅斯的深度模型公司 Open Model Zoo.
做為INTEL新一代神經網絡加速卡,INTEL VPU, FPU支援OpenVino在windows, Ubuntu上面深度學習推論的加速,另外提供開源碼在非INTEL的平台上的支援。如下圖 2
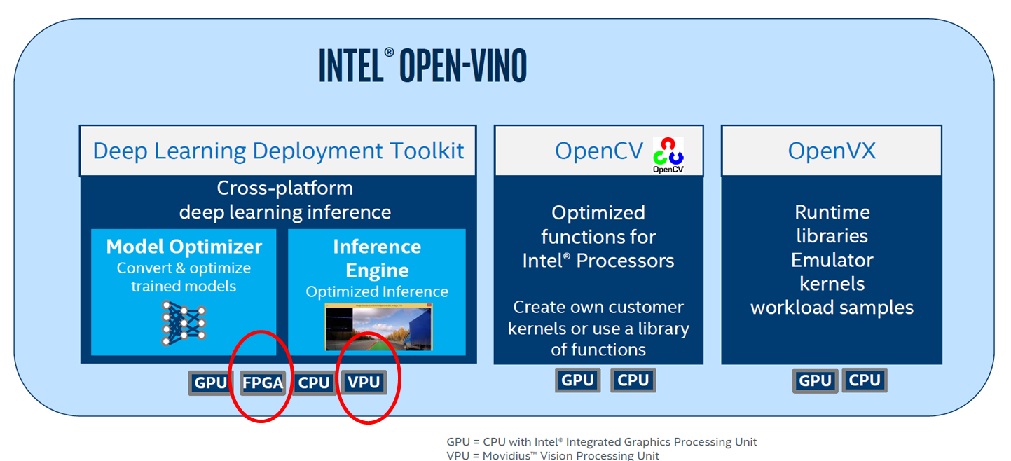
圖 2
二,OpenVino VPU 深度學習使用架構
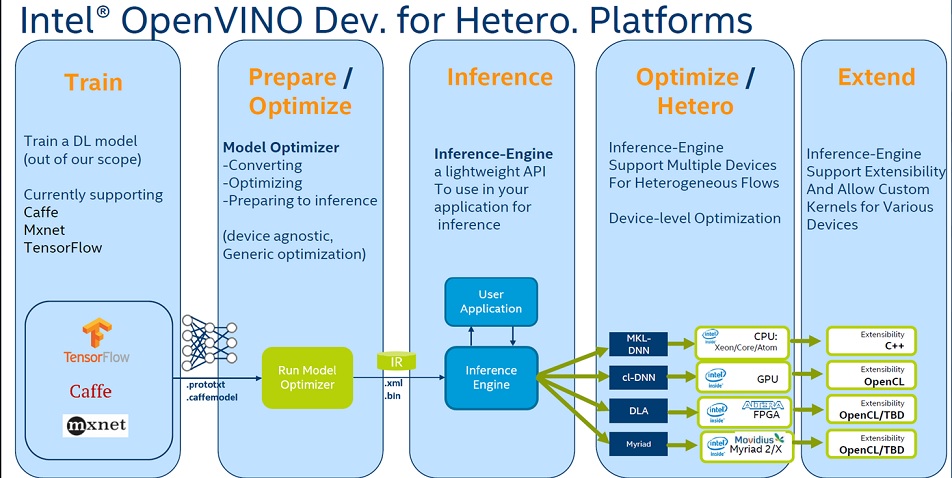
圖 3
事實上,客戶端應用程序可以無差別調用所有Intel的處理器來用(如圖3)。 最後沒支援的算法層,INTEL提供OpenCL的開放source code來加入新的算法到Pretrained Model, 並讓OpenVino認得並多線程的來讓處理器可以平行處來該算法層。
INTEL VPU支援算法層如下圖4, 並隨時登入OpenVino官網來更新支援的算法層。由圖表可看出,FPGA支援的算法層相較於其他處理器為少。基本上速度越快的處理器如 FPGA,客製化程度用高,因此需要針對算法加速客製化。 支援客製化的 layer因開發時程較慢,所以當前需要開發HETERO. PLUGIN,來解決因某些算法因尚未支援而讓新出算法無法支援的遺憾。 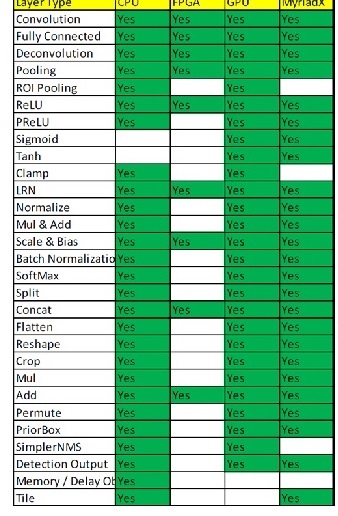
圖 4
除了要注意支援的算法另一個要注意的就是支援的資料格式
圖五
以上列表為各類型INTEL 處理器支援的資料格格式,依表格所示,MYRIAD VPU目前支援FP16運算格式,FPGA 支援為FP16, FP11 資料格式。通常剛剛接觸OpenVino的使用者遇到的問題,不會注意到資料格式,以致在使用NCS2誤使用了FP32資料格式而發生推論範例無法運作的錯誤。
三,神經運算棒 (NCS2) 加速卡原理及應用

圖七
上圖為INTEL VPU Movidius Myriad X 的技術資料。根據官方資料,Myriad X 容許支援兩路camera的輸入,加上低功耗(<兩瓦/ vpu), >1TOP運算量,CP值相當的高,適合支援嵌入式系統產品落地應用。但基於嵌入式設計的應用,所使用的深度模型需要小於50MB大小,並小於3 GMACS的複雜度(GMACS: 等於每秒10億(=10^9)次的定點乘累加運算)
另外如果搭配Movidius MDK 來開發Myriad X則可以利用內建硬體的加速的算法函式庫來做深度學習前的預處理(pre-processing),配合16顆VLIW SHAVE Cores及 CNN engine, 可以把算力提升至4 TFLOP的速度。唯目前使用MDK開發 MYRIAD X需要投入相當資源,目前INTEL會收取NRE費用後以專案處理。
英特爾Movidius 神經運算棒售價约为 79 美元,支持人工智能邊緣運算(非雲端運算)

圖八
目前NCS2支援使用OpenVino來做推論,通常用於算法驗證或是算力的驗證之用。落地時再選用INTEL VAD(vision accleration design) L1 (VPUx1)來使用。
NCS 2 使用16顆 VLIW shave(Streaming Hybrid Architecture Vector Engine) cores 來處理神經網絡運算。VLIW 全名為 Very Long Instruction Word, 可使用SIMD (Single Instruction multiple words)方式運行在向量處理器上 (Vector Engine)做平行運算。而NCS2的16顆 shave cores就是向量處理器的一種。下圖九為Movidius 單顆的架構圖。
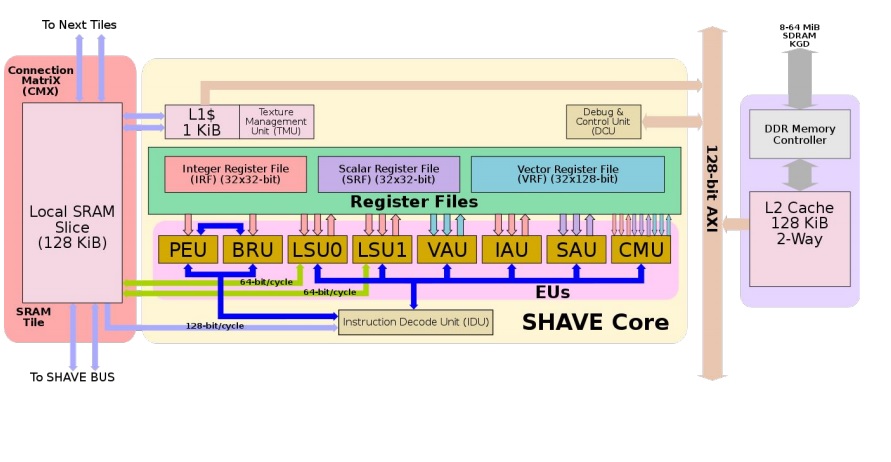
圖九
下圖所示為每顆SHAVE CORE中八個平行運算單元及特性
- 混合RISC-DSP-GPU VLIW架構
- 20 GFLOPS計算能力
- 180 MHz
- At 300 mW
- Predicated execution
- Branch delay slots
- 針對流式工作負載量身定制
- 128位向量算術
- 8/16/32-bit integer
- 16/32-bit floating point
- 完全支持稀疏數據結構(矩陣/數組,隨機訪問)

在架構上,SHAVE的組織方式與IBM的CELL架構類似。有獨立的SHAVE核心,這一代最多可以連接8個核心。核心受益於最近的兩個鄰居的零懲罰,這是建築的內在屬性,本質上有利於大多數代碼。該芯片具有由所有內核共享的L2緩存以及集成的DDR2內存控制器,該控制器連接到封裝的KGD堆疊芯片,範圍從8到64 MiB的SDRAM。
大量外圍設備連接到芯片的參數,該參數通過AXI總線與內核通信。這些外圍設備包括支持高速率的兩個高分辨率相機(高達1200萬像素)和高分辨率LCD控制器。各種外設可以通過封裝中有限數量的I/O引腳進行軟件復用。整體管理控制器核心是可綜合的SPARC V8 LEON3。
平行運算單元的架構特性如下
大量端口的多個寄存器文件,以便一次操作相對較大的一組值。 每個SHAVE核心都駐留在一個獨立的電力島上。雖然我們無法對此進行驗證,但可能您可以通過軟件根據電源要求啟用和禁用核心。
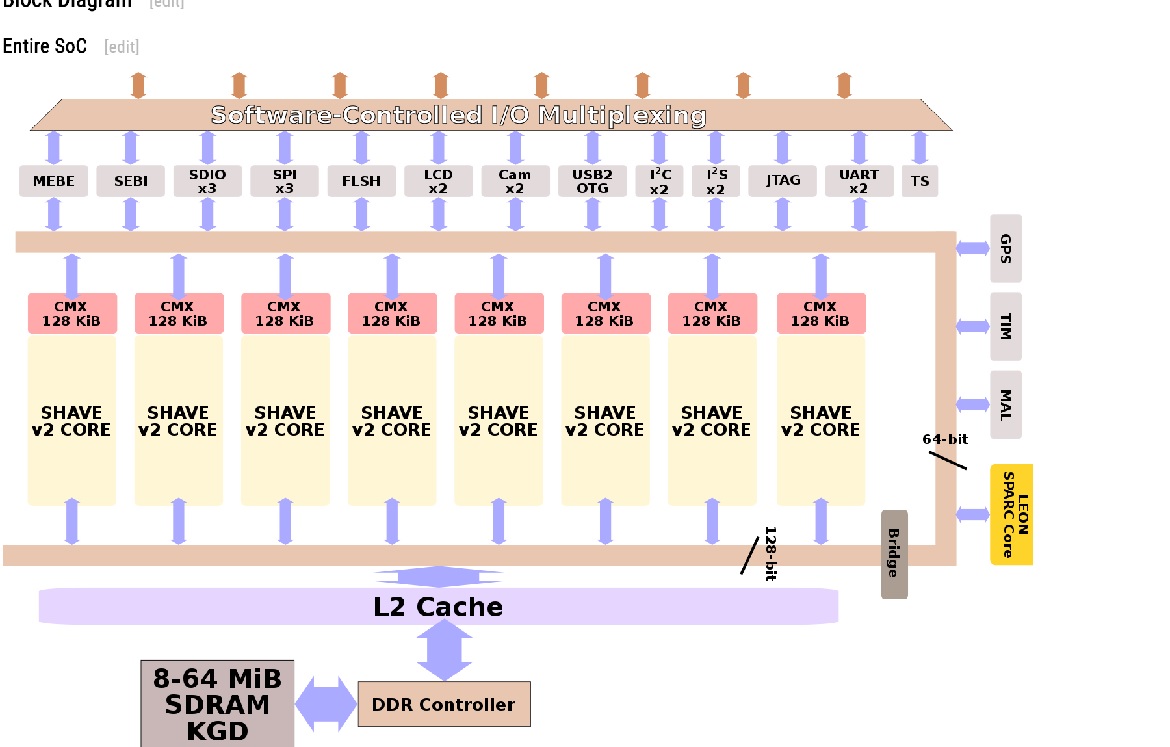
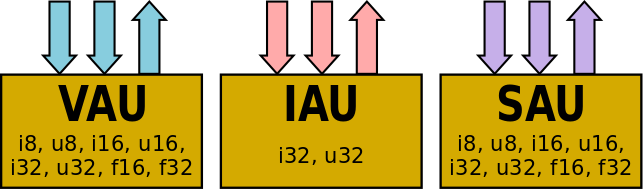
以執行這兩種操作的組合,以便進行各種類似DSP的操作,例如矩陣切換。
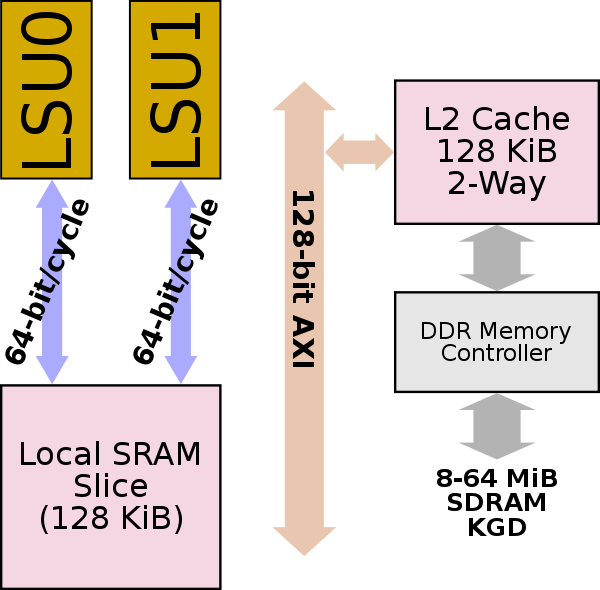
每個SHAVE內核都有一個本地128 KiB的SRAM片段,LSU在Movidius上操作調用Connection MatriX(CMX)塊。緩存在指令和數據之間分配。確切的數量是軟件可配置的,粒度為8 KiB間隔。每個本地緩存區塊直接鏈接到其最近的兩個鄰居(可能是位於西部和東部的核心),允許來自那些存儲體的零懲罰訪問。對於位於更遠位置的緩存切片,確實會有輕微的延遲懲罰。 Movidius指出,他們測試的大多數軟件幾乎都與其相鄰核心進行了通信,從而可以利用這一點。 整個芯片還具有共享128 KiB的L2緩存和集成的DDR2內存控制器,該控制器連接到封裝的堆疊式8-64 MiB SDRAM。
參考資料
1. OpenVINO源碼:
https://github.com/opencv/dldt
2. NCS2:
https://ncsforum.movidius.com/discussion/1302/intel-neural-compute-stick-2-information
3. OpenVINO與Movidius SDK的區別:
https://www.xianjichina.com/news/details_80102.html
4. SHAVE v2.0 - Microarchitectures - Movidius
https://en.wikichip.org/wiki/movidius/microarchitectures/shave_v2.0#Process_Technology
5. 大大購購買神經運算棒
https://www.wpgdadago.com/ProductList?do=query&queryMap.RESULT=Y&queryMap.InStock=N&queryMap.CurrentCurr=N&queryMap.M_PARTNO=NCSM2485.DK,964486
評論